






静5青年讲座回顾:甘家瑞谈序列劝说和信息设计
2022年10月20日,来自牛津大学的甘家瑞老师带来了题为“Sequential Persuasion and Information Design”的报告,报告内容基于他们在 AAAI 2022 发表的论文 Bayesian Persuasion in Sequential Decision-Making,该论文获得 AAAI 2022杰出论文奖提名。
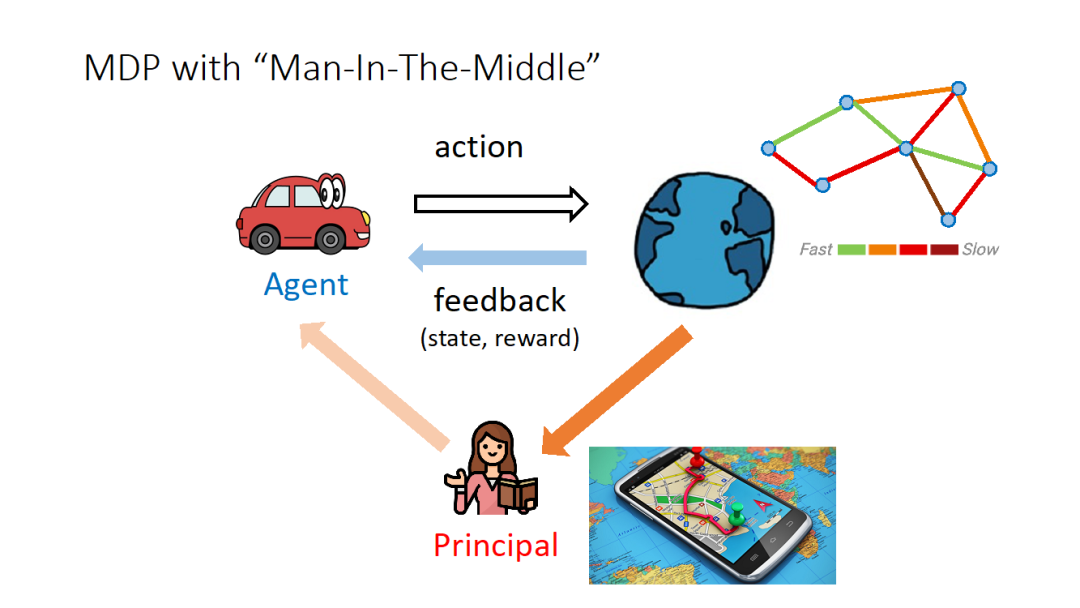
通常的多智能体问题中,智能体(Agent)基于当前状态(state),采取某个动作(action)与环境进行交互,环境则会提供给智能体相应的反馈,比如当前状态下采取该动作的奖励(reward)和新的状态。在报告考虑的场景中,存在一个拥有额外信息的委托人(Principal)。委托人拥有的额外信息可以影响智能体的奖励,他无法自己采取策略去改变环境,而是可以选择性地传递一些信息给智能体,通过影响智能体的决策,来达到改变环境的目的,提升委托人自己的收益。常见的场景包括智能体是司机,而委托人是导航 app,可提供的额外信息是道路的拥挤程度、或者推荐路线。通常,智能体和委托人的利益并不是完全一致的,所以委托人如何策略性地提供信息来尽可能最大化自己的收益,是本报告集中要考虑的问题。

