






王鹤课题组 AAAI 2023 入选论文(Oral)解读:对自然条件下的点云序列中手物交互的位姿追踪与重建

本文是 AAAI 2023 Oral 入选论文 Tracking and Reconstructing Hand Object Interactions from Point Cloud Sequences in the Wild 的解读。本论文由北京大学王鹤研究团队与北京通用人工智能研究院、弗吉尼亚理工大学、斯坦福大学、清华大学、哥伦比亚大学合作,针对追踪并重建一段输入点云序列中的手和物体这一任务进行了研究。
我们首次提出了一个基于点云的手部关节追踪网络 HandTrackNet,并设计了一套完整的算法来完成手和物体追踪与重建这一具有挑战性的任务。此外,为了获得更多样且精准的数据,我们在仿真器中生成了大量手物交互的数据,并模拟了深度相机的拍摄原理,以获得接近真实世界噪声分布的深度数据。仅用仿真数据进行训练,我们的方法可以很好地泛化到未见过的真实场景测试数据上,以较快的速度(9FPS)取得远超前人工作的精度。
论文链接:http://arxiv.org/abs/2209.12009
项目主页:https://pku-epic.github.io/HOtrack
代码地址:https://github.com/PKU-EPIC/HOTrack
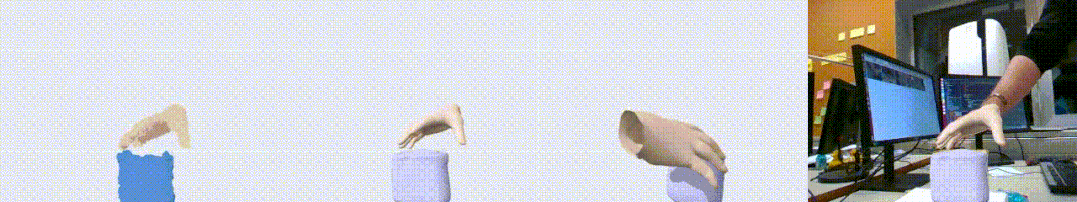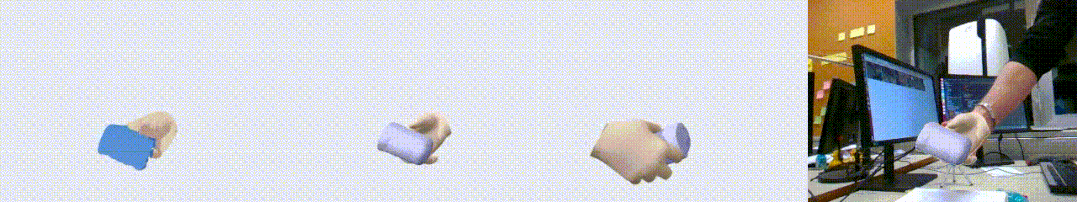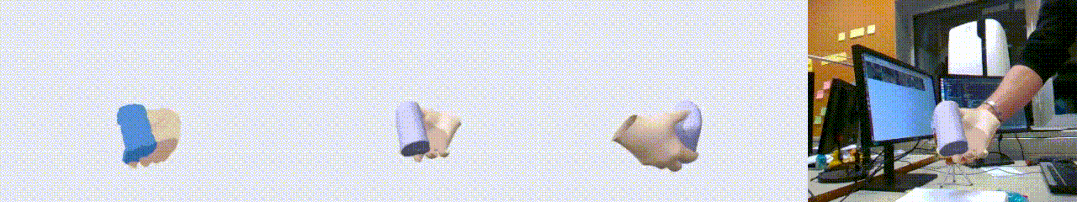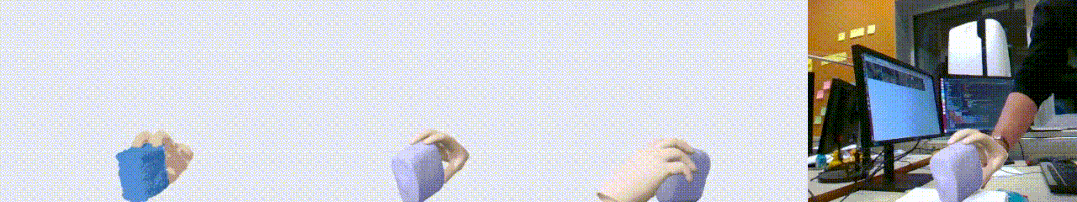
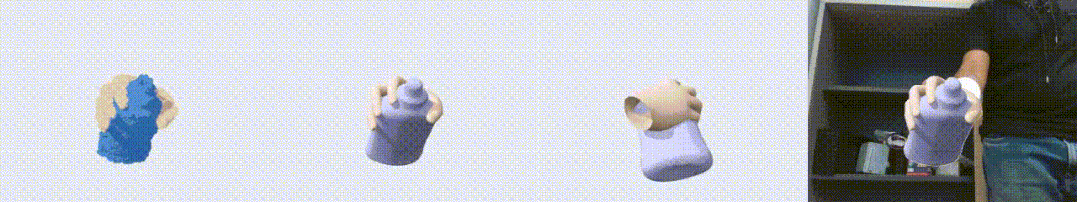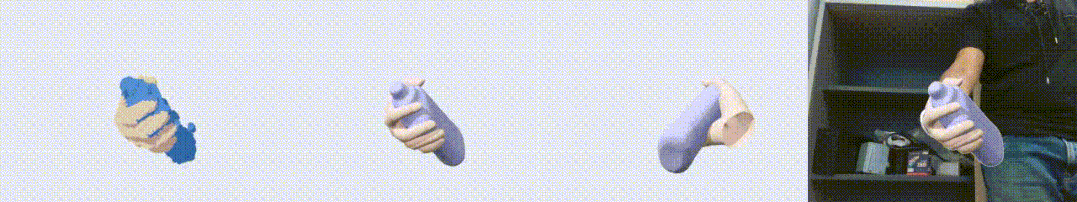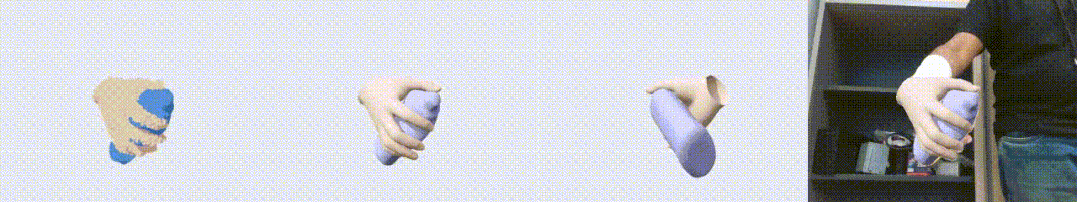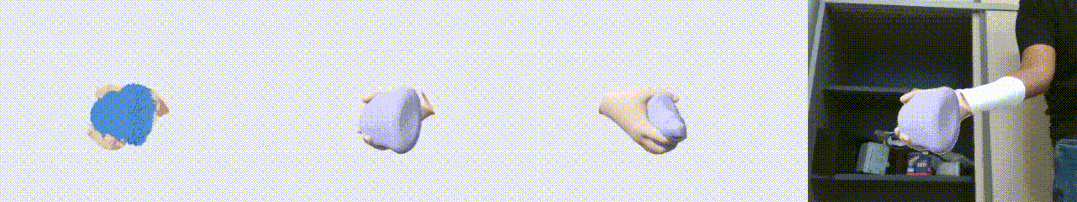

图1. HO3D 数据集上的效果展示图。左起依次为输入点云,输出重建结果,另一个视角的输出,以及输出与 RGB 叠置的效果。可以看到,我们的算法对手物交互中的遮挡问题有很好的鲁棒性。



图2. DexYCB 数据集上的效果展示图。
01 引 言
手和物体的交互作为人类与复杂现实场景交互的主要途径,在现实生活中无处不在。作为感知人类与物体交互的主要方法,位姿追踪和重建人手与物体是两个至关重要的研究课题,可以实现广泛的应用,包括人机交互[1],增强现实[2],以及让机器人从人类的演示中学习相应技能(如抓取和操纵等[3])。
近年来,随着深度学习的发展,越来越多基于深度学习的工作涌现出来,研究如何从单帧信息(RGB 图片[4]或点云[5])中去感知手和物体,重建他们的几何形状或是估计他们的位姿,但是这类方法往往无法利用上视频相邻帧之间的连续性。另一方面,深度学习非常依赖数据,而对真实场景视频中的手和物体去准确标注三维几何形状及位姿是一件非常困难且成本极大的事情,现有的数据集如 DexYCB[6]和 HO3D[7]都规模不大且包含的物体数量少(不超过20个不同物体),用这样的数据难以训练出能够泛化到未见过的手和物体的模型。
