






董豪课题组 ICRA 2024 入选论文解读:RGBManip:仅基于单目RGB相机的机器人自主环境感知和操纵
本文是发表于 ICRA2024 的论文 RGBManip: Monocular Image-based Robotic Manipulation through Active Object Pose Estimation 的解读,该论文由北京大学董豪和香港中文大学窦琪联合团队完成。学界解决机器人操纵任务往往依赖于带有深度信息的环境感知,如使用深度相机捕捉物体的三维坐标。然而,能否仅用一个 RGB 相机让机器人自主感知环境并完成操纵任务?本文在这个问题上给出了肯定的答案。
论文链接:https://arxiv.org/abs/2310.03478
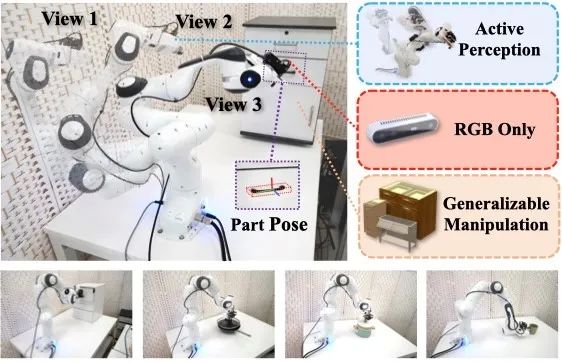
图1. 本文介绍的工作使用单 RGB 相机完成主动感知和对物体的操纵。
01 背 景
环境感知在几乎所有机器人任务中都是极其重要的一环。机器人需要对环境中的物体、障碍等各项因素有着精确的建模:以抓取一个马克杯为例,除了知道马克杯的位置还不够,要想成功地拿起马克杯,机器人还需要了解把手的朝向。在各项机器人任务中,学界获得这些精确信息的方式主要依赖于深度相机,相比于普通相机,深度相机可以额外获得每个像素到相机的距离,通过投影变换即可得知图片中每个像素点在空间中的三维坐标。而这种三维信息成为了解决各项机器人任务的关键,根据这些信息便可以计算出各个物体的位置、朝向,障碍的分布等,在此基础上机器人才能完成各项任务。如果缺失了深度相机带来的第三维信息,单纯依赖一张二维的图片,上述这些信息无从得知,因此各项机器人任务将无法开展。
深度相机在可以获得深度这一关键信息的同时,根据原理的不同,普遍有着一些致命的弱点。基于视差的深度相机在纹理特征缺失或重复的物体上可能会无法计算深度,且精度有限;基于光飞行时间和结构光法的深度相机无法处理全反射或透明的物体。单一视角的深度图像还会无可避免的受到物体自遮挡的影响。
这篇工作的出发点就是:在环境感知层面使用普通的 RGB 单目相机固定在机械臂末端来代替深度相机,通过训练基于强化学习的决策模型,让机器人在完成操纵任务的同时,主动地从各个视角进行观测并获得精确的物体三维信息,最终解决操纵任务。
02 主动多视角姿态估计
如何利用单目相机获得足够的三维信息呢?我们采用了最简单的方案:从多个视角来观察物体,并融合各个视角的信息。单一视角的图片只能确定物体位置的两个自由度,而物体的远近和大小是无法确定的。而拥有两个视角的信息便能完全还原出物体位置的三个自由度。
这种方案可以用简单的一句话来描述:假设我们已知两个视角 A 和 B,并且已知视角 A 下的像素 a 和视角 B 下的像素 b 属于物体的同一个部分,那么分别沿着两个视角做像素 a,b 的延长线,两延长线的焦点便是物体对应部分在空间中的位置。
当然,实际情况会复杂一些。对于某一类操纵任务,涉及到的物体虽然属于同一类,但可能存在多样化的外形,比如大小不一形状各异的马克杯,这给我们的位姿估计算法带来了很大的挑战,因为每个像素属于物体的哪个部分是未知的。

图2. 前两行为预测的物体位姿,第三行为预测的每个像素所属的部位,第四行为真实环境中做的测试。
在我们的工作中给出的解决办法是:
- 通过机器人的动力学状态可以计算出每个视角在空间中的坐标和朝向;
- 对每个视角用机器学习的方法预测出每个像素在物体上所属的部位,作为一种特征;
- 将两个视角的每个像素的特征分别投影到多个预先设定好的平面上做合并;
- 利用合并后的特征预测物体的位姿。

