董豪课题组 ICRA 2024 入选论文解读:基于RGB空间的通用导航技能,无缝衔接大模型的感知规划能力
本文是对发表于 ICRA 2024的论文 Bridging Zero-shot Object Navigation and Foundation Models through Pixel-Guided Navigation Skill 的解读。该论文由北京大学董豪超平面实验室完成,第一作者为访问学生蔡文哲。
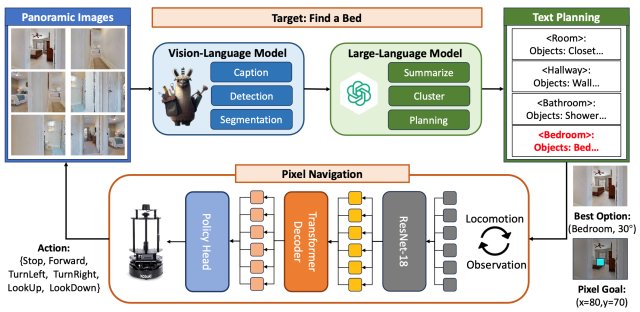
本文提出了一种通用的视觉导航技能 PixelNav,此项技能以像素点而非坐标点作为导航目标,实现了一种具有泛化性的基于 RGB 输入的路径规划方法;PixelNav 以像素作为目标的建模方式无缝衔接现有大模型在 RGB 图片上感知与推理能力,以此技能为基础,本文设计了一种基于大模型的规划流程,实现了不依赖与定位建图的开放词域物品导航(Open-Vocabulary Object Navigation)系统。
论文链接:https://www.arxiv.org/abs/2309.10309
项目主页:https://sites.google.com/view/pixnav/
PixelNav 通过弥补大模型感知与传统导航方法输入上的模态(图片vs地图)差异,释放出大模型在物体导航问题上的规划能力。
开放词域物品导航(Open-Vocabulary Object Navigation)是家庭服务场景中机器人需要具备的一项基础能力,此任务考验机器人在未知场景中,面对多样化物体时的感知能力,以及针对不同目标物体时的搜索策略。针对前者,互联网海量的数据集已赋予基座模型强大的多模态感知能力;针对后者,尽管大模型具备室内场景物体摆放习惯的先验知识,但是这类高层文字上的理解无法直接翻译成底层机器人行动的轨迹,这带来了实现此类导航系统的挑战。
目前,大多数方法采用基于建图的方法实现开放词域物品导航,但是由于现有的大模型并不能直接理解地图形式的输入,此类方法往往有选择性的将地图某些区域翻译成文字,进而发挥出大模型的常识理解与推理能力。在这一过程中,从原始 RGB 观测-建图-文字损失了大量的细节信息,不利于大模型实现更精准的规划。
为了克服这类方法的问题,本文跳出基于建图的框架,提出了一种通用的 RGB 导航技能 PixelNav,此技能以指定像素位置作为导航目标,建立端到端网络学习从当前位置到像素目标对应坐标的移动轨迹。PixelNav 可无缝衔接多模态大模型的能力,实现任意类别物体的导航过程。
01 基于像素目标的导航技能PixelNav
