






王亦洲课题组 ICML 2024入选论文解读:大语言模型如何表征不同信念?
在纷繁复杂的社交互动中,能够洞察他人心理状态(如信念、愿望、意图等)——并理解这些心理状态可能与我们自己的不同——是人类社会交往的一项基本而复杂的技能,在心理学中被称为“心智理论”(Theory of Mind,ToM)。那么,大语言模型(Large Language Model,LLM)是否也能区分他人和自己的心理状态?这将如何影响它们的社交推理能力?
这篇发表于机器学习顶会 ICML 2024 的研究论文 Language Models Represent Beliefs of Self and Others 深入探索了这些问题。该研究由北京大学王亦洲教授研究团队完成,学生作者包括博士生朱文韬和本科实习生张芷宁,展示了一个分析大语言模型心智理论能力的全新视角和一些有趣的观察。
论文链接:https://arxiv.org/pdf/2402.18496
开源代码:https://github.com/Walter0807/RepBelief
项目主页:https://walter0807.github.io/RepBelief/

图1. 我们发现大语言模型(LLM)内部具有能解码自己和他人心理状态的神经表征,而定向引导这些表征可以显著影响它们的心智理论(ToM)推理能力。
01 背景介绍
开发能够以类似人类的方式进行复杂社会推理和互动的机器系统是人工智能领域的一个重要目标。这个问题的核心是这些系统必须拥有“心智理论”(Theory of Mind, ToM)的能力,这涉及识别和归因于自我和他人的心理状态——如信念、愿望、意图和情感等,同时承认他人可能拥有与自己不同的心理状态[1,2]。这种基础能力不仅对于理解人类的行为交互至关重要,也使得机器能够在不同的社会环境中与其他智能体进行合作、适应、乃至产生同理心[3,4]。
近期大语言模型领域的巨大进展似乎是实现这一目标的有希望的方法。一些研究表明 LLM 表现出合理的心智理论能力[5,6]。这些研究表明 LLM 能够在一定程度上预测和理解人类的意图和信念,从而展示了社会推理的基础水平。与此同时,一些其他研究发现这些能力往往是肤浅和脆弱的[7,8,9,10]。批评者认为,尽管 LLM 可能模仿出理解社会环境和心理状态的外在表现,但这种表现可能并不是源自与人类心智类似的深刻、真正的理解。相反,它可能仅仅反映了模型复制其训练数据中观察到的模式的能力。
这些观察凸显了我们对 LLM 社会推理能力的理解存在一个关键的空白。在简单的黑箱测试之外,有一系列仍未得到解答的重要问题,例如,LLM 是否具备对他人心理状态的内部表征?这些表征是否能够区分他人的心理状态和自己的心理状态?它们如何影响 LLM 的社交推理能力?解决这些问题不仅有助于我们更深入地了解 LLM 如何理解他人的心理状态,而且对于 AI 系统的可信度(Trustworthiness)和对齐(Alignment)也具有意义。