因此,在这个工作中,我们关注于这样一个非常有挑战的任务——在不用任何真实数据作训练的前提下,对自然条件下的点云序列,联合追踪并重建人手和物体。我们的任务设定如下所述:给定一个包含已分割的手和物体的深度点云序列,还有初始的手部位姿和物体位姿,我们的算法需要去重建手和物体的几何形状,并以一个在线的方式(即对于第t帧的预测只能利用当前帧和过去帧的信息,不能利用未来帧的信息)对他们的位姿进行追踪。我们选择点云这一模态作为输入而非图片是因为他们具有更加准确的三维结构,便于我们感知手和物体的位姿,并且具有更小的歧义性。
为了实现这一目标,首先,为了缓解数据问题,我们提出了一套流程来合成手和物体交互的仿真数据集。该数据集拥有非常高的多样性,无论是手的形状、物体的形状,还是两者的交互姿势;此外,得益于仿真环境的优势,这些数据带有免费的位姿和形状标注。为了最小化仿真和现实的领域差异,我们利用 DDS[8]提出的基于结构光的深度传感器模拟器,生成带有真实传感器噪声的仿真点云。
除此之外,我们首次提出了一个基于点云的手部姿势跟踪网络,HandTrackNet,以追踪帧间手部关节的运动。HandTrackNet 建立在 PointNet++[9]的基础上,基于上一帧的预测来估计当前帧手部关节位置的变化。相较于单帧回归的算法,这样做压缩了输出数据的分布空间,简化了回归任务,增强了时序上的连续性。此外,HandTrackNet 会从上一帧的预测中计算手的全局位姿,并利用手的全局位姿来将当前帧的输入点云变换到一个规范化的坐标系内,这极大地压缩了输入数据的分布空间,进一步简化了回归任务。在训练过程中,HandTrackNet 会学习修正随机的手部关节扰动,因此不会过拟合到任何时序轨迹上。
最后,为了更好的解决手和物体遮挡带来的歧义性,我们进一步利用基于优化的方法来推理手和物体之间的空间关系,获取物理上更加真实的预测。我们先将追踪到的手部关节位置转化为 MANO[10]这一参数化模型的表示,得到手部几何的重建,然后根据手和物体交互的先验构建几个能量函数,用于进一步调整手的位姿,从而产生更加符合物理规律、更加真实的手部位姿。
通过充分的实验,我们证明了我们的方法在从未见过的真实世界手和物体交互数据集 HO3D[7]和 DexYCB[6]中的有效性。我们的方法在手和物体的位姿追踪精度上明显优于之前的方法,并显示出良好的追踪鲁棒性和极强的泛化性。整个算法能够以交互式帧率(约9FPS)进行在线跟踪和重建。
02 方法简介

图3. 我们生成的 SimGrasp 数据集。
首先,为了应对数据不足的问题,我们在仿真环境中造了一个手和物体交互的数据集 SimGrasp,包含超过450个不同的物体和100个不同大小的手,一共生成了1810段视频,每段视频有100帧。我们首先使用 GraspIt[11]来生成了一些手和物体呈持握状态的数据,然后将手往手背方向挪一定距离,并通过对位姿插值的方式获取动态抓取的视频。为了减少 Sim2real 的巨大差异,我们重新实现了 DDS 算法[8],基于结构光深度相机的原理,在仿真环境中模拟了真实相机点云会产生的噪声。

