






静5⻘年讲座回顾:韩腾达博⼠谈⾃监督视频表征学习
2023年2月10日,英国牛津大学 VGG 实验室(Oxford-Visual Geometry Group)的韩腾达博士受邀带来题为“Self-supervised Video Representation Learning”的在线报告。报告由中心助理教授董豪老师主持,相关内容通过蔻享学术、科研云、Bilibili、视频号同步直播,线上数千人观看。
在报告的开始,韩博士从视频学习与自监督学习这两个方面介绍了研究视频自监督学习的必要性:
1. 互联网上有海量的数据可供我们训练,例如 YouTube 上每天上传的视频时长超过82年[1];同时相较于静态的图像, 视频丰富的信息可以为研究推理、计划等下游任务提供保证;
2. 全部交给人工标注显然是不现实的,基于无标签数据的自监督学习是最可行的选项。
视频自监督学习按照监督信息来源主要可分为三类:
- 时间(learning from the time),
- 动作(learning from the motion),
- 文本 (learning from the text)。
随着 GPT 和 CLIP 等一系列技术出现,将视频与文本对应关联变得越来越可行。在简单介绍了自己之前对视频的时间[2][3]与动作[4]的自监督表征学习工作后,韩博士重点对如何从视频中学习文本的工作进行了详细阐述。

01 长视频的时序对齐
韩博士首先介绍了其团队发表在 CVPR 2022(Oral)的工作 Temporal Alignment Networks for Long-term Video。该工作解决的问题是大量长视频中语言-画面的对齐问题。该问题的解决将能为下游的任务提供高质量的语言-画面对齐数据,提升下游任务的性能。

