






北京大学图灵班本科生获得NeurIPS 2022 MyoChallenge挑战赛冠军
在人工智能顶级会议 NeurIPS 2022(第36届神经信息处理系统大会)上,由北京大学人工智能研究院杨耀东助理教授、计算机学院前沿计算研究中心董豪助理教授共同指导,北京大学2020级图灵班本科生耿逸然和安博施作为共同第一作者获得 MyoChallenge 挑战赛 Die reorientation 赛道冠军。
该挑战赛提供了一套高逼真度的肌肉-骨骼灵巧手模型以及交互环境,通过两个非常困难的仿生灵巧手操纵物体的任务来探索生物肌肉的控制。该挑战吸引了来自全球十多个国家40个顶尖队伍参加,共产生了340余份有效方案提交。这一项学术界的新的挑战意义重大:挑战中使用的智能体拥有与人类感受-运动系统相似的感知-控制循环,因此基于此项挑战的研究将有望在运动障碍治疗、康复技术、外科手术以及协作型机器人等领域产生深远的影响。

图1. 获奖证书
比赛官网:https://sites.google.com/view/myochallenge
开源地址:https://github.com/PKU-MARL/MyoChallenge
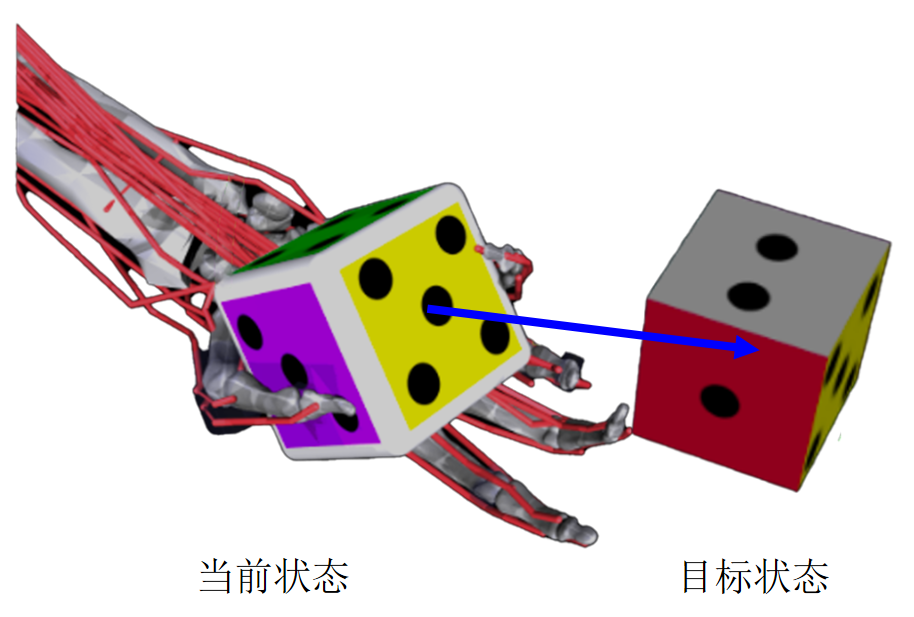
图2. MyoChallenge 平台中的骰子重定向任务,需要通过控制仿生灵巧手,使骰子转到指定的目标方向。这项任务需要各种肌肉的微妙协调,在旋转骰子的同时保证骰子不掉落。最终成功率最高、需要肌肉施加力最小的团队将获胜。
灵巧手在人类生产生活中有着非常重要的作用,通过控制灵巧手,我们可以精准、稳定地完成抓取物体,操作物体等任务。然而,由于灵巧手具有较多关节,涉及到的控制问题非常复杂,其灵巧性、稳定性、通用性、安全性等方面还没得到有效解决,该问题是人工智能领域重要的挑战。研究灵巧手的控制,对未来的家用机器人,手术机器人,辅助机器人等应用领域起着关键作用。
最近有很多关于灵巧手控制的工作,然而目前的经典控制算法和人工智能算法仍无法媲美生物神经系统对运动的控制能力。对于骨骼肌的精确控制是生物实现敏捷和灵活运动的重要基础(如图3),然而由于生物体的运动涉及到上百组骨骼肌的精细协调,因此有关基于骨骼-肌肉模型的运动控制仍是一个有待深入探索的领域,我们本次的研究工作在灵巧手控制问题上带来了一个新的解决思路。

图3. 猎豹奔跑和人类演奏钢琴都涉及到困难的感知-控制过程。
研究背景