在本研究中,我们发现可以通过 LLM 内部的神经激活来线性解码不同智能体视角下的信念状态,这表明模型内部存在关于自我和他人信念的表征。通过定向引导这些表征,我们观察到模型的心智理论推理能力上发生了显著的变化,体现了这些表征在社交推理过程中的关键作用。此外,我们的发现对涉及不同因果推理模式的多样化社会推理任务适用,表明这些表征的潜在泛化性。
02 探测信念表征

图2. 左侧:一个“真实信念(True Belief)”故事,其中主角与旁观者持有相同的信念。右侧:一个“虚假信念(False Belief)”故事,其中主角与旁观者持有不同的信念。对于每组两个故事,我们分别将它们与两个信念连接起来,直接输入到模型中。
通过给大语言模型输入一组故事和信念陈述,我们使用自注意力头的神经激活来尝试解码故事中不同视角下的信念状态。我们主要关注两个视角:故事的主角(Protagonist)和一个上帝视角下全知的旁观者(Oracle)。我们在 Mistral-7B-Instruct 各层的各个自注意力头上分别训练了不同视角的预测器和联合预测器,并展示他们在验证集上的准确率:
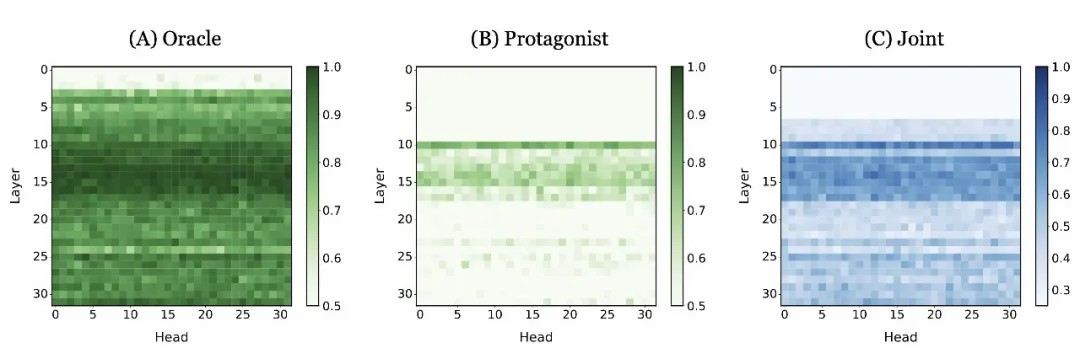
图3. 基于 Mistral-7B 所有层的注意力头激活的探测准确率。(A) 使用逻辑回归(二元)对旁观者的信念状态估计。(B) 使用逻辑回归(二元)对主角的信念状态估计。(C) 使用多项逻辑回归(四元)对两个视角的联合信念状态估计。
我们发现,即使使用简单的线性回归,也能从特定的注意力头、中单独或共同解码两个视角下的信念状态。值得注意的是,代表全知旁观者信念(对应 LLM 自身)的激活头比代表主角信念的更多。这个现象或许也能够解释其在心智理论经典的虚假信念测试中的不足表现。我们还进一步在低维空间中可视化了不同注意力头空间中的线性决策边界:
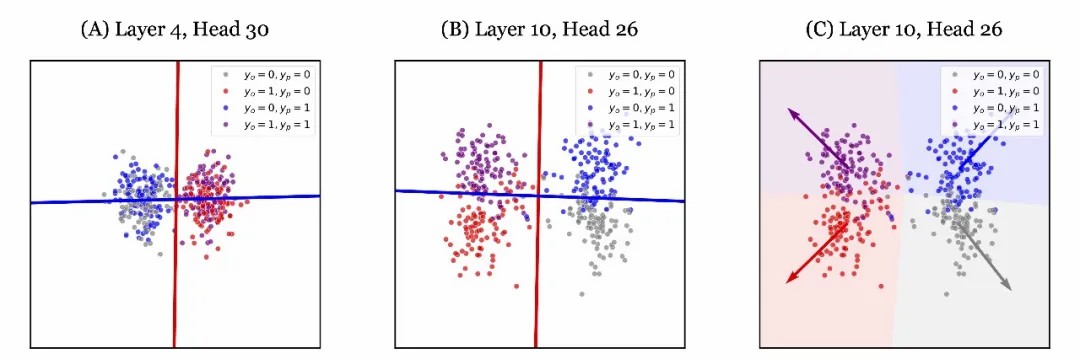
图4. 在 (A) 中,旁观者的信念状态可以通过线性模型区分,而主角则不能。红线和蓝线分别代表旁观者和主角的线性决策边界;在 (B) 中,旁观者和主角的信念状态都可以通过线性模型准确建模;(C) 进一步展示了使用多项线性回归模型进行联合信念状态估计的决策边界,箭头指示了每个类别的探测权重方向。
03 引导信念表征
尽管探测结果支持了注意力头激活空间中存在针对不同代理的信念表征,但这些表征是否真正有助于整体社会推理过程仍未可知。在本节,我们将通过显式地引导这些表征来探索它们在功能上的角色。为此,我们设计了一系列实验,旨在回答以下几个问题:我们能否通过引导内部表征来改变语言模型的社会推理能力?如果可以,该如何实现?这样的做法对不同类型的社会推理任务会产生什么影响?
