






孔雨晴课题组 NeurIPS 2023 入选论文解读:校准同行审议中的系统性偏差
本文是对发表在 NeurIPS 2023 顶级会议上的论文Calibrating "Cheap Signals" in Peer Review without a Prior 的详细解读。这项研究由北京大学计算机学院博士生陆宇暄和助理教授孔雨晴合作完成,旨在从理论角度上解决学术评审过程中的系统性偏见问题。
论文链接:https://arxiv.org/abs/2312.07269
01 引 入
我们来设想以下3个不同的场景:
1. 设想你是一个 NeurIPS 2023 会议的审稿人,被分配到两篇论文的审稿。两篇文章的话题都是关于机器学习理论研究,你并不指望自己能完全看懂。不过你发现论文1有一个巨长无比的理论证明放在论文的附录中,而论文2的理论证明看上去则非常精简。
2. 设想你是一个单盲期刊的审稿人,被分配到两篇论文的审稿。你发现论文1的作者全部来自 Google Research,而论文2的作者是一个高中生甚至没有 edu 邮箱。
3. 设想你是一个 NeurIPS 2023 会议的审稿人,被分配到两篇论文的审稿。论文1的话题是你熟悉的研究方向,你能非常轻易地看懂论文并指出优点和缺点。而论文2的话题在于冷门的交叉学科,几乎所有审稿人都没有相关的背景。
问题:你会如何为这两篇论文评分?
诚然,如果你足够认真负责并且花费足够多的时间(来仔细阅读论文和学习相关知识),你能为分配到的论文提供公正客观的评价。但是,在审稿过程中你的时间和精力是有限的,不可能搞懂所有内容。在这种情况下,相信你通常会愿意对论文1给出较高的评价,而不愿意对论文2给出较高的评价。
以上的思想实验明确阐述了在同行评审中,系统性偏差是如何影响审稿人的行为的。证明的长度、作者的所属机构和热门(冷门)的研究话题显然都不是论文质量的构成部分,然而正是这些廉价信号很大程度上导致了系统性偏差,影响了审稿人对于论文的评价。
02 问题描述
在同行评审过程中,系统性偏见是一种影响所有审稿人的一致性错误,导致评估结果不论审稿人意图如何都呈现偏斜。在本文中,我们提出相当一部分系统性偏见的产生由廉价信号的影响所导致的。在同行评审的环境中,廉价信号是指那些不需要努力和专业知识就能获得的信号。例如,廉价信号可以是作者及其所属机构(单盲审稿)、写作技巧、叙事能力和证明长度。这些廉价信号很容易被操纵,但确实影响着审稿人对论文的评价,从而导致系统性偏见的出现。