在单轮的、只与环境交互一次的场景,这样的问题通常被称为贝叶斯劝说(Bayesian Persuasion)。智能体可以采取策略,它的收益由采取的动作和环境状态决定。委托人可以直接看到环境状态,却无法采取动作。贝叶斯劝说将委托人对信息的策略性泄露抽象为一个信号策略:
在博弈开始之前,委托人将公布一个信号空间(Signal space)∑ 和信号策略(signaling scheme)π 。对任意一个环境状态 Θ,π(Θ)是信号空间上的一个随机分布。然后博弈按照如下的步骤展开:
1. 环境按照一个所有人知道的分布采样出环境状态 Θ。
2. 委托人观察到环境状态 Θ 并根据分布 π(Θ) 采样出一个信号 g 公布给智能体。
3. 智能体根据获得的信号计算环境状态的后验概率,并采取最大化期望收益的动作。
4. 两个玩家获得由环境状态和智能体动作决定的收益。

甘老师在报告中以售卖草莓为例。假设大家都知道现在不是草莓的好季节,每次的草莓有70%的概率是坏的,30%的概率是好的。只有卖家知道草莓的好坏。如果买家直接计算自己的期望收益,他会选择不购买草莓。而如果卖家选择“当草莓是好草莓的时候,发送“好草莓”的信号;当草莓是坏草莓,发送“坏草莓”的信号”,买家则会在收到“好草莓”信号时购买草莓。买家买到好草莓,收益增加了;卖家卖出去了30%的草莓,收益也增加了。有策略的释放信息可以让玩家双方都获得更高的收益。使用更好的随机信号策略甚至能将期望销售量提升到60%。
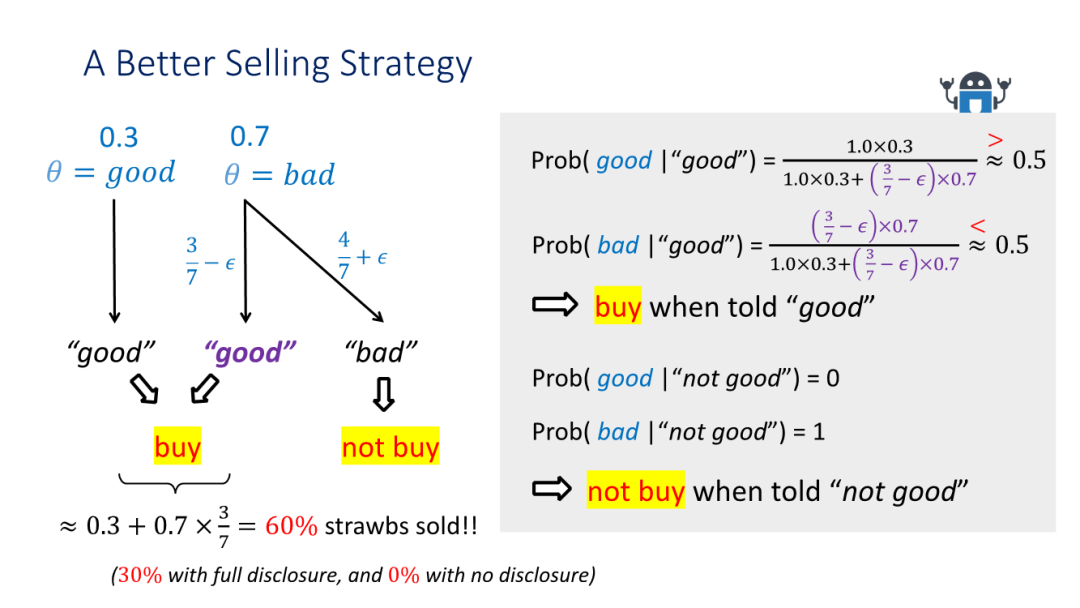
在单轮的贝叶斯劝说中,求解最优的信号策略可以通过线性规划在多项式时间内求解的。