在 MyoChallenge 之前,已经有很多用灵巧的手完成物体操纵任务的工作。然而,这些工作中大多数灵巧手可以直接控制每个独立的关节,这与 MyoChallenge 中基于肌肉的仿生灵巧手的控制是有很大区别的:例如,如果我们对灵巧手的一个关节施加一个力,只有那个关节会相应地移动,但如果我们令仿生灵巧手控制指尖的肌肉收缩,则整根手指的所有关节都会受到影响(如图4);同时,由于肌肉只能收缩,因此控制一个关节向不同方向转动将涉及到不同的肌肉。此外,MyoChallenge 的手部模型还引入了肌减少症、肌肉疲劳和肌腱转移(如图4)等异常情况,这使得任务更加困难。更重要的是,这个挑战的环境包含了许多随机参数,包括物体初始位置随机化、任务目标随机化以及物体的物理属性(如物体大小和摩擦力)的随机化。因此,我们需要训练一个能够适应特殊手部控制模型以及参数随机化的策略。
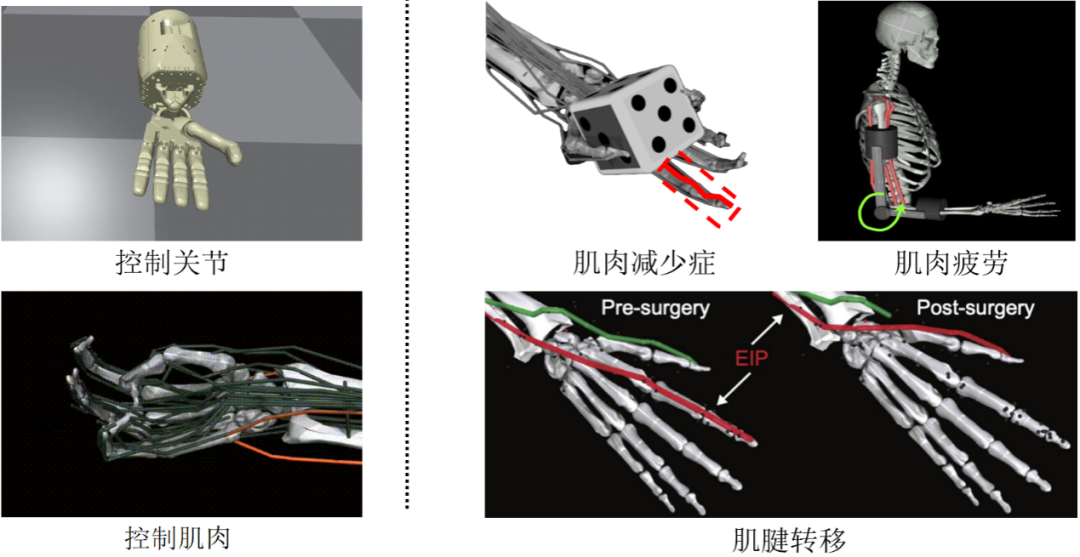
图4. 左侧:不同灵巧手控制方式;右侧:MyoChallenge 中的特殊灵巧手模型。
研究方法
我们采用强化学习框架来在模拟器里训练我们的策略。在训练中,我们采用了奖励塑造(Reward Shaping)、课程学习(Curriculum Learning)和多目标训练(Multi-target Training)(如图5)等技巧来提高训练后的策略的性能。这些方法共同产生的成功率比 MyoChallenge 中给出的基线算法有了明显的改善(在挑战的第一阶段提升为70%,第二阶段为11%)。

图5. 方法概览
在强化学习框架下,我们使用自然策略梯度(NPG)来训练我们的策略。我们的策略网络相当简单:只包括一个有两个隐藏层的神经网络,每个隐藏层的大小为64。在这里,我们也许可以从生物学的角度来理解这样一个简单的网络所取得的效率:人类的小脑主要负责精确的运动控制和运动学习,在 James Albus 提出的小脑模型中[1],总共包含三层神经元:苔藓纤维、颗粒细胞和浦肯野细胞,每一层只与下一层的神经元有连接。这种生物结构似乎表明,简单的神经网络在合理训练后也可以有很好的表现。
然而,由于人类小脑的学习机制仍然是一个谜,我们不清楚人类是如何用小脑中如此简单的结构获得如此精确和灵巧的运动能力的。所以在挑战中,我们没能从人脑中得到进一步的启发,只能通过以下三种方法来训练策略网络。
