






王鹤课题组 CVPR 2024 入选论文解读:基于掩码聚类的高精度开放词汇三维实例分割
本文是 CVPR 2024 入选论文 MaskClustering: View Consensus based Mask Graph Clustering for Open-Vocabulary 3D Instance Segmentation 的解读。本论文由北京大学王鹤研究团队与北京智源研究院、北京银河通用公司合作,提出了简单易用、高效、精准的开放词汇三维实例分割算法。本文利用成熟的二维实例分割模型,结合三维多视角验证,提出了一套基于图聚类的三维分割算法。该算法无需任何训练,即可在常用数据集 ScanNet++[1],ScanNet[2],MatterPort3D[3]上取得了远超前人工作的精度。
论文链接:https://arxiv.org/abs/2401.07745
项目主页:https://pku-epic.github.io/MaskClustering
代码地址:https://github.com/PKU-EPIC/MaskClustering
图1. MatterPort3D 场景上的效果展示图,不同颜色代表不同实例。可以看到,本算法可以鲁棒地分割出场景中各种细小物体,如沙发上的衣服、墙上的画、柜台上的罐子等。
图2. 真实货架场景中的分割效果图。通过将本算法与 3D Gaussian Splatting[7]相结合,我们成功实现了高精度的货架分割。即便是前后交错、紧密堆叠的药盒,也能被清晰准确地分割出来。
01 引 言
开放词汇的三维实例分割指,在已重建好的三维场景点云中,分割出其中的所有三维实例,而不依赖于预定义的类别列表。这一任务对于机器人、AR/VR 领域都有着重要价值。然而,由于缺乏大规模的细粒度三维实例标注,这一领域的发展受到极大阻碍。另一方面,二维实例分割在最近取得重大突破,表现出近乎完美的细粒度分割能力。因此,一个自然的想法是,利用二维实例分割模型来提升三维实例分割的能力。为了实现这一想法,一个直观的方案即,如图3所示,利用二维模型在该场景的 RGB-D 序列上进行推理,然后再利用相机位姿反投影后,聚合到三维点云上。
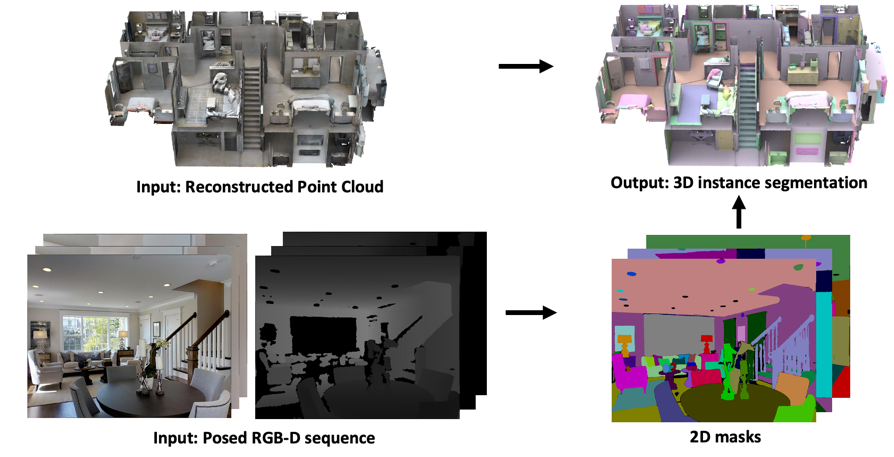
图3. 利用二维实例分割模型来提升三维分割的框架图。
这一方案的核心难点在于,二维模型的输出在不同帧之间是不一致的。如图4所示,同一架钢琴在不同帧的二维实例分割中,尽管 mask 分割无误,但物体 ID 并不对应,因此,本文的核心在于建立不同帧的二维 mask ID 对应关系。前人的工作 OVIR-3D[6]和 SAM3D[9]探索了用 mask 之间的几何相交程度来决定是否对应,取得了初步效果。但这类方法仅仅利用了两帧的信息,因此没有展现出足够的鲁棒性。相比之下,本文借鉴经典的三维视觉算法 Bundle Adjustment[10],利用整段观测序列进行多帧之间的相互验证,从而提升全局一致性。

图4. 二维实例分割模型在不同帧的输出 ID 不一致。
具体来说,本文提出了一个新的指标,view consensus rate,来衡量两个 mask 是否属于同一个三维物体。若该指标足够高,则这两个 mask 属于同一个物体,应该被合并。为了充分利用多帧观测,该指标被定义为,整段观测序列中支持这两个 mask 合并的支持率。对于任意一帧,若这两个 mask 均出现,且它们在该帧中被包含于同一个该帧的二维 mask,则该帧支持其合并。相较于前人利用相邻帧计算出的指标,view consensus rate 充分利用多帧间的相互验证,提高了鲁棒性。
