






董豪课题组 ICCV 2023 入选论文解读:柔性物体长程操作的视觉表征
本文是对发表于计算机视觉领域顶级会议 ICCV 2023 的论文 Learning Foresightful Dense Visual Affordance for Deformable Object Manipulation 的解读。该论文由北京大学董豪课题组完成,共同第一作者为计算机学院博士生吴睿海和图灵班本科生宁川若。
本文针对长程的柔性物体操作任务,提出学习一种逐点级别(point-level)的视觉可供性表征(affordance)来操作柔性物体,同时赋予该表征对未来状态的感知(foresightful),从而得到柔性物体操作任务中的多步最优策略。
项目主页:https://hyperplane-lab.github.io/DeformableAffordance/
开源代码:https://github.com/TritiumR/DeformableAffordance
视频介绍:https://youtu.be/DiZ9aXjK_PU
01 研究背景
柔性物体操作(例如对衣物,绳子等物体的操作)是未来机器人不可或缺的能力。然而,目前机器人领域对柔性物体操作的研究还有很大提升空间,这主要由于柔性物体操作任务具有的难点:
1. 柔性物体状态复杂且难以表征,动力学复杂,动作搜索空间大。
2. 不同于刚体和铰接物体,柔性物体操作任务通常需要多步操作(例如展开衣物)。