因此,我们考虑了如何从理论上校准同行评审中由廉价信号产生的系统性偏见的问题,即找到一种过程,在一个存在偏见的世界里,能够像没有偏见一样对论文的质量进行排名。现有的相关研究往往依赖于先验知识或历史数据来从经验上校准这些偏见,而本文提出了一种无需任何先验信息的一次性偏差校准过程。
03 模 型
本文使用了一个标准的信号-预测汇报框架,通过要求审稿人预测其他审稿人的对论文的评分并使用这些额外的预测信息来辅助校准。为了方便叙述,这里简要描述本文采用的汇报模型:
没有廉价信号存在时的汇报
- Σ为所有可能信号的集合:例如Σ={reject(0), accept(1)}
- 每篇论文有一个真实状态w∈Δ_Σ:例如w∈{bad(w=[.8, .2]), fair(w=[.5, .5]), good(w=[.2, .8])};
- 真实状态w 的分布服从某个未知的先验Q:例如Q=1/3bad,1/3fair,1/3good;
- 每个审稿人收到服从于从论文真实状态w中的纯净信号σ~w:此时,对于一篇状态为good的论文,审稿人有80%的概率收到accept,有20%的概率收到reject;
- 审稿人会汇报自己收到的纯净信号σ和对于另一个随机审稿人收到纯净信号的后验概率作为预测。
存在廉价信号时的汇报
- 将廉价信号视为一个偏见运算符M,它将审稿人的纯净信号σ转变为有偏信号\hat σ=M(σ);
- 每个审稿人只能获得有偏信号\hat σ而未意识到纯净信号σ;
- 将M表达为一个矩阵,其行表示给定纯净信号时每个有偏信号的概率。有\hat w=wM,\hat σ~\hat w;
- 审稿人会汇报自己收到的纯净信号\hat σ和对于另一个随机审稿人收到有偏信号的后验概率作为预测。

图1. 没有廉价信号时,审稿人收到的纯净信号服从论文的真实状态。

图2. 存在廉价信号时,审稿人收到的有偏信号受到偏见M的影响。