我们发现,通过将特定注意力头的神经激活朝着通过多项逻辑回归发现的信念方向偏移,能够显著影响模型的心智理论推理能力;而作为对照,随机方向的偏移则变化甚微。
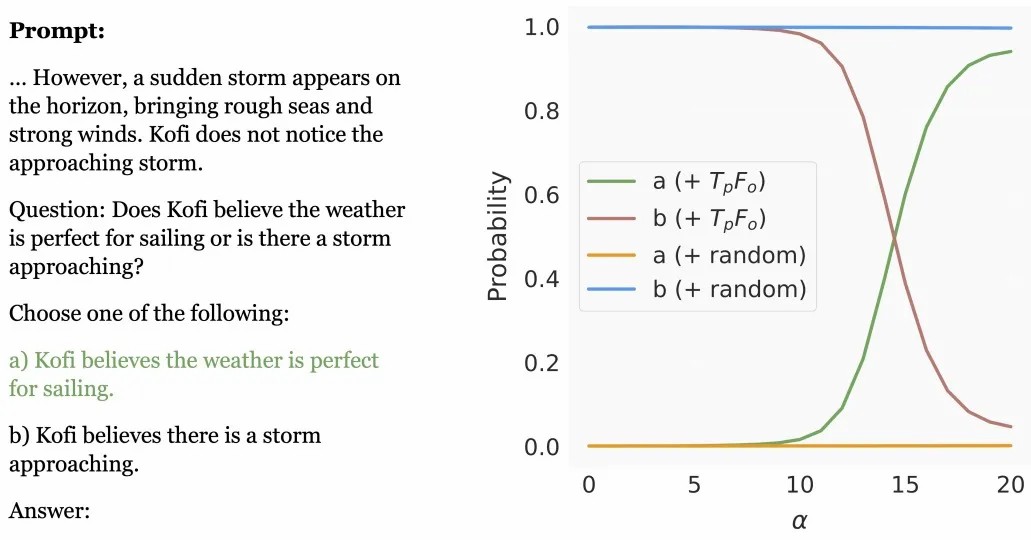
图5. 左侧:虚假信念条件下的问题提示。为简化起见,省略了故事背景。右侧:在 Mistral-7B 上,不同偏移程度 α 下的下一词概率的变化。
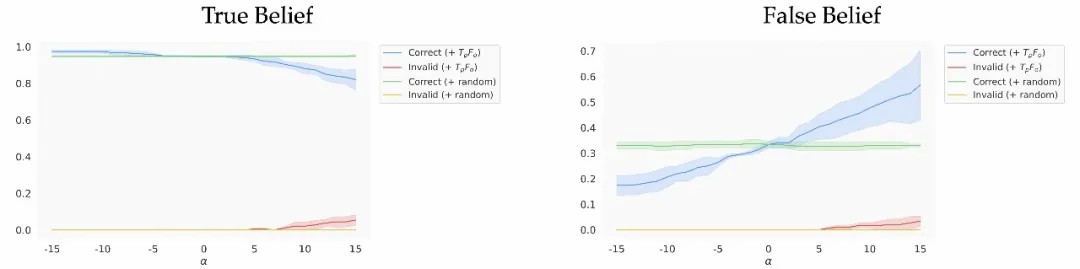
图6. 不同偏移程度 α 下 Mistral-7B-Instruct 在前向信念推理(Forward Belief)任务中的准确率。
关于更多的定量测试结果和对不同因果推理模式的泛化性研究,请参阅论文原文。
04 解读信念表征
通过探测和引导实验,我们发现自注意力头的激活空间中存在可泛化的信念表征方向。为了更直观地理解这些方向的含义,我们进一步探究了哪些输入标记(Token)与发现的表征方向最相关,我们将各注意力头的神经激活投影到表征方向上,并反向传播到输入标记的嵌入空间。
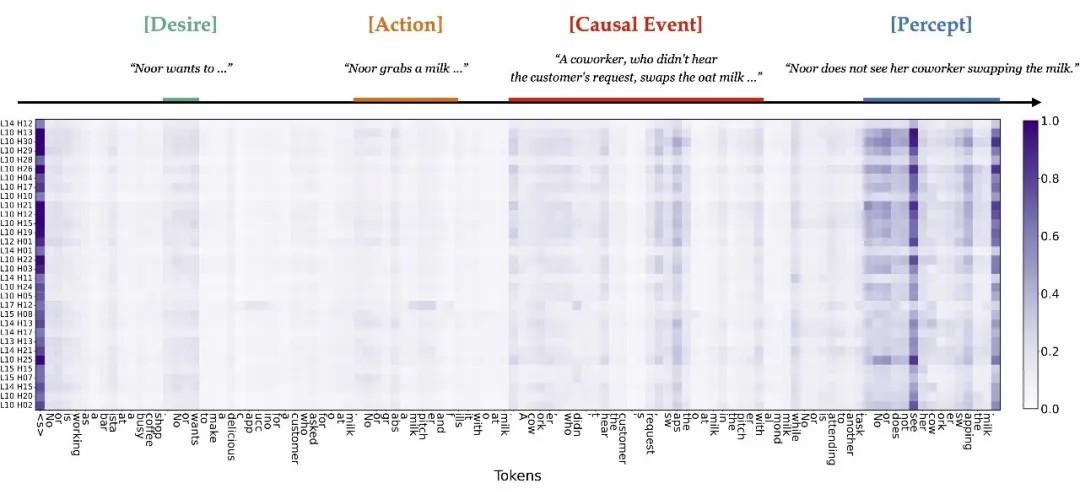
图7. 相应联合信念方向上注意力头激活的投影对标记嵌入的梯度大小,每行代表 Mistral-7B- Instruct 中的一个特定注意力头。我们突出显示了显著的部分和相应的因果变量。
我们发现这些方向能够精准定位到提示中的关键因果变量,包括主角的愿望(Desire)、初始行动(Action)、改变环境状态的因果事件(Causal Event)以及主角对因果事件的感知状态(Percept),而正是这些元素共同促成了对两个视角下信念的全面推理。这些观察结果也能够解释我们发现的信念表征方向在不同社会推理任务中的泛化性。
05 总 结
在这项研究中,我们发现 LLM 能够通过内部神经表征线性地区分多个视角下的不同信念状态。此外,我们证实对这些表征的定向引导能够显著地影响模型的社会推理表现。最后,我们展示了在多种社会推理任务场景中内部信念表征的泛化能力。
我们的研究为持续进行的有关 LLM 心智理论推理能力的讨论贡献了新见解,提供了关于它们通过内部表征进行心智模拟的能力的可能证据。展望未来,我们的研究为进一步的调查开辟了道路,包括在训练期间信念表征的产生,它们在更复杂的 LLM 中的可扩展性,以及提高机器 ToM 能力并与人类价值观对齐的方法等。
参考文献
[1] Leslie, A. M. Pretense and representation: The origins of "theory of mind." Psychological review, 94(4):412, 1987.
[2] Wellman, H. M., Cross, D., and Watson, J. Meta-analysis of theory-of-mind development: The truth about false belief. Child development, 72(3):655–684, 2001.
