






李彤阳课题组 NeurIPS 2022 入选论文解读:量子算法用于采样对数凹分布和估计归一化常数
本文是 NeurIPS 2022入选论文 Quantum Algorithms for Sampling Log-Concave Distributions and Estimating Normalizing Constants[1]的解读。该方法对数凹采样(log-concave sampling)在机器学习、物理、统计等领域有着诸多应用。本文基于朗之万扩散(Langevin diffusion)设计了新的量子算法,用于采样对数凹分布和估计归一化常数,相比最好的经典算法对于精度(ε),维度(d),条件数(κ)等参数达到了多项式级加速。本文作者包括:Andrew M. Childs(马里兰大学),李彤阳(北京大学),刘锦鹏(加州大学伯克利分校西蒙斯研究所),王春昊(宾州州立大学)和张睿哲(德州大学奥斯汀分校)。
论文地址:https://arxiv.org/abs/2210.06539
01 问题介绍
从给定的分布函数采样是一个基础的计算问题。例如,在统计中,样本可以确定置信区间或探索后验分布。在机器学习中,样本用于回归和训练监督学习模型。在优化中,来自精心挑选的样本分布可以产生接近局部甚至全局最优的点。本文考虑的问题是对数凹采样(log-concave sampling),这个问题涵盖了许多实际应用例子,例如多元高斯分布和指数分布。与之相关的一个问题是估计对数凹分布的归一化常(normalizing constant),这个问题也有许多应用,例如配分函数(partition function)的估计[2]。更多相关工作见参考文献[3, 4, 5, 6]。
02 问题模型
给定一个凸函数 f(x): R^{d} → R,且 f 是 L- smooth 和 μ-convex 的。我们定义条件数\kappa:=L/μ。我们希望从分布函数 \rho(x)=e^{-f(x)} / Z 进行采样,这里 Z=\int_{x \in R^{d}} e^{-f(x)} \mathrm{d} x 是正则化常数。给定 ε∈(0,1),
- 对数凹采样:输出一个随机变量满足分布 \tilde{\rho},使得 |\tilde{\rho}-\rho| \leq \varepsilon;
- 归一化常数估计:输出一个随机变量 \widetilde{Z},使得以至少 2/3 的概率满足(1-\epsilon) Z \leq \widetilde{Z} \leq(1+\epsilon) Z。
03 主要贡献
我们设计了新的量子算法,对于采样对数凹分布和估计正则化常数两个问题,对比经典算法在复杂度上实现了多项式级加速。
定理 1(对数凸采样)给定一个对数凹分布 ρ,存在量子算法输出一个随机变量满足分布 \tilde{\rho} ,使得:
- W_{2}(\tilde{\rho}, \rho) \leq \varepsilon,这里 W_{2} 是 Wasserstein 2-范数,对于量子访问 oracle 的查询复杂度为 \widetilde{O}\left(\kappa^{7 / 6} d^{1 / 6} \epsilon^{-1 / 3}+\kappa d^{1 / 3} \epsilon^{-2 / 3}\right);或
- |\tilde{\rho}-\rho|_{\mathrm{TV}} \leq \varepsilon,这里 \left.|\cdot|\right|_{\mathrm{TV}}是全变差距离(total-variation distance),对于量子梯度 oracle 的查询复杂度为 \widetilde{O}\left(\kappa^{1 / 2} d\right);若初始分布满足热启动条件,则复杂度为 \widetilde{O}\left(\kappa^{1 / 2} d^{1 / 2}\right)。
定理 2(归一化常数估计)存在量子算法输出一个随机变量 \widetilde{Z},使得以至少 2/3 的概率满足 (1-\epsilon) Z \leq \widetilde{Z} \leq(1+\epsilon) Z,
- 对于量子访问 oracle 的查询复杂度为 \widetilde{O}\left(\kappa^{7 / 6} d^{7 / 6} \epsilon^{-1}+\kappa d^{4 / 3} \epsilon^{-1}\right);或