图3. 利用合并后的特征预测物体的位姿。
如图3所示,将机器学习与最直观的想法结合,我们得到了一种非常精确的多视角位姿估计算法。
03 全局决策
机器人操纵任务可以解偶成三个部分:全局决策(Global Scheduling Policy)、姿态估计(Active Perception Module)和末端执行(Manipulation Module)。这三者的关系类似于人的脑、眼和手。全局决策模块(脑)的作用是根据当前机器人的状态和任务目标,决定以何种姿态观测物体可以获得更准确的估计、并决定何时执行完成操作的动作。姿态估计模块(眼)的作用则是依靠各个视角的观测结果来生成尽可能准确的物体位姿。物体的位姿最终会服务于末端执行模块(手)来完成操作,具体如图4所示。
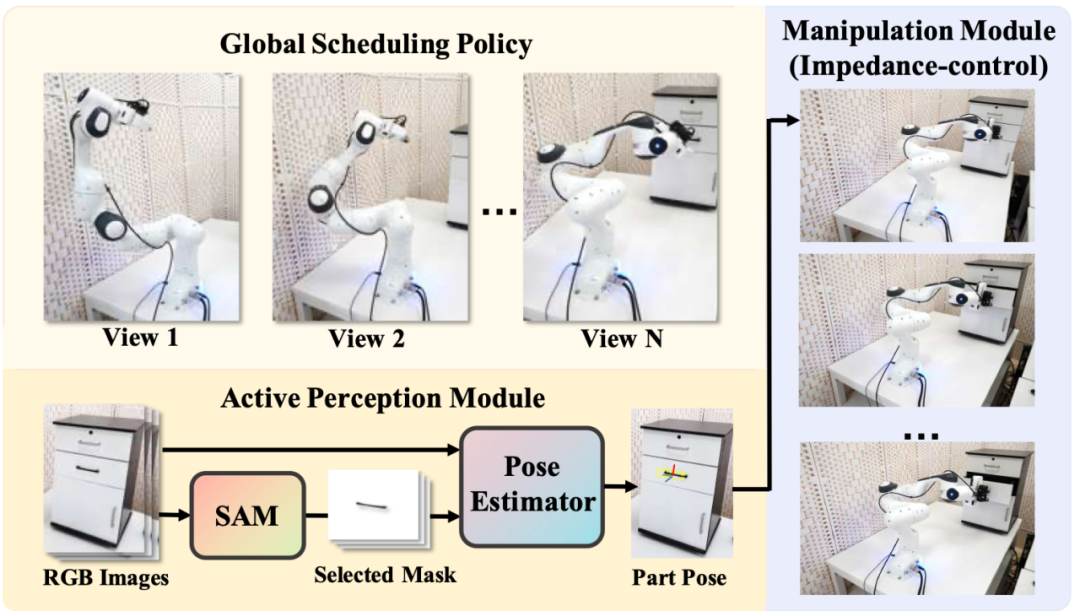
图4. 该工作将机器人操纵任务解耦成全局决策、姿态估计和末端执行三个模块,每个模块的任务如图所示。
如果用于位姿估计的视角越多、视角间差异越大,越有可能获得更好的估计结果,但是相应的执行时间也会增加。因此全局决策模块不光需要优化视角来获得更好的位姿估计,还需要优化执行的时间。在这样的复杂的优化问题的情景下,我们使用强化学习来寻找最优的策略,避免了复杂的参数化。
04 末端执行
前面介绍的位姿估计和全局决策模块最终都服务于操纵任务的完成。在人完成操纵任务的时候,往往需要肉眼的实时介入,调整手的动作,但是这在我们的机器人任务中并不现实:由于我们的相机固定在机械臂的末端,在完成任务的过程中,由于过于接近物体,往往会无法获得足够的全局信息。比如在开门的过程中无法从视觉角度得知门的开合角度。因此我们采用了类似于“盲人摸象”的做法,通过捕捉机械臂末端的力反馈来动态调整施加到机械臂末端的力矩,流畅地完成各类动作。具体来说,我们可以用阻抗控制将机械臂的末端模拟成一个带阻尼的线性谐振子,使得机械臂末端在自然状态下会趋向于平衡位置。而通过机械臂真实位置和平衡位置之间的差异就能计算出机械臂受到的外力。只需要根据外力来实时修正平衡位置,就能引导着机械臂完成特定的操作任务,而无需视觉的参与。

图5. 使用基于阻抗控制的末端执行算法在真实世界完成操纵任务。
05 训练和测试
训练流程分为两个阶段:首先采集数据用于位姿估计模块的训练,然后在模拟器内基于训练好的位姿估计模块来训练全局决策模块。末端执行模块无需训练。

表1. 在6个任务上对该算法和基线算法进行了比较,同时在其中的四个任务上对该工作的不同模块做了消融实验。
实验数据表明我们的方法在多个任务上都打败了所有基线算法。