





计算机视觉与数字艺术实验室
计算机视觉与数学艺术实验室由王亦洲教授于2007年创立,专注于借鉴认知神经科学和心理学研究的证据,发展计算视觉理论、模型与方法,解决计算机视觉中的挑战性问题。我们的主要目标是通过建立坚实的数学基础,从计算的角度理解人类视觉感知、认知、学习及更多的有效机制。另外,我们也相信,科学与艺术的结合将会在视觉模式的创意表达上激发出令人兴奋的灵感。
实验室成员

实验室代表成果
1. 主动视觉与多智能体强化学习
(1)3D虚拟环境中的主动目标跟踪
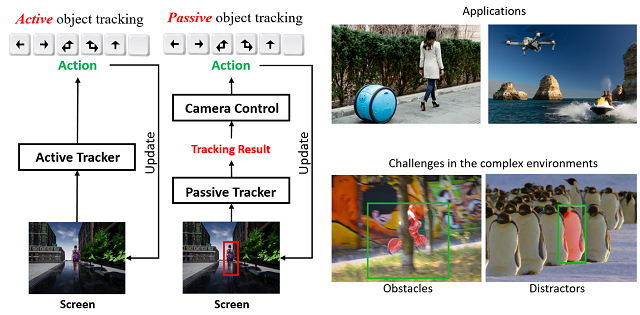
我们首次提出了基于强化学习的端到端主动目标跟踪方法,即跟踪者可以根据原始的视觉观测信息来产生对应的用于主动移动摄像头的控制信号,从而实现对目标进行精确的追踪。为解决该方法的泛化能力问题,我们在训练过程中采用了先进的环境增强技术, 进而实现从虚拟到现实的迁移。
(2)基于非对称对抗机制的主动目标跟踪算法
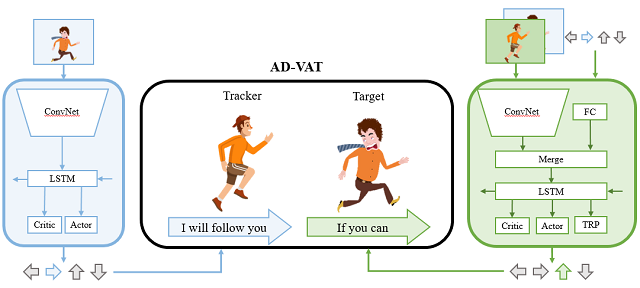
我们提出了一种基于对抗博弈的强化学习框架用于主动视觉跟踪的训练,称之为AD-VAT(Asymmetric Dueling mechanism for learning Visual Active Tracking)。在这个训练机制中,跟踪器和目标物体被视作一对正在“决斗”的对手,也就是跟踪器要尽量跟随目标,而目标要想办法脱离跟踪。这种竞争机制,使得他们在相互挑战对方的同时相互促进共同提升。
(3)基于成对智能体门阈值通信机制的多目标主动搜索方法

鉴于单智能体主动目标搜索方法的不足,我们在深度Q网络中引入了实现智能体间两两通信的门阈值机制,使得智能体能够自主学习何时通信以及传递何种消息。相比于单智能体方法,我们的多智能体算法有了很大提升,同时也在实验中表现出了多种有意义的协同策略。
(4)基于高效主从通信结构的多智能体强化学习方法
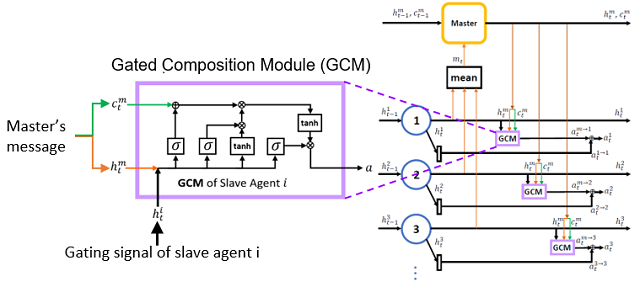