前者使得每一步的操作选择都很困难,后者则更引入了长程规划的复杂度,使得贪心策略易于陷入局部最优解。
为了解决上述痛点,在这篇论文里,我们提出学习一种逐点级别(point-level)的视觉可供性表征(affordance)来操作柔性物体,从而有依据地选择操作动作。同时我们赋予该表征对未来状态的感知(foresightful),从而得到柔性物体操作任务中的最优策略。该表征将在每一步操作中预示最佳的抓取和放置操作(如图1),并且避免局部最优情况出现,顺利完成整个长程任务。
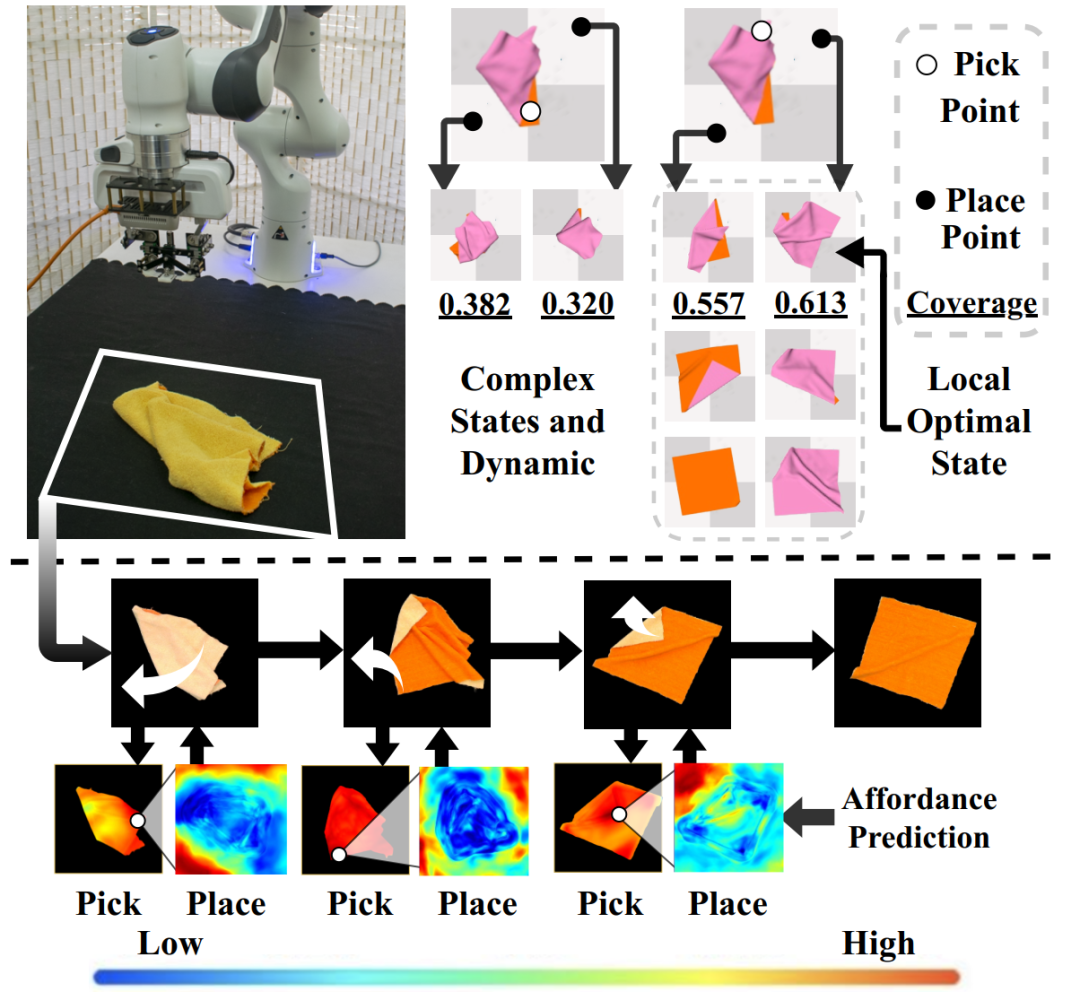
图1. 上方展示了柔性物体操作的两大难点:复杂状态动作空间(左上)和长程任务规划(右上),下方展示了我们提出的视觉表征(pick affordance和place affordance)可以指引机械臂顺利完成整个任务,避开局部最优状态。
02 方法简介
我们的视觉表征由两个模块进行预测:抓取位置的感知模块和基于抓取位置的放置感知模块。给定一个物体的视觉输入,一个抓取点,该模块预测将该抓取点放置在各个像素点的结果和最终目标的距离,即 pick affordance。抓取感知模块则以图像为输入,预测各个像素点作为抓取位置的优劣。
方法的核心要点在于逆过程学习(reverse)和价值(value)估计:即从任务的最终状态开始(例如展平的衣物),先学习最后一步的操作策略,之后向前回溯,利用已经学习好后续过程的模块估计状态的价值,从而指导上一步操作策略的学习,依此类推,直到学习到最初状态(例如揉皱的衣物)。这样的学习方式有以下优点:
