






IJTCS-FAW 2022 | 机器学习理论、CSIAM分论坛精彩回顾
第三届国际理论计算机联合大会(International Joint Conference on Theoretical Computer Science-Frontier of Algorithmic Wisdom,IJTCS-FAW)由北京大学讲席教授邓小铁于2020年牵头发起,第三届于2022年8月15日-19日线上线下交互举行。大会由中国计算机学会(CCF)、国际计算机学会中国委员会(ACM China Council)、中国工业与应用数学学会(CSIAM)联合主办,香港城市大学(CityU)承办,北京大学前沿计算研究中心、北京大学人工智能研究院协办。
8月15日,大会“机器学习理论”分论坛由清华大学李建教授主持。8月19日,“CSIAM 区块链”分论坛由苏州科技大学程郁琨教授、上海交通大学博士生张梦倩主持。小编为大家带来两个分论坛报告的精彩回顾。

机器学习理论分论坛精彩回顾
李建教授主持分论坛
Unified Theory of Explaining Heuristic Findings in Attribution, Robustness, Generalization, Visual Features in a DNN
张拳石、邓辉琦,上海交通大学
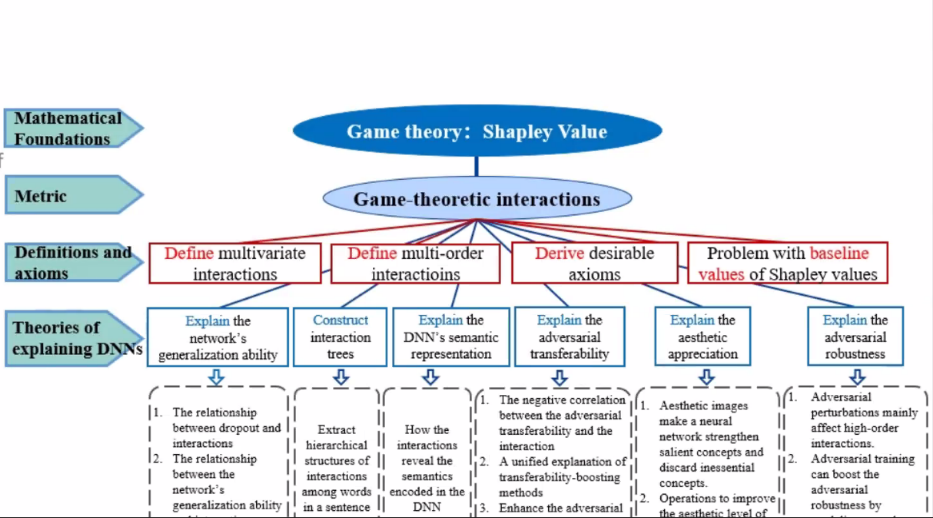
深度神经网络的可解释性,是实现可信人工智能的关键一环,受到了广泛的关注。神经网络的可解释性可大致分为:(1)概念表征的可解释性,如可视化中层神经元的语义信息;(2)表达能力(如泛化性、鲁棒性)的可解释性。然而,可解释性人工智能的发展的根本问题是,既无法理论保证概念表征的解释的严谨性,也无法从理论上打通概念表征与表达能力,从而形成一套完整的科学体系来保证相关研究的严谨性。
两位讲者首次打通了“概念表征”与“表达能力”之间的壁垒。他们提出了一个基于博弈交互(game-theoretic interactions)的理论体系,统一地解释了概念表征研究和表达能力研究中的众多经验性发现,实现了对前人经验性算法内在机理的去芜存菁以及对其根本机理的统一解释。具体地,(1)在概念表征层面,该体系导出了符号化、公理化的严谨解释,统一了现有14种经验性归因解释方法的内在机理,数学定义了神经网络所建模的视觉概念;(2)在表达能力层面,该体系统一了12种提升对抗迁移性方法的内在机理,解释了神经网络的泛化能力和对抗鲁棒性,发现并证明了神经网络的概念表征瓶颈。
Demystifying (Deep) Reinforcement Learning with Optimism and Pessimism
汪昭然,美国西北大学