视频中的文字与画面对齐问题,尤其是 instructional videos 中(例如做饭教程视频),人物说的话和他正在做的事儿经常不是完全对齐的、描述信息和视频内容的顺序有时也是错乱的、甚至文字与画面毫不相干的情形也经常出现。因此,为了解决上述基于长视频的“语言-画面”对齐问题,韩博士提出了 TAN 模型(Temporal Alignment Networks model)[5]:
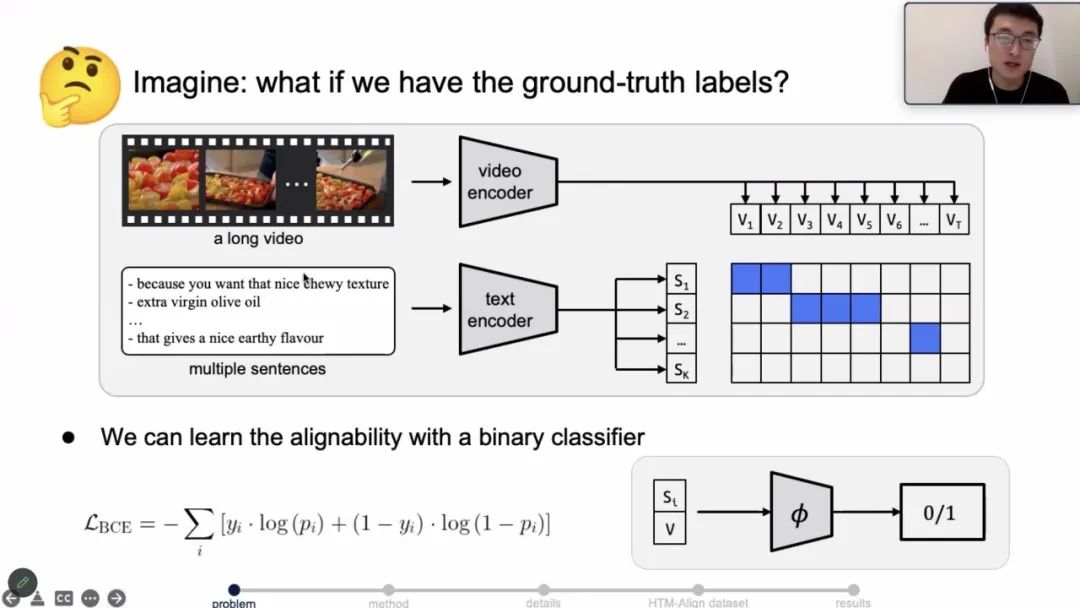
可以看到, 其模型核心思路是利用两个独立的预训练 encoder,分别对视频和文字进行编码, 再利用自监督学习的范式将得到的 embedding 在特征空间上进行对齐,最后运用对比学习方式通过 InfoNCE[6]来训练。

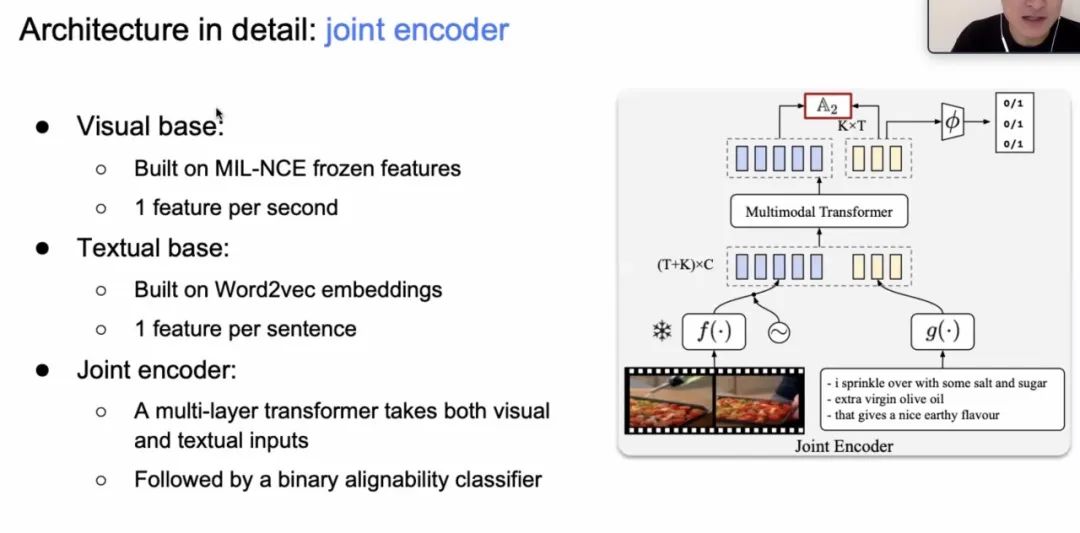
特别的,文本编码器(Text Encoder)和视频编码器(Video Encoder)分别基于 MIL-NCE frozen feature 和 Word2Vec embedding。两个编码器通过如下机制组成联合编码器(Joint Encoder),即将得到的 text embedding 和 video embedding concat 后通过 Transformer 融合,最终再通过一个二分类分类器来获得准确的对齐位置。
最终,和 MIL-NCE[7]相比,TAN 取得明显的提升,特别的,通过可视化,可以直观的看到本文提出的模型可以有效的表达并处理视频-文本对齐问题。

02 Token Dropout 机制对视频训练的加速
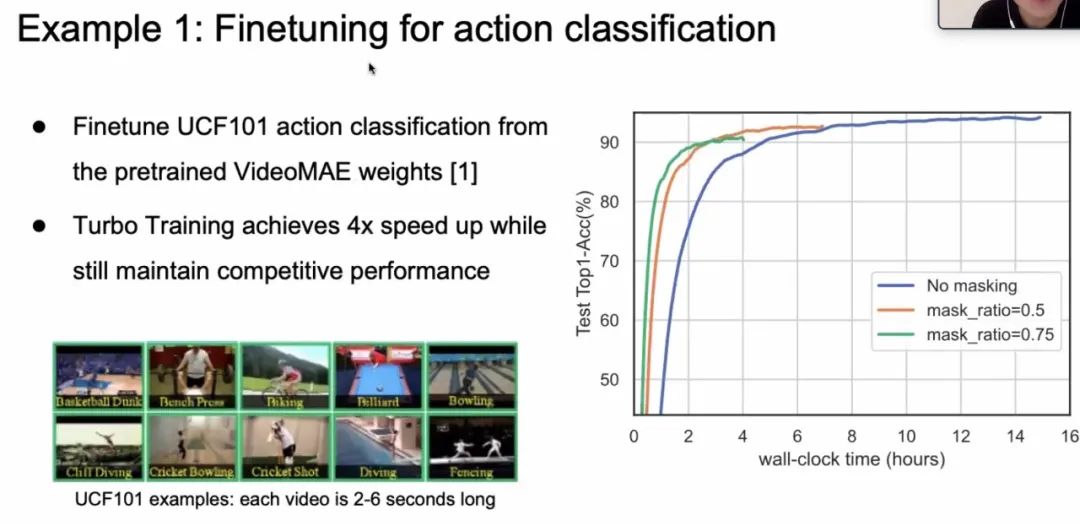
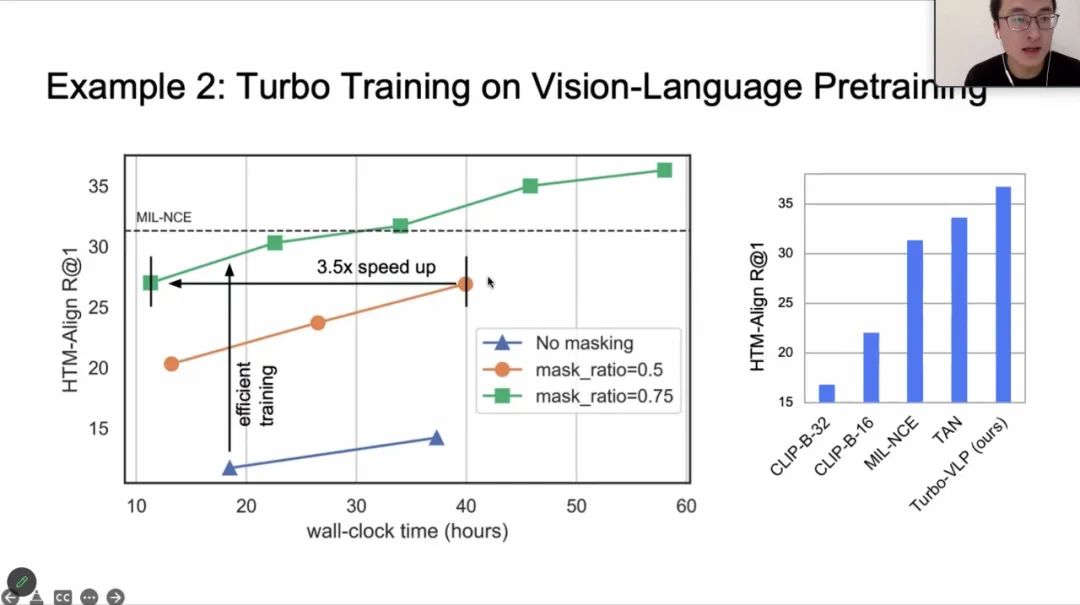
视频数据相较于图片和文本等,有着体积过大、处理速度过慢等缺点,其主要原因时视频数据量冗余(如相邻画面间的信息差异极小)。针对这一问题, 韩博士提出了 Token Dropout 和 Partial-MAE 机制[8]对视频训练进行加速。在保证模型性能基本不变的情况下,在某些任务上,GPU 显存存可以有效减低8倍,训练速度可以提升4倍[8]。