- 对于量子梯度 oracle 的查询复杂度为 \widetilde{O}\left(\kappa^{1 / 2} d^{3 / 2} \epsilon^{-1}\right);若有一个热的初始概率分布(warm start),则复杂度为 \widetilde{O}\left(\kappa^{1/2}d^{1/2}\right)。
另外,这个任务的量子查询复杂度的下界是 \Omega\left(\epsilon^{-1+o\left(1\right)}\right)。
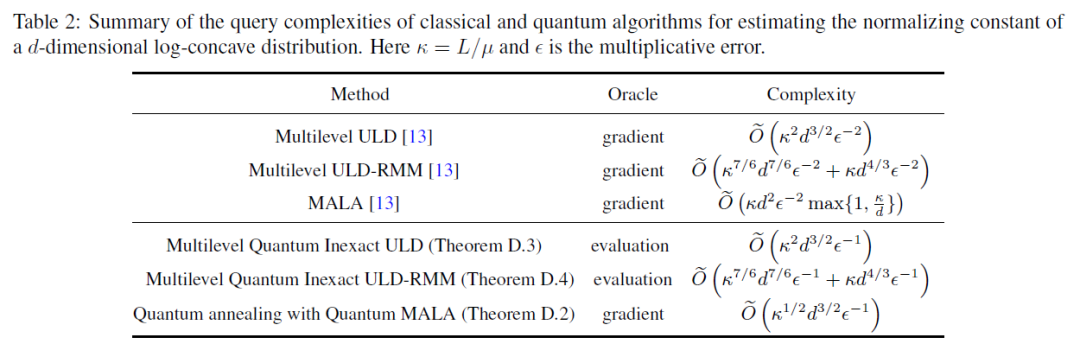
我们在表1和表2总结了我们的结果和先前经典算法复杂度的对比。

04 技术改进
我们开发了一种系统的方法来研究量子游走混合(quantum walk mixing)的复杂度,并揭示了对于任何可逆的经典马尔可夫链,只要初始分布满足热启动条件,我们就可以获得混合时间(mixing time)的平方加速。特别地,我们将量子行走和量子退火(quantum annealing)应用于朗之万动力学并实现多项式量子加速。下面简单介绍我们的技术贡献。
1. 量子模拟退火(quantum simulated annealing)。我们用于估计归一化常数的量子算法结合了量子模拟退火框架和量子平均值估计算法。对于每种类型,根据朗之万动力学(随机游走),我们构建了相应的量子游走。重要的是,随机游走的谱间隙在相应的量子游走的相位间隙中被“放大”为原先的平方。这让在给定足够好的初始状态的情形,我们使用类似 Grover 算法的过程来产生稳定分布状态。在退火框架中,这个初始状态就是前一个马尔可夫链的稳定分布状态。
2. 有效谱间隙(effective spectral gap)。我们展示了如何利用热启动的初始分布来实现量子加速用于采样。即使谱间隙很小,热启动也会导致更快的混合。在量子算法中,我们将“有效谱间隙”的概念推广到我们更一般的采样问题。我们表明使用有界热启动参数,量子算法可以在混合时间上实现平方加速。通过将采样问题视为只有一个马尔可夫链的模拟退火过程,通过分析有效谱间隙,我们证明了量子算法实现了平方加速。
3. 量子梯度估计(quantum gradient estimation)。我们将 Jordan 的量子梯度算法应用于我们的量子算法,并给出严格的证明来限制由于梯度估计误差引起的采样误差。
参考文献
[1] Andrew M. Childs, Tongyang Li, Jin-Peng Liu, Chunhao Wang, and Ruizhe Zhang, "Quantum Algorithms for Sampling Log-Concave Distributions and Estimating Normalizing Constants," to appear in NeurIPS 2022.
[2] Rong Ge, Holden Lee, and Jianfeng Lu, "Estimating normalizing constants for log-concave distributions: Algorithms and lower bounds," STOC 2020.
[3] Xiang Cheng, Niladri S. Chatterji, Peter L. Bartlett, and Michael I. Jordan, "Underdamped langevin mcmc: A non-asymptotic analysis," COLT 2018.
[4] Yin Tat Lee, Ruoqi Shen, and Kevin Tian, "Logsmooth gradient concentration and tighter runtimes for metropolized Hamiltonian Monte Carlo," COLT 2020.
[5] Ruoqi Shen and Yin Tat Lee, "The randomized midpoint method for log-concave sampling," NeurIPS 2019.
[6] Keru Wu, Scott Schmidler, and Yuansi Chen, "Minimax mixing time of the Metropolis-adjusted Langevin algorithm for log-concave sampling," 2021, arXiv:2109.13055.