[3] Kleiman-Weiner, M., Ho, M. K., Austerweil, J. L., Littman, M. L., and Tenenbaum, J. B. Coordinate to cooperate or compete: abstract goals and joint intentions in social interaction. In CogSci, 2016.
[4] Rabinowitz, N., Perbet, F., Song, F., Zhang, C., Eslami, S. A., and Botvinick, M. Machine theory of mind. In ICML, 2018.
[5] Kosinski, M. Theory of mind may have spontaneously emerged in large language models. arXiv preprint arXiv:2302.02083, 2023.
[6] Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
[7] Shapira, N., Levy, M., Alavi, S. H., Zhou, X., Choi, Y., Goldberg, Y., Sap, M., and Shwartz, V. Clever hans or neural theory of mind? stress testing social reasoning in large language models. arXiv preprint arXiv:2305.14763, 2023.
[8] Ullman, T. Large language models fail on trivial alterations to theory-of-mind tasks. arXiv preprint arXiv:2302.08399, 2023.
[9] Ma, X., Gao, L., and Xu, Q. Tomchallenges: A principleguided dataset and diverse evaluation tasks for exploring theory of mind. arXiv preprint arXiv:2305.15068, 2023.
[10] Verma, M., Bhambri, S., and Kambhampati, S. Theory of mind abilities of large language models in human-robot interaction: An illusion? arXiv preprint arXiv:2401.05302, 2024.