图4. HandTrackNet 结构示意图。
在方法上,我们首次提出了一个基于点云的手部关节追踪网络 HandTrackNet,该网络接收当前第t帧的手部点云P_{t}和上一帧预测的手部关节位置J_{t-1}作为输入,并对二者进行全局姿势规范化处理。然后,它利用 PointNet++[9]从规范化的手部点云P^{\prime}中提取特征,并使用每个关节进行K近邻查询和特征传递,最后用一个多层线性感知机来回归并更新关节位置。
其中,主要的创新部分在于利用上一帧预测的关节位置来进行全局姿势规范化上。前人的工作[5]发现手的全局位姿的多样性会给网络预测关节位置带来很大的困难,而如果能够设计比较好的全局位姿规范化方法,使得所有的输入点云都能被变换到同一个规范位姿下(例如手心朝向+y轴,指尖指向+z轴),就能大大降低学习难度,提升泛化能力。注意到,按照之前定义的手部规范位姿,规范化的手部点云的第一特征向量应该平行z轴,第二特征向量应该平行x 轴,因此前人工作[5]中大多使用 PCA 来获取手部点云的外包围盒,并利用上述特性进行手的全局姿势规范化。然而,这样的做法存在的缺陷是当手被严重遮挡时,获取的外包围盒无法很好地反应真实手部全局位姿,因此不适用于手和物体交互的场景。
而我们则是注意到,手部指根处的关节点相对位置无论手指怎么动都是基本不变的,因此我们可以用 SVD 求解上一帧指根关节位置相对于预定义的规范位姿下的指根位置的平移和旋转,结合视频的连续性,利用这一平移和旋转去规范化当前帧的手部点云输入。

图5. 完整流程图。第0帧,我们会重建手和物体的几何(如虚线所示);后续每一帧,我们会分别预测物体的位姿{R^{obj}, T^{obj}}和手的位姿{R^{hand}, T^{hand},Θ},并通过优化来进一步修复手的位姿。我们还可以每10帧更新一次手和物体的几何。
利用 HandTrackNet 获取手部关节位置后,我们利用一个简单的多层感知机网络 IKNet 将手部关节位置J^{pred}转化成了手部各关节角度Θ,将Θ作为 MANO 这一常用的手部参数化模型的输入,结合第0帧通过优化获得的手部形状参数β,就可以得到手的完整三维重建了。而物体这一支,我们在第0帧利用 DeepSDF[12]的技术来根据观察到的点云去重建类别级未知物体的几何形状,并在之后每一帧通过优化的办法来解算物体位姿。最后,我们还使用了一个联合优化的模块,使用手与物体不会互相穿透、手指会贴近物体表面等条件作为能量函数来优化手的位姿,获取更符合物理规律、更真实的手物交互。我们还可以每隔10帧更新一次手和物体的几何,降低初始化时的几何误差对后续追踪的影响。
03 实验结果
我们仅仅使用我们合成的仿真数据集 SimGrasp 进行训练,在不使用任何真实数据进一步训练的情况下,直接在 HO3D[7]和 DexYCB[6]这两个具有挑战性的真实数据集上进行测试。相较于之前基于单帧预测的工作HandFoldingNet[13],A2J[14]和 VirtualView[15]以及基于追踪的工作 Forth[16],我们的方法在平均关节位置误差这项指标上在两个数据集中分别能显著提升6mm 和3mm 以上。