1. 相较于正向过程的学习,逆向学习一开始接触的状态(目标状态)比较简单,适合网络学习。
2. 网络积累了后续操作的知识之后,可以估计一个衣物状态的未来价值,即下一步可达到的最佳状态,从而可以向前传递对当前状态的价值估计指导,这样的学习框架可以引导策略避免局部最优状态。
3. 相较于强化学习使用 bellman-equation 来更新价值估计,我们的训练方式是更稳定的的监督学习,搜索的空间也小很多。
具体来说,我们先用最后一步交互的数据监督训练放置感知模块。之后,由于抓取点的选取应该考虑该抓取点能取得的最好结果,所以我们使用 place affordance 最大值监督抓取感知模块,也就是 pick affordance。至此模型具有了规划最后一步操作的能力,pick affordance 的最大值将能够反映一个物体状态的下一步最佳状态,也即这一状态的未来价值(value)。我们可以利用这样的估计和倒数第二步的数据一起监督放置感知模块,这样模型对于未来状态的考虑就融入了 affordance 之中。同上一步相同,接下来需要用新的放置模块训练倒数第二步的抓取模块。依此类推,直到模型已经见到足够复杂的场景(例如打乱5步的衣物已经接近揉皱的状态)。
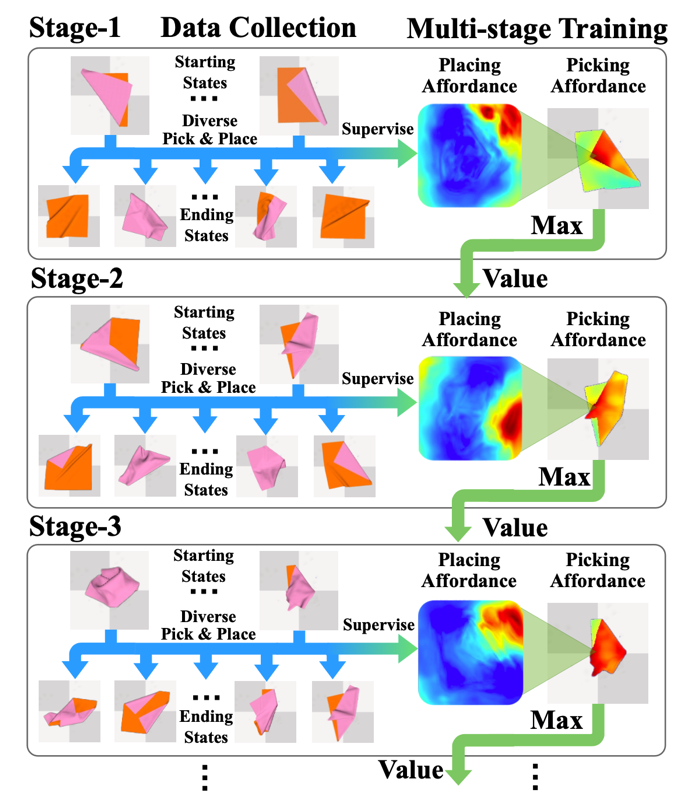
图2. 逆向多阶段训练框架。
03 实验结果