针对大规模多智能体任务中通信量幂级数增长以及通信效率低下的难题,我们提出了一种高效的主从多智能体通信结构,通过引入独立的主智能体(Master)帮助从智能体(Slave)之间实现高效的信息共享以及更优的协作策略的学习,从而相比已有多智能体强化学习方法有了很大提升。我们在极具挑战性的星际争霸微操作任务上测试了该算法,取得了领先的性能。
2. 视觉任务中语义信息的挖掘与利用
(1)基于单帧图像或视频序列的鲁棒3D人体姿态估计算法
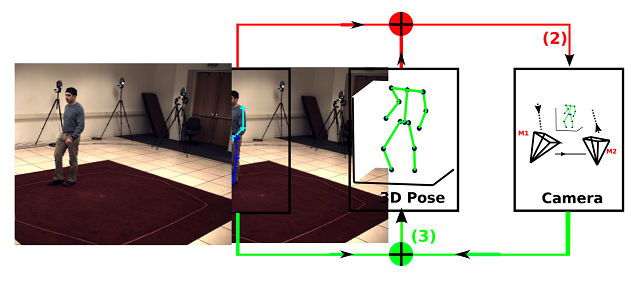
我们提出了一种新型的从单帧图像或视频序列来估计3D人体姿态的方法。通过引入L1范数来衡量2D姿态与3D姿态之间的误差,该方法对于2D姿态的错误敏感度较低。基于由此产生的候选3D姿态,我们还将该方法拓展到视频序列中,通过增加一个时序平滑限制条件来筛选出最优的3D姿态。相比已有方法,我们的算法得到了15%的性能提升。
(2)基于位置敏感嵌入特征的视频目标分割方法
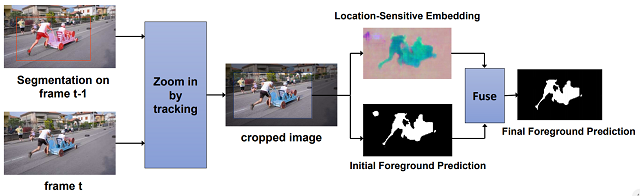
传统的视频中物体分割的方法要求在视频的第一帧上有目标物体精确的像素级别的标注。然而在实际使用中,获得这种像素级别的标注是一件费时费力的事情。对此,我们提出了一种新的解决方案,只使用目标物体在第一帧上的包围框作为监督信息,我们的模型就可以产生目标物体在整个视频上的精确分割结果。在这个任务中存在两个主要的挑战:一是背景中可能包含和目标外观相似的其他物体;二是目标物体的外观随着时间的流逝可能会产生巨大的改变。为了解决这些挑战,我们提出了一个端到端的模型来为每一个像素学习位置敏感的嵌入,这些嵌入向量能够帮助分辨外表相似但空间位置不同的多个物体。为了解决外观变化的挑战,我们提出了一种鲁棒的模型更新方法,首先用预训练的模型扫描整个视频,产生前景和背景的伪标注,然后使用伪标注来更新我们的模型。在DAVIS数据集和Segtrack v2数据集上的实验表明我们的方法优于现有的其他视频物体分割的方法。
(3)注意机制驱动的无参照图像质量评价方法
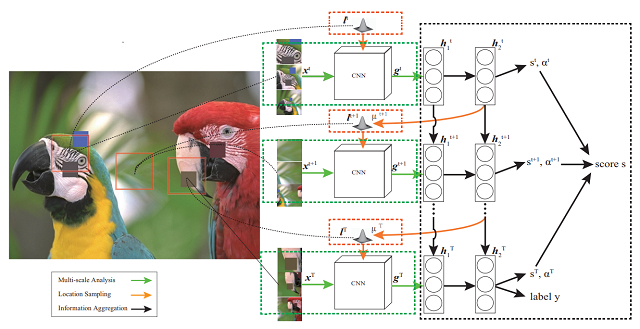
我们提出了一种新型的无参照图像质量评价方法,在无参照图像质量评价中首次引入动态视觉注意机制。我们假设图像中的视觉注意区域包含评价图像质量所需的关键信息,并采用强化学习来学习动态注意机制。我们的方法能够提供鲁棒、高效的质量评价指标。同时,我们还引入了多任务学习机制,使得所学习的模型的特征表示和泛化能力更强。