为了建立适用于任意物体的端到端导航策略, PixelNav 以像素作为导航目标,由于任何一个物体都可以用像素来提示其所在的空间相对位置,这将多模态的策略网络转换成为单模态策略网络,降低了训练的难度;并且一张图片往往包含着成千上万个像素点,像素本身的数据多样性是容易保证的,从而降低了数据采集的难度。在网络的具体实现中,PixelNav 首先将目标像素位置与 RGB 图像转换为4通道的图片,并利用 ResNet 网络进行特征提取获得目标 token。随后将导航轨迹中每一时刻观测得到的 RGB 图片利用另外一个 ResNet 网络进行特征提取获得观测 token。将目标token与每一时刻观测 token 输入到四层的 Transformer Decoder 中解码进行最优动作的计算。此处动作被规定为六种离散动作,分别包括前进0.25米,左转/右转30°,抬头/低头30°以及停止。为了加速网络的训练并提升 PixelNav 导航技能的泛化性,此处引入了两个额外的优化目标,分别是目标像素追踪以及时序距离预测。目标像素追踪用于预测标记的目标像素在后续时刻图像中的位置,时序距离预测用于判定当前位置距离完成目标还需要多少次行动。这两项目标都有助于提升策略网络对于三维空间的理解。三项优化目标参考如下:
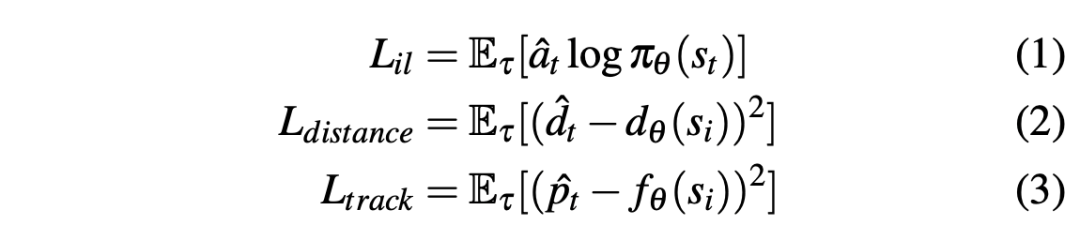
02 基于大模型的感知与规划
本文基于已有的大模型建立了适用于物体导航任务的像素目标规划器,其主要由两部分构成,第一部分使用多模态模型提取多个视角图像中的语义信息以及物体线索,这包括了 Image Caption,Object Detection 以及 Segmentation 三个步骤。第二部分则是设计高效的 Prompt 激发 LLM 的导航推理能力。为此,本文基于多模态模型 Image Caption 的结果利用 LLM 进行归纳总结,得到 room-level 的局部拓扑关系。基于此结构化的文本表示,LLM 能够依据其具备的先验知识进行房间类型与目标物体之间的相关性判断,并以此为依据进行规划。例如当导航目标是寻找床,那么 LLM 就会把卧室作为此次规划的目标,如果局部拓扑图中不存在卧室,那么 LLM 也能够推理出某些连接区域(如走廊等)更有可能连接到卧室,因此以走廊作为规划的目标。规划好房间后,此房间地板区域分割 mask 的中心点将作为目标 Pixel 输入下层策略实现底层的运动。整个流程如下图所示。
03 实验结果
物体导航实验是在 Habitat-Lab 仿真器中基于 HM3D 数据集进行测试的。实验结果表明,在不依赖于建图模块的加持下,基于 RGB 空间下的 PixelNav 方法能在开放词域物体导航任务中取得与基于建图的前沿方法(ESC)获得持平的性能,并极大的超过了已有的纯RGB输入下的导航方法(ZSON)。

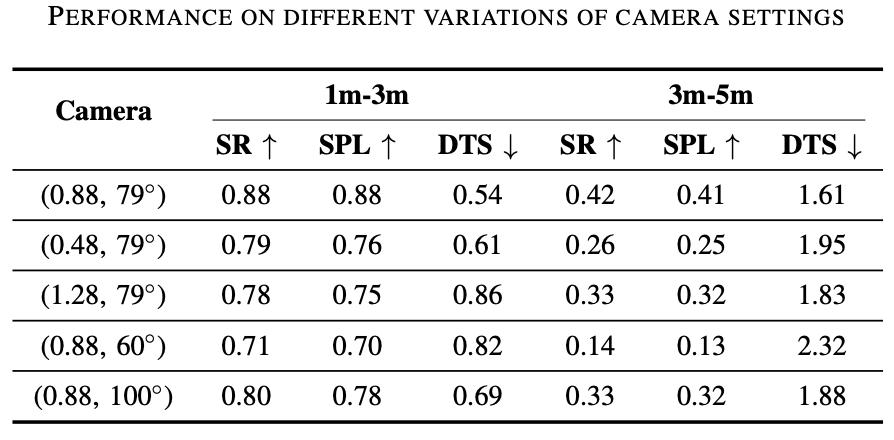
为了验证 PixelNav 在避障导航方面的通用性,此处在相同的数据集和平台中进行消融实验分析 PixelNav 是否在不同的相机参数下能够获得稳定的表现。根据实验结果能够证明,在不同的相机高度以及相机水平视野条件,PixelNav 都具备一定的泛化性。同时实验结果也表明如何进一步提升 PixelNav 在长时路径规划上成功率也是关键问题。