第一种方法是奖励塑造,这与训练动物完成一些特殊动作的过程非常相似。我们在水族馆经常看见饲养员在海豚完成高难度动作后用小鱼作为奖励,而小鱼类似于强化学习框架下的奖励函数,我们在算法有希望完成目标动作的时候加大奖励函数,便能激励算法逐渐掌握目标动作。为此,我们设计了一套复杂的奖励机制来计算奖励函数。
第二种方法是课程学习,这与人类从易到难学习一门知识的过程非常相似。我们不可能刚进入小学就开始学习微积分,而需要先从基本的加减乘除学起,经过许多课程的学习后才能理解微积分。为此,我们将挑战中的骰子重定向任务拆分成三个课程:拿稳骰子、90°以内的重定向、180°以内的重定向。算法将先从最简单的拿稳骰子学起,最后完成最困难的180°重定向任务。这样一点点增加课程的难度使得算法的性能可以稳定上升。
第三种方法是多目标学习,这与体操比赛中的组合动作练习类似。在体操中,运动员需要连续地完成一系列不同的动作。我们的多目标学习过程要求算法控制仿生灵巧手连续地完成多个重定向任务,从而提高对物体的掌控能力。
结 语
MyoChallenge 提供了一个验证仿生灵巧手控制算法的测试平台。在本次的挑战中,我们的队伍采用强化学习框架下的基础但有效的方法,使用简单的模型得到了良好的效果,证明了强化学习算法进行复杂的骨骼-肌肉模型的运动控制以及与物体交互可行性,并在挑战中取得了骰子重定向赛道第一的成绩。未来我们将持续关注骨骼-肌肉模型的运动控制以及高维动作空间的灵巧操纵等问题,并展开进一步的研究。基于此项挑战的研究将有望在运动障碍治疗、康复技术、外科手术以及协作型机器人等领域产生深远的影响。
参考文献
Albus, J. (1971), Theory of Cerebellar Function, Mathematical Biosciences, [online], https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=820146 (Accessed February 3, 2023).
背景链接
“图灵人才培养计划”的设立旨在打造深具北大特色的计算机类本科生和研究生培养计划,建立课程教学与科研培养的示范体系,全面提升北京大学计算机和人工智能学科的教育与人才培养水平,为国家培养计算机领域未来的领军人才。该计划由本科生和研究生培养两部分组成。本科生培养基于北京大学信息科学技术学院于2017年创办的“图灵班”,研究生培养计划随之于2019年立项。“图灵班”发起人之一、图灵奖得主 John Hopcroft 教授担任指导委员会主任,亲自设计培养方案及课程体系,并亲自讲授、旁听和一对一交流相关课程,确保课堂质量。