(4)基于时空上下文学习的视频异常行为检测方法
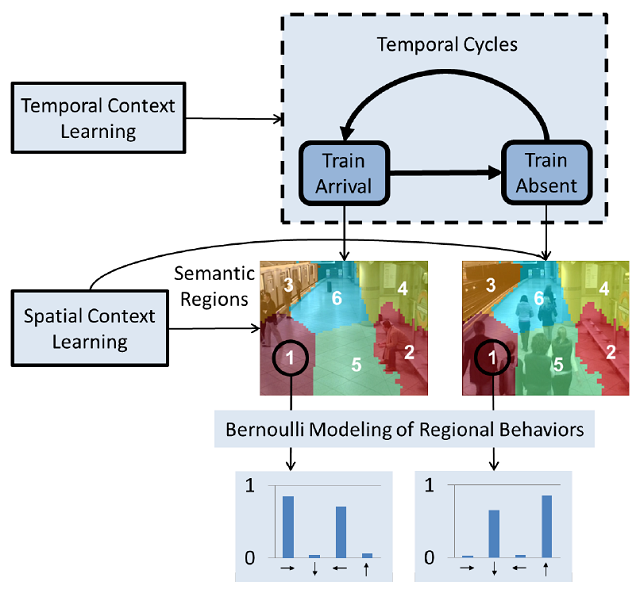
我们针对复杂场景监控视频中的语义关联信息,提出了一种有效的时空上下文学习方法,基于简单的二值化特征表示,即可实现准确、实时的异常事件检测效果。
(5)基于端对端卷积网络与3D模型融合方法的人脸检测
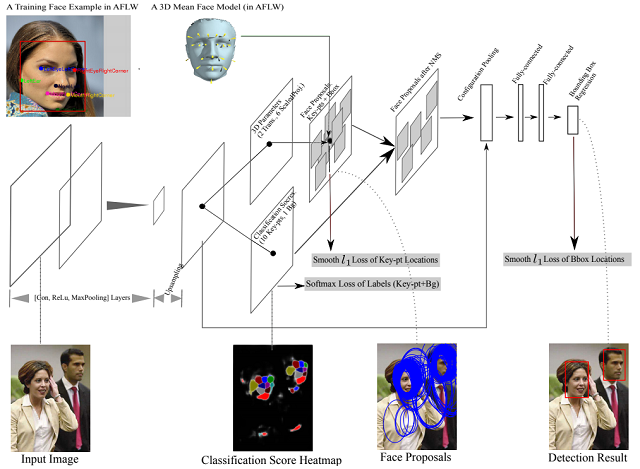
人脸检测在很多视觉任务中都被作为核心模块使用,但其现在仍有许多未解决的问题。人脸在诸如视角,遮挡,表情,光照等因素的影响下会发生很大的变化。我们提出了一种多任务的端对端神经网络框架,该框架融合了卷积网络与3D平均脸模型。所提出的模型主要包含两个部分:(i) 人脸候选模块,其通过估计人脸关键点以及人脸的视角变化(旋转与位移)参数以提出人脸的候选集。 (ii) 人脸验证模块,通过检测到的人脸关键点以及基于关键点的结构池化对人脸候选集进行筛选与调整。
3. 医学视觉信息处理
(1)肺结节分割、征象和良恶性预测的联合学习方法
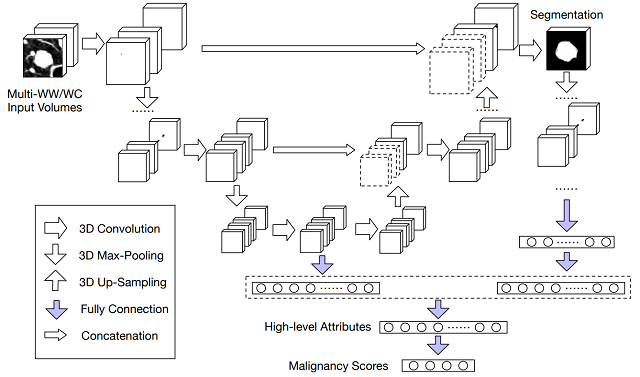
我们提出了一种可解释的多任务学习CNN框架,同时对肺结节分割、征象和良恶性预测任务进行学习。这种方法不仅能准确地预测肺结节的良恶性,也能提供高层语义特征以及检测的结节区域。
(2)神经图像中异性质特征的经验贝叶斯识别方法

针对已有方法对病变特征与谬误特征不同性质的忽视,我们提出了一种针对两类特征的经验贝叶斯方法FDR-HS((False-Discovery-Rate Heterogenous Smoothing)。这种方法不仅能够避免多同线性问题的影响,也能充分利用异性质特征间的空间模式特点。另外,通过引入隐含变量,该方法很容易被转化为一个凸优化问题,从而可使用EM算法简单求解。我们在艾滋海默症数据集ADNI上进行了测试,证实了该方法更好的可解释性和预测性能。
(3)基于级联生成式与判别式学习的乳腺钼靶微钙化检测