目前,深度强化学习展现了前所未有的成功。神经网络的表示能力以及强化学习的决策能力相结合,使得深度强化学习已经在诸如围棋等某些任务上达到了人类顶级水平。深度强化学习带来巨大成功的同时也带给我们挑战,比如 alphaGo 训练到人类顶级水平需要与自己进行 3 x 10^{7} 场次的对战,其训练时间达到40天,这个代价是相当高昂的。而这也表明,如果数据是不充足的,那么我们训练的 AI 也并不可靠。因此我们的目标是要证明抽样效率,并且设计出抽样有效的强化学习算法。讲者基于这个问题提出了离线学习和在线学习两种模型,在离线学习的模型下,智能体只能从数据中进行学习,而并不能和环境进行交互;而在在线学习的模型下,智能体能够与环境进行交互。而对于不同的模型,讲者得出了截然相反的结论——对于离线环境的结论是悲观的,而对在线环境的结论是乐观的。
讲者假设了一种基于马尔可夫决策过程的背景,其中状态空间是无限的,而决策空间是有限的,转移矩阵和收益函数都是位置的,并且状态一定会在有限步转移到终止状态,可以用动态规划的方法把问题表示成关于 Q_{h} 和 Q_{h+1} 的 Bellman 方程,我们所要做的就是求解 Bellman 方程。
在离线环境下,我们只能从数据中学习,一个自然的算法,就是通过 Q_{h+1} 的值来对 Q_{h} 的值进行回归,这种算法也叫做 LSVI,即最小平方误差值迭代算法。在这种算法下,假设我们的数据集包含了最优策略以及对应的状态,那自然而然我们就可以学到 Q 值,但实际上算法不知道数据集是否包含这些“好数据”,如果我们期望我们学到的 Q 值在大概率意义下是一个真实 Q 值的下界,那我们就需要对回归而得的 Q_{h} 施加一惩罚项 Γ_{h} ,得到 Q_{h}^{-}=Q_{h} - Γ_{h},通过这种算法学到的 Q_{h}^{-} < Q_{h}^{*} ,因此说离线环境是悲观的。在在线环境下,智能体通过与环境交互的方式进行学习,并且有时候回报并不会在行动之后立即给出,有可能需要连续进行多轮正确的行动才能拿到回报。在数据量不足的情况下,如果我们想让算法能够发现这些潜在有价值的行动,就需要保证回归得到的 Q_{h} 不低于 Q_{h}^{*} ,这样在线环境下的 LSVI 算法可以表示为 Q_{h}^{+}=Q_{h} + Γ_{h} ,可以看到惩罚项变成了奖励项。由于我们高估的问题的真实 Q_{h} ,因此讲者说在线环境是乐观的。

讲者在最后指出,他认为之所以离线和在线环境会对值函数的估计表现出不同的特征,是因为它们的目标不同:离线环境需要保证算法的鲁棒性,而对 Q 值的悲观估计促进了鲁棒性;在线环境需要算法能够具有探索未知状态的能力,而对 Q 值得乐观估计刺激了算法对这些行动进行探索。
More Than a Toy: Random Matrix Models Predict How Real-World Neural Representations Generalize
胡威,加州大学伯克利分校