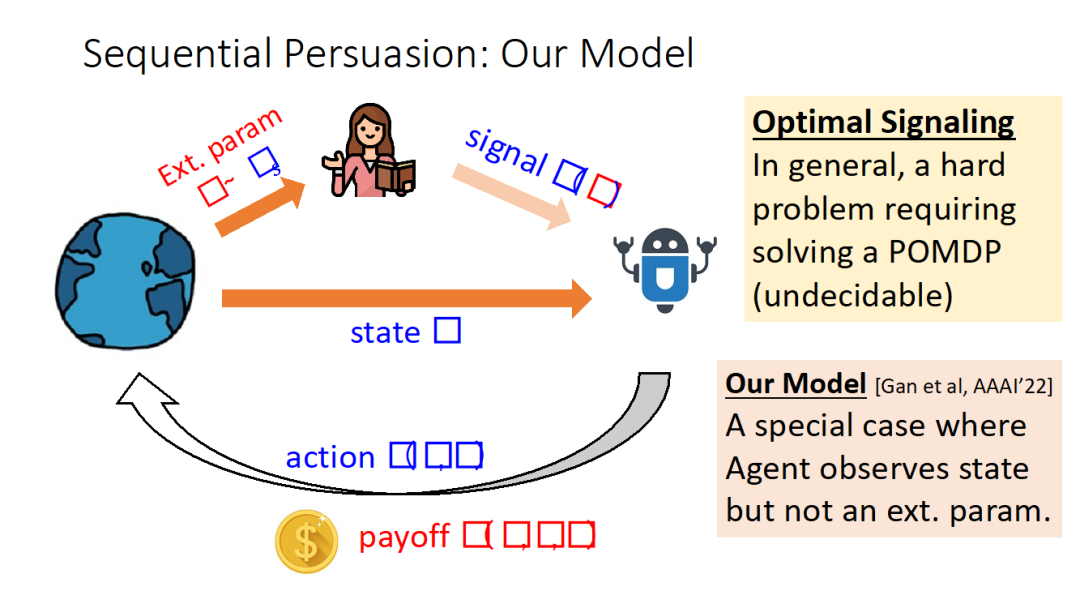
现实中更多的是与环境进行多轮交互的场景,甘老师论文中的场景考虑玩家双方都能看到环境状态,而委托人能多看到一个额外参数分布是公共知识的 Θ 。论文考虑设计基于 Θ 的最大化委托人收益的信号策略。
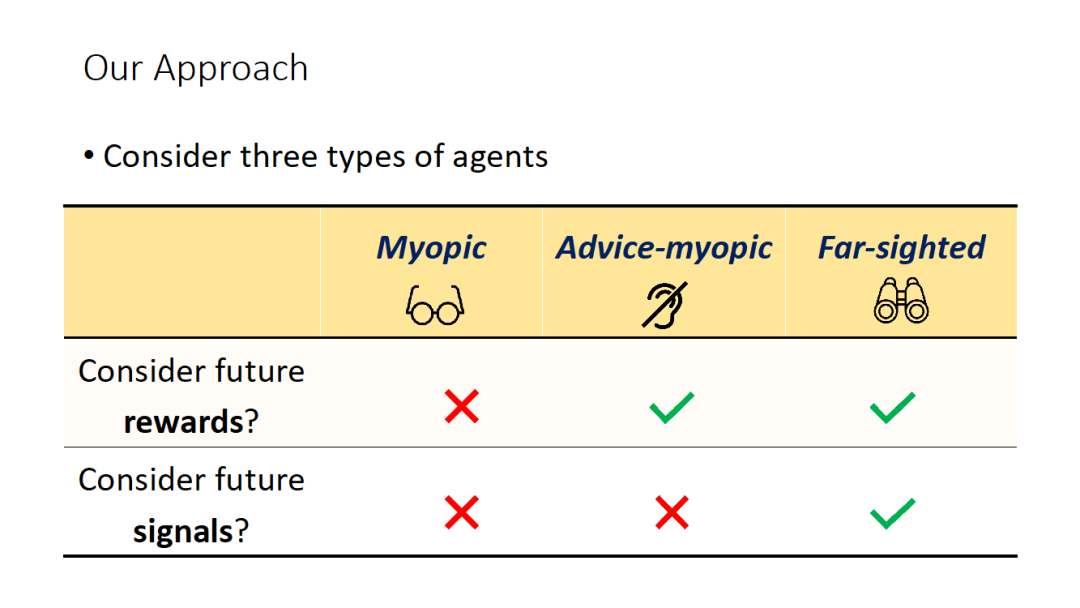
具体的,论文考虑了两种智能体:一种是短视的(myopic),在每轮只会选择基于信号最大化当前步收益;另外一种智能体则是远视的(far-sighted),会将未来的信号和收益都考虑在内。
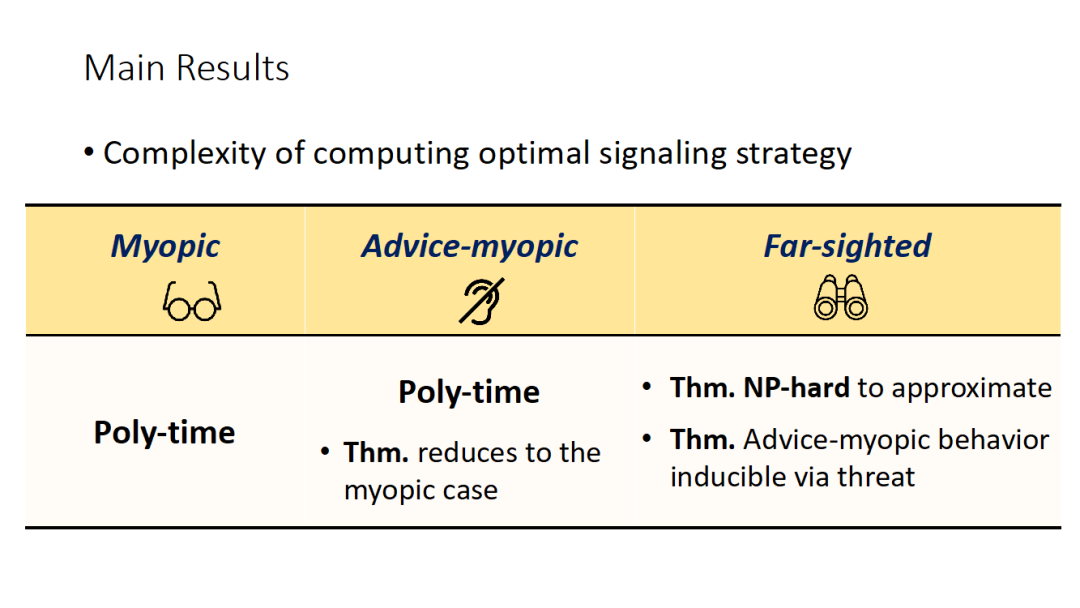
对于前一种短视的智能体,论文通过将问题建模成一个马尔科夫决策过程(Markov Decision Process)来证明该问题是多项式可解的;对于后一种远视的智能体,论文则证明了最优信号策略的计算是 NP 难的。论文进一步考虑了一种信号短视(advice-myopic)的智能体:它会考虑未来收益,但是在选择策略的时候会忽略未来的信号策略。通过将这类智能体规约到短视的情况可证明最优信号策略计算是多项式可解的。进一步,论文提供了一种威胁未来不会再给信号的手段,使得远视智能体对应的最优策略是按照对应信号策略的建议采取动作。这一策略使得委托人至少能保证自己得到当智能体是信号短视时的最优收益。
最后,报告总结了一些相关文献、已有的后续工作和一些有趣的未来方向。