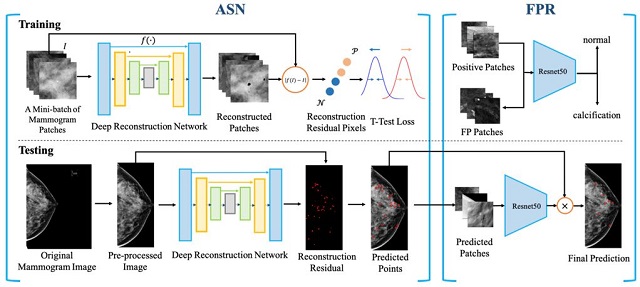
钙化点的出现是乳腺癌最重要的征象之一,而形态不同的钙化簇、肿块都以早期的钙化点不断发育聚集而成。由于钙化点形状不规律,且相对于非钙化样本数量较少,因此,我们可以将这一问题转化为有监督的异常检测问题,即将钙化点作为异常点。基于这个先验知识,我们试图拟合正常样本图像,而将钙化点当成异常点并试图将这部分检测出来。为此,我们提出了连续的生成和判别学习框架,主要分为两步:第一步是异常分离网络(Anomaly Seperation Network,ASN),借助重构网络强大的表示能力和T-test损失函数来帮助我们将正负样本分开;第二步是假阳性消除(False Positive Reduction,FPR),来消除不属于钙化但形态上具有异常的区域,比如血管钙化、锯齿钙化等。
(4)高效的广义稀疏集成模型及其应用
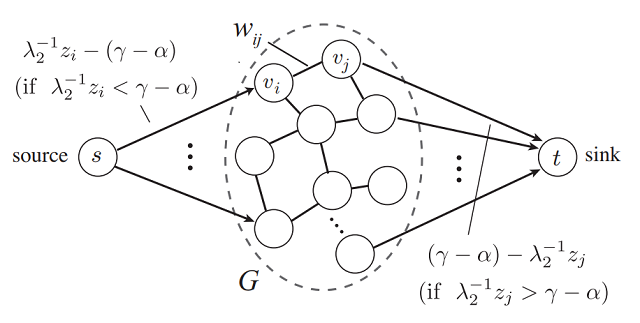
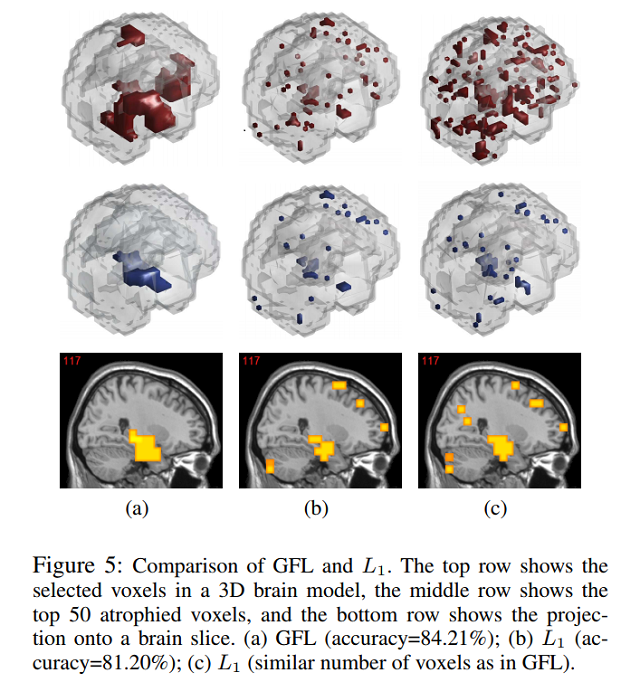
广义稀疏集成模型(GFL,Generalized fused lasso)通过惩罚变量及其成对差异的L1范数来进行学习,已经在具有图结构稀疏特性的各种问题中获得了广泛应用。但高昂的计算代价使得GFL难以应用到高维问题中。由此,我们提出了一种快速且尺度可控的GFL算法,并证明了GFL问题与图割问题的等价性。该方法被应用到艾滋海默症的病变区域分割中,在标准数据集上取得了领先的准确度。上图右侧给出了(a)GFL方法的结果(b)(c)不同参数下普通L1稀疏方法的效果。
(5)GSplit LBI:一种利用神经影像学引入的过程偏差来提升预测能力的迭代算法
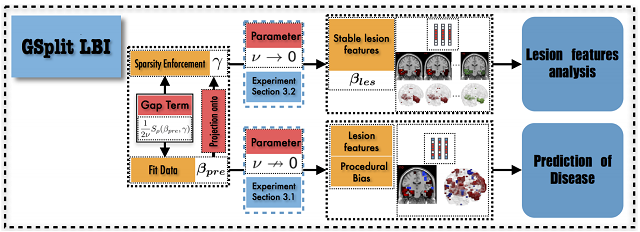
我们发现在神经影像学疾病分析中,除了受损特征外,还有另一类特征也能帮助疾病分类,由于这一类特征是在前处理过程中引入,因此我们称为过程偏差。本文提出GSplit LBI算法,来将这一类特征捕捉,从而提升分类准确率和可解释性。在ADNI数据的实验表明,该方法可以在MRI模态的数据中取得state-of-the-art的结果。