图1和图2详细叙述了纯净信号和有偏信号的产生过程。可以发现,对于一篇类型为good且偏差为负面(50%几率直接拒绝因为其写作过差)的论文,只有40%的审稿人会投票给accept;然而,对于一篇类型为fair但没有偏差的论文,有50%的审稿人会投票给accept。这说明了,即使我们有无限多的审稿人,由于系统性偏差的存在,现有的基于accept比例为论文评分的方法无法正确地排序论文的质量。
04 方法概述
本文提出的校准偏差的方案基于两个关键观察:
- 廉价信号会偏向审稿人的评分,并以相同的方式影响审稿人的先验信念;
- 系统性偏见削弱了审稿人反馈之间的相关性,导致基于不同信号条件的后验变得更接近,进而降低了评分之间的互信息。
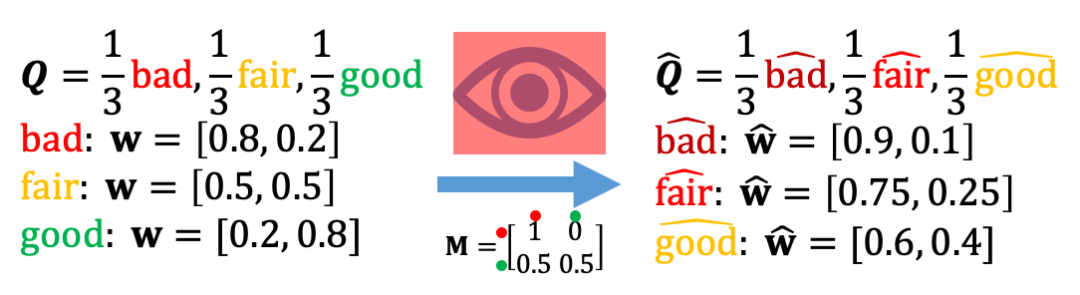
图3. 关键观察1:廉价信号会偏向审稿人的评分,并以相同的方式影响审稿人的先验信念。
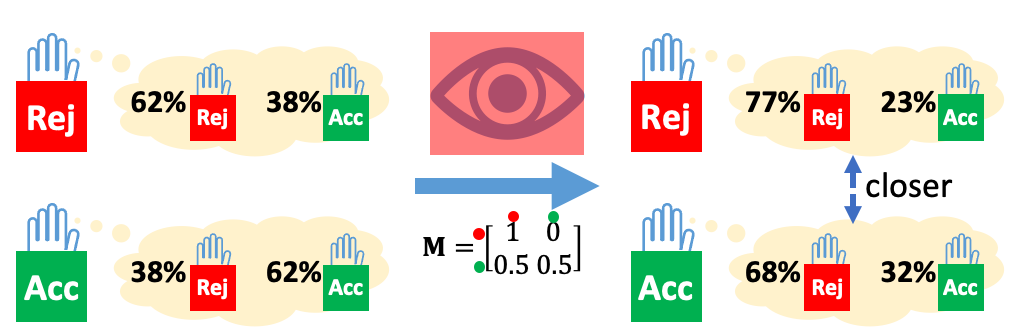
图4. 关键观察2:系统性偏见削弱了审稿人反馈之间的相关性。
基于这两个关键观察,我们方案的主要思想是,通过额外收集审稿人对其他审稿人的预测来校准廉价信号。这个过程可以分为四个步骤。首先,使用有偏信号和预测来创建后验分布。其次,基于后验分布形成两个审稿人评分的联合分布。第三,从这个联合分布中推导出有偏的先验和评分之间的相关性。最后,利用有偏的先验和评分间的相关性来设计一个校准评分,准确反映真实评分。我们将这个方法称为 Surprisal-based Score,具体的计算如下图所示:
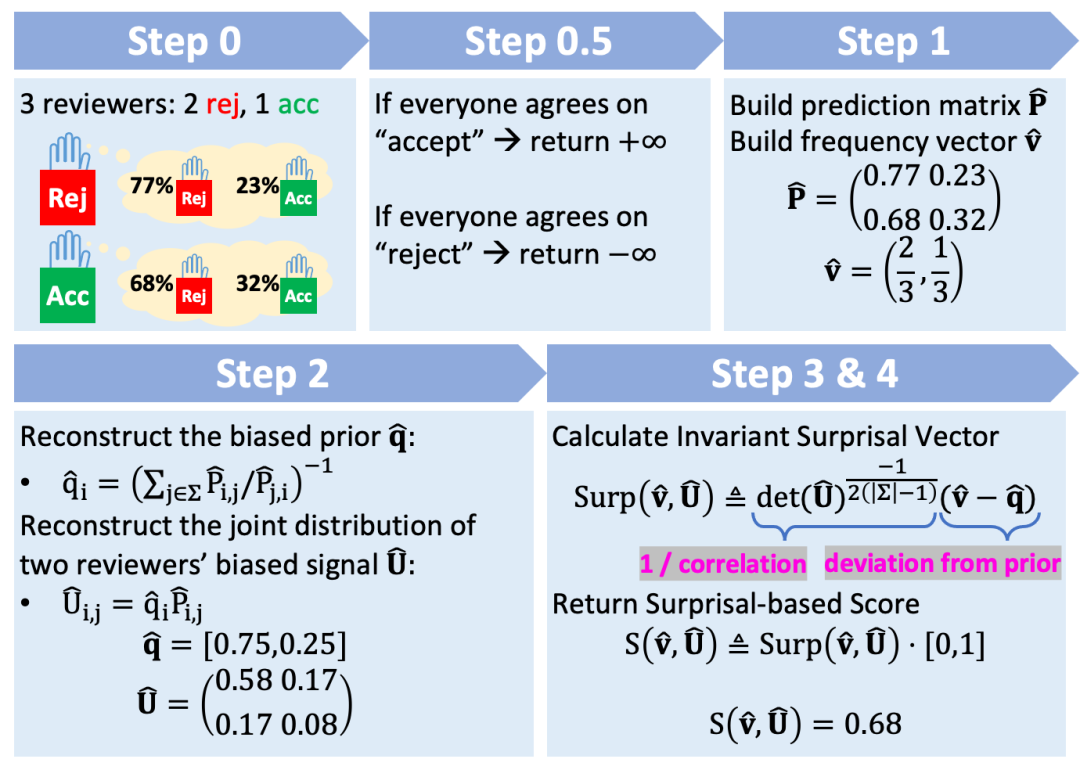
图5. Surprisal-based Score 的计算。
05 理论和实验结果
我们的主要定理表明,在温和条件下,Surprisal-based Score 提供的校准评分是真实评分的期望中的仿射变换。因此,它是评估论文质量的一个良好指标。我们还进行了模拟实验,展示了校准后的分数与平均评分相比,在不同噪声水平和偏见条件下,能够实现更加精确的论文质量比较。具体而言,当审稿人数量增加时,校准分数的误差概率趋向于零,并且在审稿人数量较少时,相比平均评分具有显著的优势。
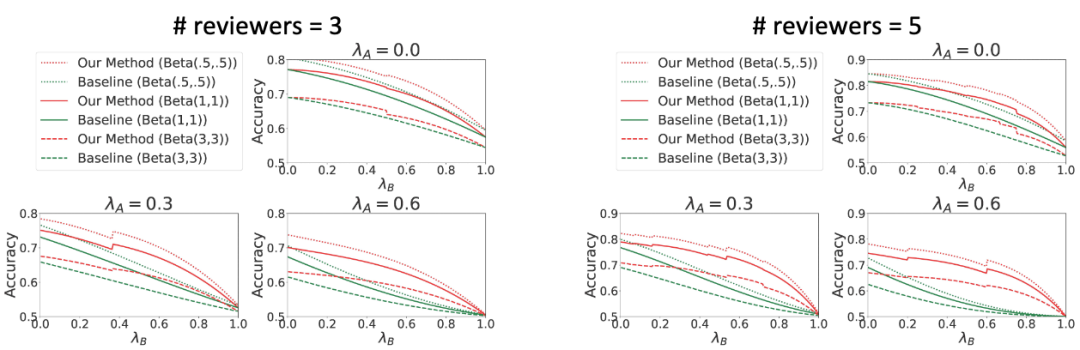
图6. 模拟实验结果。