






静5前沿讲座回顾:丁剑教授谈组合统计
2022年11月2日,北京大学数学科学学院丁剑教授受邀于北京大学前沿计算研究中心做了题为“Combinatorial statistics: a common theme and a few examples”的报告,介绍的工作由丁剑教授与合作者杜航、巩舒阳、姜懿洋、刘浩宇、马恒共同完成。报告由中心邓小铁教授主持,相关内容通过蔻享学术、Bilibili 同步直播,线上线下数百人观看。

丁剑教授报告现场
丁剑教授首先解释了组合统计的概念。统计,是从数据中提取信息的一门学科,而组合统计,是说信息具有组合结构,比如对带有噪声的网络数据中复原哈密尔顿圈、匹配等问题都属于组合统计的范畴。一个经典的例子是将不同群体的学生的关系网看作一张图,去掉节点的标签信息,复原出不同的群体。

组合统计问题不仅能够将很多应用问题联系起来,同时,它也跟很多理论分支有关联,比如信息论,优化,复杂性理论等等。丁剑教授又举出一个 hidden clique 问题作为例子,这个问题需要我们在一个去标签的网络中找出具有紧密联系的群体。对于这样的问题,我们常常关注三个方面。其一是信息阈值,即当参数符合什么条件时,问题具有理想的性质;其二是计算阈值,即当参数符合什么条件时,具有理想性质实例能够在多项式时间内找出;其三是优化方面;即设计一个算法能够找到随机图中的最大团。

丁剑教授提出的第一个问题是 Lattice labeling model,对于一个 d 维格点盒子,边长为 n ,每个格点都具有一个服从 {1,2,...,q) 的均匀分布的标签。我们能够观测到所有边长为 r 的 d 维盒子内的具体标签,但不知道每个观测盒子在整体盒子的具体位置。Mossel 和 Ross 2019年的工作给出了当问题参数满足什么条件时,高概率能够复原出或者不能复原出盒子每个格点的标签,然而他们证明的阈值上下界存在 gap。丁剑教授与合作者刘浩宇证明了当 r^{d} \geq \frac{(1+\varepsilon) d \log n}{\log q} 时,高概率能够复原并存在一个多项式算法能够复原,当 r^{d} \leq \frac{(1-\varepsilon) d \log n}{\log q} 时,高概率不能复原。
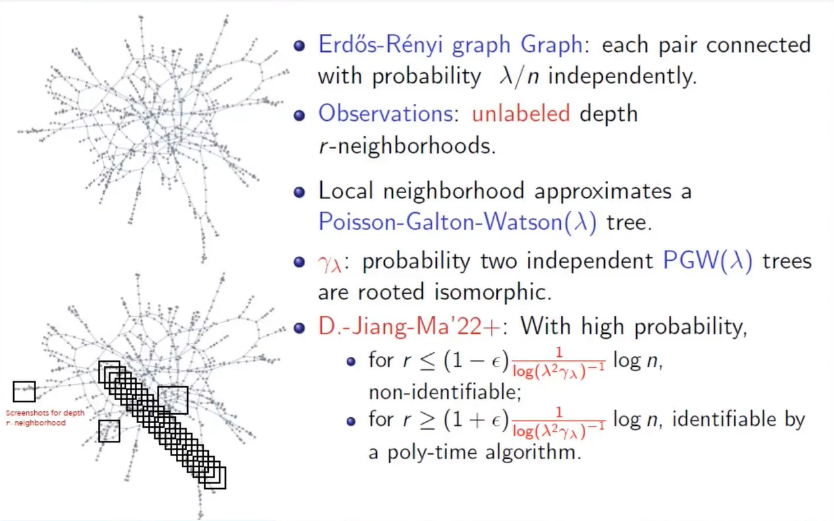
丁剑教提出的第二个问题是 sparse Erdős-Rényi graph 的重构问题。图中的每条边都以 λ/n的概率连接且各条边独立。我们能够观测到去掉标签信息的每个节点半径为 r 的邻域,目标是在同构的意义下,复原出整个图边的关系。令 γλ 是两个独立的 PGW(λ) 树根节点同构的概率。丁剑教授与合作者姜懿洋、马恒证明了当 r \leq(1-\varepsilon) \frac{\log n}{\log \left(\lambda^{2} \gamma_{\lambda}\right)^{-1}} 时,高概率无法复原,而当 r \geq(1+\varepsilon) \frac{\log n}{\log \left(\lambda^{2} \gamma_{\lambda}\right)^{-1}} 时,高概率能够复原并存在一个多项式算法能够复原。
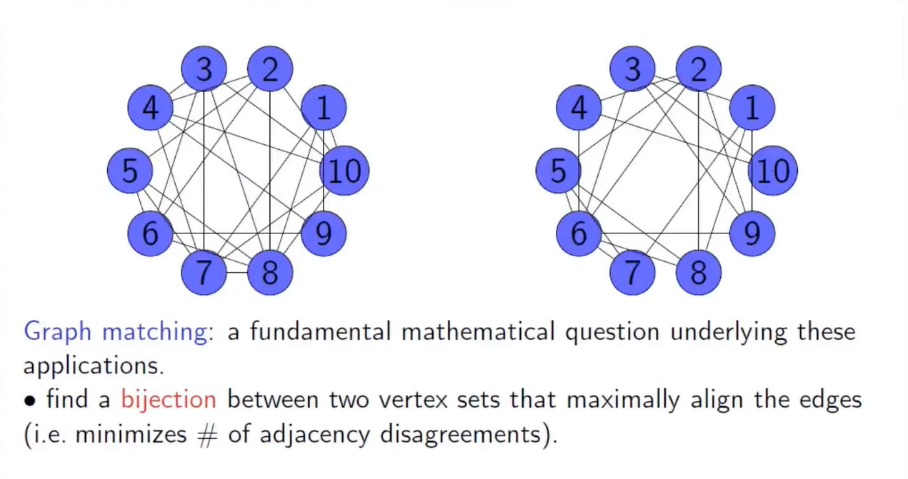
丁剑教授提出的最后一个问题是最大图匹配问题,意在对两个图的节点作一个置换,使得两个图重合的边的数量最大。这个问题在最坏情形是 NP-难的,因此丁剑教授尝试寻找有效算法对随机问题的典型情形进行求解,在这里很重要的是利用概率结构去规避极端情形。他考虑了一个 Erdős-Rényi 图作为母图,并从母图出发生成两个子图。这个问题的信息阈值又分为三种:检测阈值、全复原阈值和部分复原阈值。检测阈值已被 Wu,Xu,Yu 2020-21年的工作研究过,但仍有可提升的空间。丁剑教授与合作者杜航通过分析最大稠密子图,计算出了信息论意义下精确的检测阈值。除此之外,丁剑教授与合作者杜航也计算出信息论意义下精确的部分复原阈值。对于最大图匹配问题,丁剑教授与合作者杜航、巩舒阳提出了一个算法,并分析这个算法在 α∈(1/2,1) 时能够在多项式时间内找到近似最优解,并证明了最大重边数 ≈(2 \alpha-1)^{-1} n。在丁剑教授等人做出这个成果之前,甚至连信息论意义下的结论都是未知的。
在最后,丁剑教授指出,组合统计的许多模型在实际应用中过于理想化,比如在 Erdős-Rényi 图中假设节点具有的局部树结构在社交网络中是不合理的。丁剑教授认为组合统计在应用领域仍然面临着挑战:其一是提出应用性更强的、更有意义的模型,其二是提出更具有理论研究价值的模型。

报告现场合影