我们使用了两个常见的柔性物体操作环境:DeformableRavens 以及 SoftGym。选取了以往工作表现不佳的四项任务:SpreadCloth:将一个揉皱的布料展开;RopeConfiguration:将一条随机打乱的绳索操作成“S”形;Cable-ring:操作随机打乱的项链到一个指定的圆以及 Cable-ring-notarget:将打乱的项链操作成一个圆。
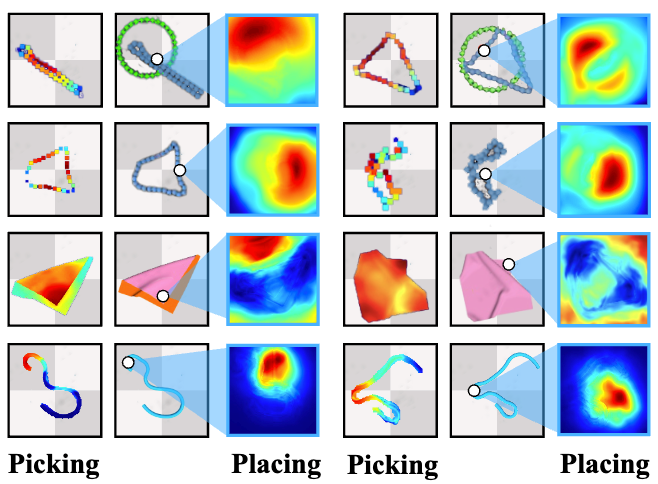
图3. 在不同任务上我们模型输出的 affordance,颜色越亮表示这个点越容易被抓取或者放置,白色代表抓取点。
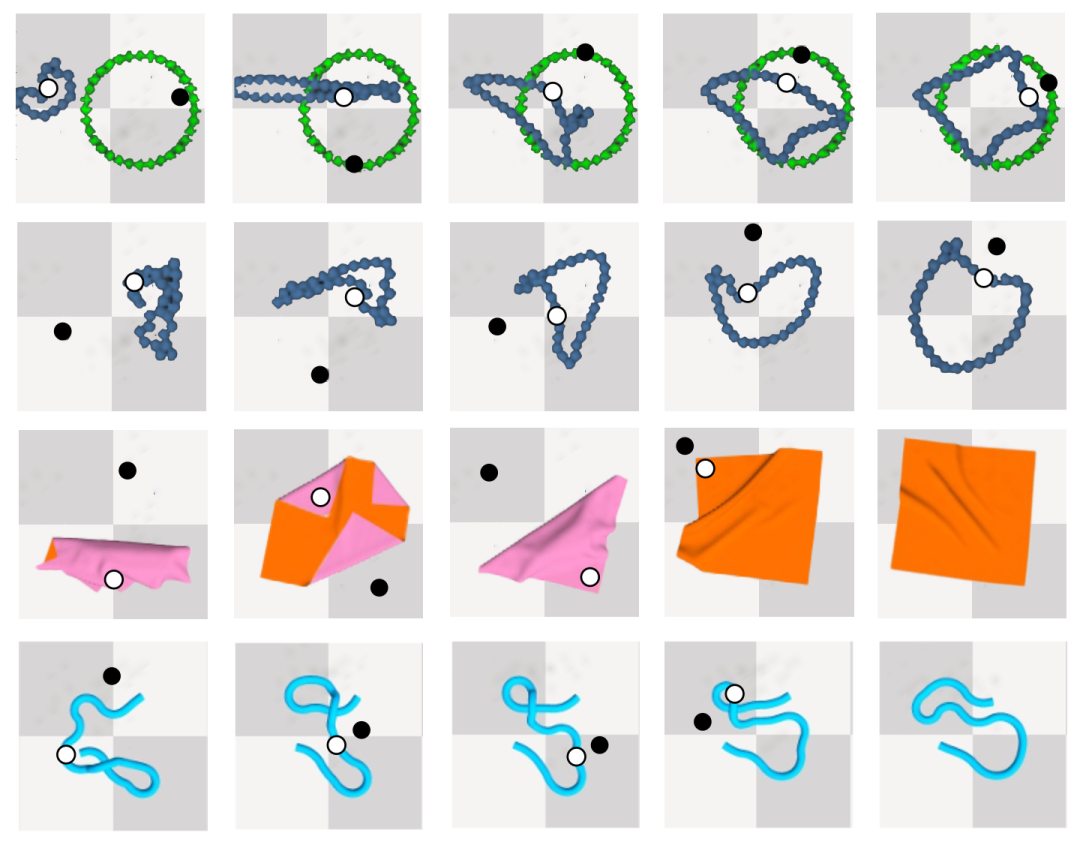
图4. 在不同任务上我们模型的操作序列,白色代表抓取点,黑色代表放置点。
不同任务上的分数表明,我们模型的表现超越了模仿学习策略,这得益于我们的表征拥有更丰富的操作先验,可以从错误中恢复。同时,由于我们训练方法的稳定性和高效的探索方式,我们超越了许多经典的强化学习算法。

表1. 在多个任务上和不同方法的对比。
进一步地,我们进行了真机实验,证明了方法的迁移性和可应用性。
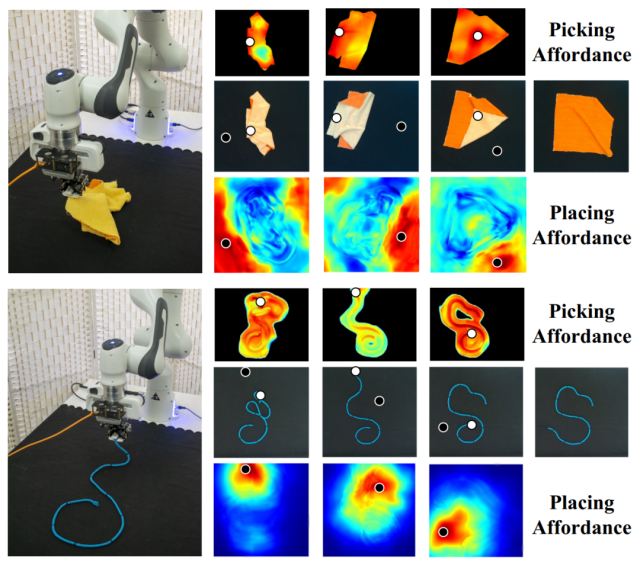
图5. 真机实验的操作轨迹和对应 affordance。
04 总 结
在这篇论文中,为了解决柔性物体操作的两大难点,我们提出了一个逐点级别的视觉操作表征(affordance),并且通过多阶段的逆向学习赋予了该表征考虑未来物体状态的能力,使得该表征可以引导模型顺利完成长程任务。在模拟器和真实世界上的表现证明了该系统的有效性。