更进一步的,本文以序列中所有的二维 mask 为节点,构建全局 mask graph。当两个 mask 之间的 view consensus rate 高于阈值时,在它们之间添加一条边,代表它们可能属于同一物体。本文利用经典的图聚类算法,迭代地将可能属于同一个物体的 mask 聚为同一类。这一过程中,全局图的构建与迭代聚类进一步增强了全局一致性,减少了噪声对算法的干扰。
经过在 ScanNet++、Matterport3D 和 ScanNet200 数据集上的详细验证,本文提出的算法在零样本的开放词汇实例分割、无类别实例分割两个赛道上都取得了最先进的结果,展现出优越的细粒度分割能力。
02 方法简介
首先,我们介绍 view consensus rate 的计算。如图5所示,对于两个二维分割得到的 mask m1 和 m2,我们将其反投影,得到对应点云 P1 和 P2。随后,我们找出整段观测序列中所有观测到红、蓝两个点云的帧。
图5. 将二维 mask 反投影为点云并得到其观测帧。
如图6所示,对于序列中的每一帧,我们逐帧检查:若红、蓝两个点云均在该帧可见,则该帧参与投票,否则弃权(图6的第4帧)。若这两个点云均落在该帧的同一个二维 mask 内,则表明二维模型在该帧内支持红、蓝两个点云的合并,该帧投赞成票(图6的第1、2帧);若这两个点云分别落在该帧的不同的二维 mask 内,则表明二维模型在该帧内反对红、蓝两个点云的合并,该帧投反对票(图6的第3帧)。最终,计算得到的支持率即为这两个 mask 的 view consensus rate。
图6. 对于每个观测帧,计算其是否投票及是否支持。对于第1、2、3帧,红、蓝两个点云都可见,因此参与投票。第1、2帧中,这两个点云被包含在同一个 mask 内,因此支持其合并;第3帧中,这两个点云被包含在不同 mask 内,因此反对。得到支持率为2/3。
基于上述 view consensus rate,我们定义了全局的 mask graph,以进一步提升全局一致性。本算法的整体流程如下:首先,对于观测序列中每一帧,我们利用二维模型得到该帧所有的 mask。随后,我们将整段序列中所有的 mask 取出,以它们为节点,构建全局的 mask graph。对于每两个 mask,我们计算其 view consensus rate,若大于阈值,则在它们之间连边。在该图内,我们利用经典的 graph clustering 算法,迭代式地将连边的 mask 聚为同一 cluster。每轮迭代中,考虑到 view consensus rate 的计算时,参与投票的观测者(即分母)数量越多,计算的结果越可靠,因此我们在该轮 clustering 中优先合并它们。每轮迭代后,我们重新计算每个新节点与其他节点的 view consensus rate,并以此进行下一轮迭代。最终,我们得到若干 cluster,每个 cluster 代表一个三维物体。该物体的点云即为该 cluster 中所有二维 mask 对应点云的并集。
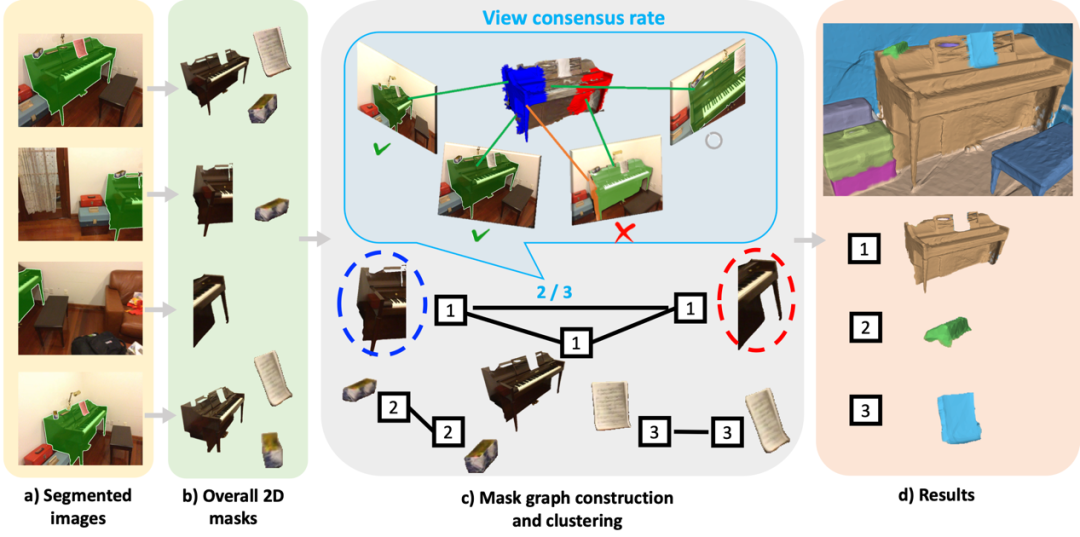
图7. 算法流程图。为了便于阅读,仅可视化了三个物体。
实际算法中,我们对 view consensus rate 计算的中间结果进行存储,并利用空间换时间的方式加速,使得整个算法在单个房间内的耗时大约在3-5分钟(包含二维分割模型的推理时间)。此外,我们也利用多帧检验的方式,筛除了一部分欠分割的二维 mask,进一步提升算法的鲁棒性。
03 实验结果
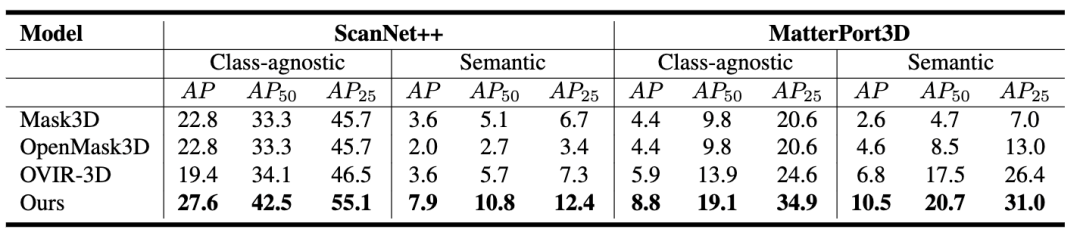