图6. 手部关节追踪实验结果。MPJPE 指平均关节位置误差,PD 指手和物体最大穿透深度,DD 指手和物体在接触时手指到物体上最近点的平均距离。
物体追踪方面,虽然之前的工作 CAPTRA[17]在验证集上能获得更好的表现,但是在真实数据的测试集上,我们基于优化的方法能够一致地超过它,证明了我们方法具有更强的泛化能力。
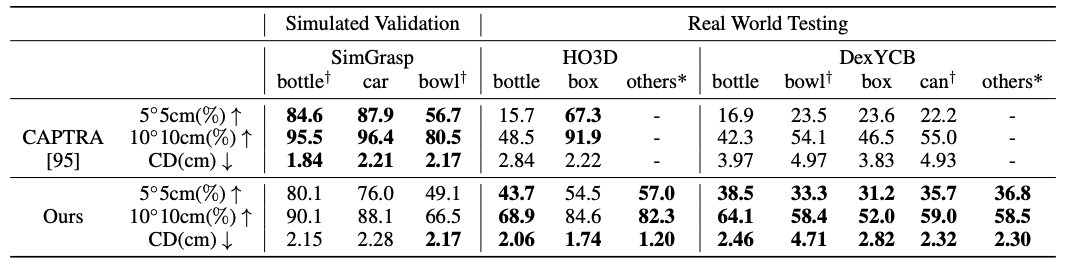
图7. 物体追踪实验结果。5度5cm 指旋转误差小于5度且平移误差小于5cm 的百分比,10度10cm 同理,CD 指带位姿的重建物体和标注物体的倒角距离(Chamfer distance)。
参考文献
[1] Yang, W., Paxton, C., Cakmak, M., Fox, D.: Human grasp classification for reactive humanto-robot handovers. IROS 2020.
[2] Hürst, W., Van Wezel, C.: Gesture-based interaction via finger tracking for mobile augmented reality. MTA 2013.
[3] Garcia-Hernando, G., Johns, E., Kim, T.K.: Physics-based dexterous manipulations with estimated hand poses and residual reinforcement learning. IROS 2020.
[4] Oberweger, M., Wohlhart, P., Lepetit, V.: Hands deep in deep learning for hand pose estimation. arXiv:1502.06807 (2015).
[5] Ge, L., Cai, Y., Weng, J., Yuan, J.: Hand pointnet: 3d hand pose estimation using point sets. CVPR 2018.
[6] Chao, Y.W., Yang, W., Xiang, Y., Molchanov, P., Handa, A., Tremblay, J., Narang, Y.S., Van Wyk, K., Iqbal, U., Birchfield, S., et al.: Dexycb: A benchmark for capturing hand 10 grasping of objects. CVPR 2021.
[7] Hampali, S., Rad, M., Oberweger, M., Lepetit, V.: Honnotate: A method for 3d annotation of hand and object poses. CVPR 2020.