其核心思想是受启发于 MAE[9][10][11]的 sparse sample & reconstruct 和 ViTs[12]的基础架构,具体来说:
1. ViT 负责各种任务(vison language pretrain/ video classification ...),但在输入过程中随机丢弃一定比例的 token;
2. MAE loss 负责从 ViT 给出的 feature 中恢复原始图像,用于控制 feature 的质量。

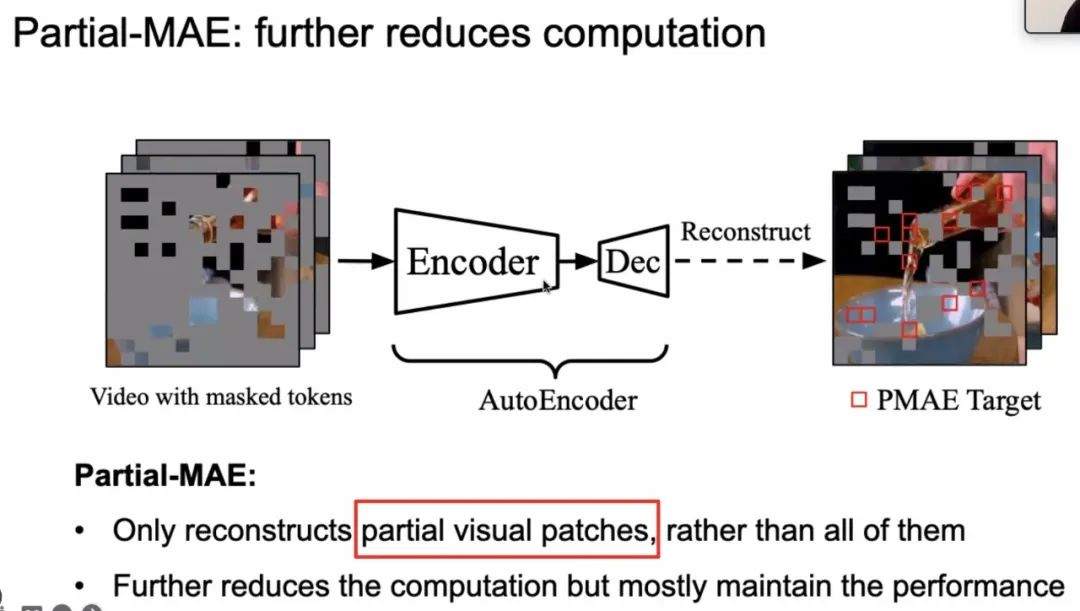
特别的,作者发现并不需要将所有标记的 patch 全部还原,即重构部分图片 patch 也可以保证模型性能基本不变,因此,提出了 Partial-MAE。这样,无论是 Encoder 的输入还是输出都只需要考虑视频图像中若干小块,忽略了大部分的数据,大大减小了所需的计算量,因此能大幅提高运算效率。
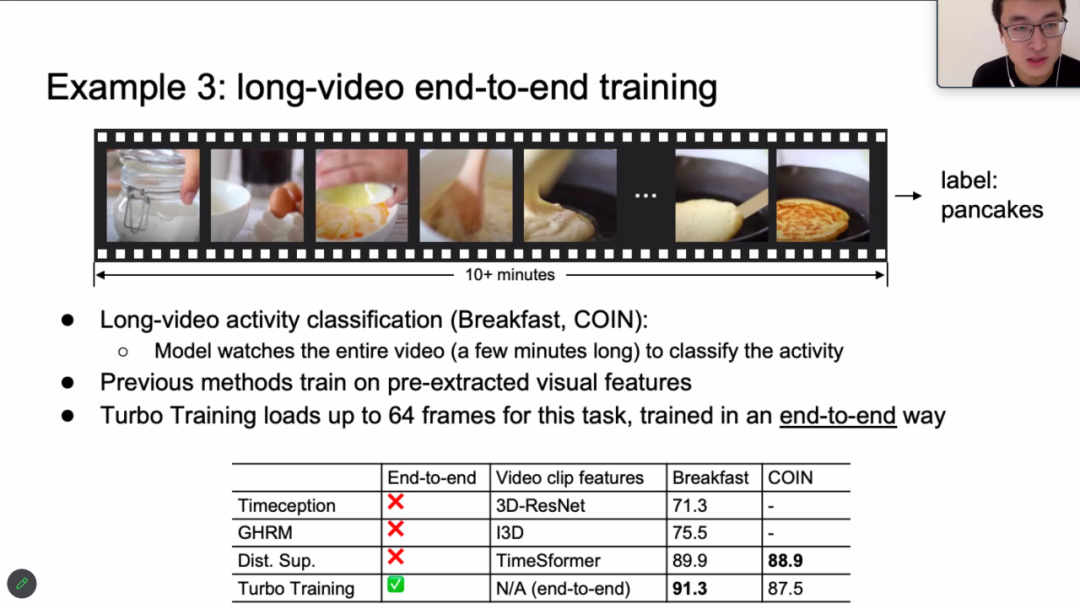
韩博士最后介绍了些 case study,运用 Turbo Training 的思想,在保证模型性能基本不变的情况下,在 vison language pretrain, action classification, Long video training 等任务上,GPU 显存和训练速度都有很大的提升。
讲座尾声,韩博士对同学们提出的提问进行了详细的解答。
参考文献
[1] 10 YouTube Statistics That You Need to Know in 2022 - Oberlo https://www.oberlo.com
[2] Video Representation Learning by Dense Predictive Coding. Han et al. ICCVW 2019.
[3] Memory-augmented Dense Predictive Coding for Video Representation Learning. Han et al. ECCV2020.
[4] Self-supervised Co-Training for Video Representation Learning. Han et al. NeurIPS 2020.
[5] Temporal Alignment Networks for Long-term Video. Han et al. CVPR 2022.
[6] Representation Learning with Contrastive Predictive Coding.
[7] End-to-End Learning of Visual Representations from Uncurated Instructional Videos. Miech et al.CVPR2020.
[8] Turbo Training with Token Dropout. Han et al. BMVC 2022.
[9] Masked Autoencoders Are Scalable Vision Learners. He et al.
[10] VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training. Tong et al.
[11] Masked Autoencoders As Spatiotemporal Learners. Feichtenhofer et al.
[12] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. x et al. ICRL2021.