在两个常用三维场景数据集 ScanNet++ 和 MatterPort3D 上,本文对所有方法进行了 zero-shot 测试。除了语义实例分割中常用的 Average Precision(AP)指标,本文还额外提供了 class-agnostic 的 AP 指标,不考虑语义标签正确性,更好地对比 mask 本身的质量。相较于在 ScanNet 数据集上训练的 Mask3D[4]算法,利用 CLIP 获得开放语义的 OpenMask3D[5]算法和同样采用二维融合到三维的 OVIR-3D[6] 算法,我们的算法在这两个数据集的所有指标上都比前人的工作有了3-10个点的大幅精度提升。

视觉效果上,我们的算法可以精准地分割各种彼此相邻的小物体,比如上图中的矿泉水瓶、桌上的杂物、架子上的小物件等等。即使是数据集标注都未能将这些物体分割出来,由此可见本算法在分割粒度上的提升。

此外,我们的算法也支持开放词汇的物体检索。上图中我们绘制了每个物体的语义特征和输入文本的相似度,由蓝到黄对应相似度由0到1。可以看到,同一场景内不同形状、颜色、内容的物体都可以被清晰的选中。
04 总 结
本文提出了一个简单易用、高效、精准的开放词汇三维实例分割算法。通过结合二维实例分割模型与三维多视角验证,本文利用掩码聚类的方式融合二维输出,得到三维实例。在三个常用数据集和一个真实场景上,我们的算法在数值、视觉效果上取得了远超之前工作的精度。目前代码已开源,欢迎大家试用、指正!
参考文献
[1] Yeshwanth, Chandan, et al. "Scannet++: A high-fidelity dataset of 3d indoor scenes." ICCV 2023.
[2] Dai, Angela, et al. "Scannet: Richly-annotated 3d reconstructions of indoor scenes." CVPR 2017.
[3] Chang, Angel, et al. "Matterport3D: Learning from RGB-D Data in Indoor Environments." 3DV 2017.
[4] Schult, Jonas, et al. "Mask3d: Mask transformer for 3d semantic instance segmentation." ICRA 2023.
[5] Takmaz, Ayca, et al. "OpenMask3D: Open-Vocabulary 3D Instance Segmentation." NeruIPS 2023.
[6] Lu, Shiyang, et al. "Ovir-3d: Open-vocabulary 3d instance retrieval without training on 3d data." Conference on Robot Learning 2023.
[7] Kerbl, Bernhard, et al. "3d gaussian splatting for real-time radiance field rendering." ACM Transactions on Graphics 42.4 (2023): 1-14.
[8] Lu, Qi, et al. "High-Quality Entity Segmentation." ICCV 2023.
[9] Yang, Yunhan, et al. "Sam3d: Segment anything in 3d scenes." arXiv preprint arXiv:2306.03908 (2023).
[10] Triggs, Bill, et al. "Bundle adjustment—a modern synthesis." Workshop on Vision Algorithms 1999.