[8] Planche, B., Singh, R.V.: Physics-based differentiable depth sensor simulation. CVPR 2021.
[9] Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. NeurIPS 2017.
[10] Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. ToG 2017.
[11] Miller, A.T., Allen, P.K.: Graspit! a versatile simulator for robotic grasping. RAM 2004.
[12] Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: Deepsdf: Learning continuous signed distance functions for shape representation. CVPR 2019.
[13] Cheng, W., Park, J.H., Ko, J.H.: Handfoldingnet: A 3d hand pose estimation network using multiscale-feature guided folding of a 2d hand skeleton. ICCV 2021.
[14] Xiong, F., Zhang, B., Xiao, Y., Cao, Z., Yu, T., Zhou, J.T., Yuan, J.: A2j: Anchor-tojoint regression network for 3d articulated pose estimation from a single depth image. ICCV 2019.
[15] Cheng, J., Wan, Y., Zuo, D., Ma, C., Gu, J., Tan, P., Wang, H., Deng, X., Zhang, Y.: Efficient virtual view selection for 3d hand pose estimation. arXiv:2203.15458 (2022).
[16] Oikonomidis, I., Kyriazis, N., Argyros, A.A.: Efficient model-based 3D tracking of hand articulations using kinect. BmVC 2011.
[17] Weng, Y., Wang, H., Zhou, Q., Qin, Y., Duan, Y., Fan, Q., Chen, B., Su, H., Guibas, L.J.: Captra: Category-level pose tracking for rigid and articulated objects from point clouds. ICCV 2021.