在监督学习中,训练数据集通常是从某一分布 D 中独立同分布抽样而得,我们通常用 ERM 作为损失函数,然后将监督学习建模为优化问题,期望使经验误差最小化,但这种方法对泛化误差没有任何保证,实际上泛化误差才是机器学习家们真正关心的量。在泛化理论中,机器学习的理论研究者通常使用一种叫做泛化界的东西来对泛化误差进行控制,比如 VC 维和基于范数或者边缘的一些界,但对于这些泛化界在实际中通常是虚无的,因为通过这些办法得到的界往往远大于1。神经正切核的提出以及对应的有效维度理论给这个问题带来了转机,但在高维线性回归问题上,神经正切核理论也存在着不可调和的自相矛盾。
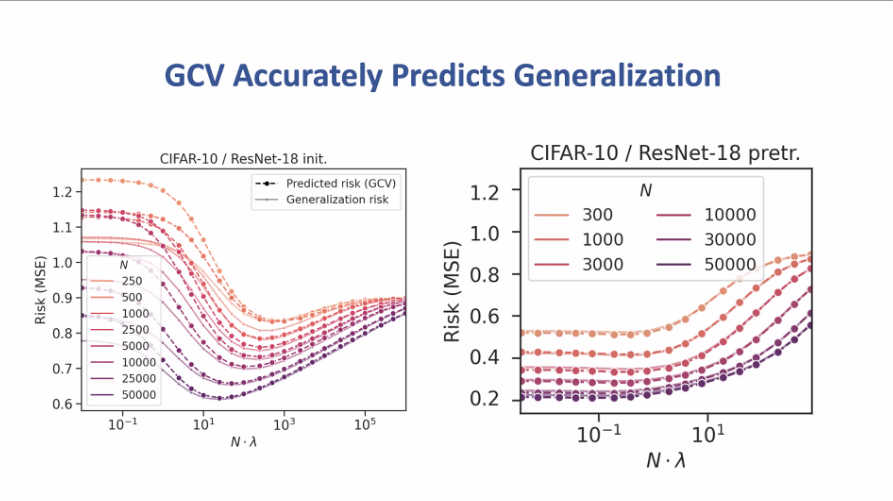
讲者认为,随机矩阵理论(RMT)能够解决这个矛盾。称 ∑ 为数据的二阶矩,而 \hat{∑} 为数据的经验二阶矩。我们不能获取 ∑ ,但可以通过数据获取 \hat{∑} 。定理表明在 RMT 的条件下,泛化误差能够被经验误差乘上一个系数很好的估计,这个系数跟 ∑ 和 \hat{∑} 的特征值有关,称这种估计为 GCV 估计。在 CIFAR10上的一系列实验中,这种估计的相对误差不超过10%,这表明了 GCV 估计在真实情况下估计泛化误差的有效性。随机矩阵理论研究的一个问题是当数据量 n 与数据维数 p 可比时,∑ 和 \hat{∑} 之间具有怎么样的性质。假如 n/p=c ,那么 \hat{∑} 特征值的分布将趋向于 Marchenko-Pastur 分布。报告还给出了局部 Marchenko-Pastur 定律,该定律说明大概率条件下, ,其中 k 为规范化子,为与 v 无关的量。报告指出,高维线性回归和机器学习泛化理论展现了类似的挑战,而随机矩阵理论对于从真实世界神经网络表示而产生的高维线性回归问题的泛化能力的刻画是有效的。
,其中 k 为规范化子,为与 v 无关的量。报告指出,高维线性回归和机器学习泛化理论展现了类似的挑战,而随机矩阵理论对于从真实世界神经网络表示而产生的高维线性回归问题的泛化能力的刻画是有效的。

CSIAM区块链分论坛精彩回顾
DAMYSUS: Streamlined BFT Consensus Leveraging Trusted Components
Jiangshan Yu, Monash University
在区块链中,由于网络延迟和恶意节点的存在,不同节点接收到的交易顺序可能不同,尤其是当双花情况出现时,如何达成共识是一个关键的问题。这一问题与经典的拜占庭将军问题非常相似,对此学者们提出了一系列共识协议,从经典的 BFT 算法(采用 all-to-all communication,每个节点需要向其他所有节点广播消息),到最近出现的包括 HotStuff 在内的 Streamlined BFT 算法(采用 all-to-one、one-to-all communication,所有节点与 leader 进行交互)和 Hybrid BFT 算法(借助可信硬件提高性能),共识算法的安全性或效率在逐步提升。在此基础上,讲者提出了一个新的共识协议 Damysus,该协议将 HotStuff 与 Hybrid BFT 方法相结合,在保证线性通信复杂的同时,进一步提升了安全性和效率。具体来说,Damysus 借助 Checker 和 Accumulator 两个可信硬件,将容错性从1/3提升到1/2、通信轮数从8减少到6。
讲者首先介绍了 HotStuff 协议的三阶段过程:准备、预提交和提交。在这三个阶段中,主节点根据至少2/3副本节点提交的最新视图、扩展块的投票、扩展块的锁定,分别生成各个阶段的 QC(Quorum Certificate)、并发送给副本节点。在接收到提交阶段的 QC 后,所有的节点会开始执行状态的转移、从而达成共识。
Damysus 在 HotStuff 的基础上,使用 Checker 存储自增的视图编号、信息类型(即所处阶段)、最新的准备好的和锁定的块,来确保每个节点不能对自己本地的最新状态撒谎,同时主节点不能向不同的副本节点发送不同的信息,从而实现更高的安全性;使用 Accumulator 保证主节点会选择最新视图的 QC,由此不再需要额外的提交阶段、减少两轮通信。
在报告的最后,讲者给出了他们实验得到的结果:与 HotStuff 相比,Damysus 的吞吐量提升了61.6%,通信延迟降低了36.6%。
Blockchain-Based Private Provable Data Possession
Huaqun Wang, Nanjing University of Posts and Telecommunications
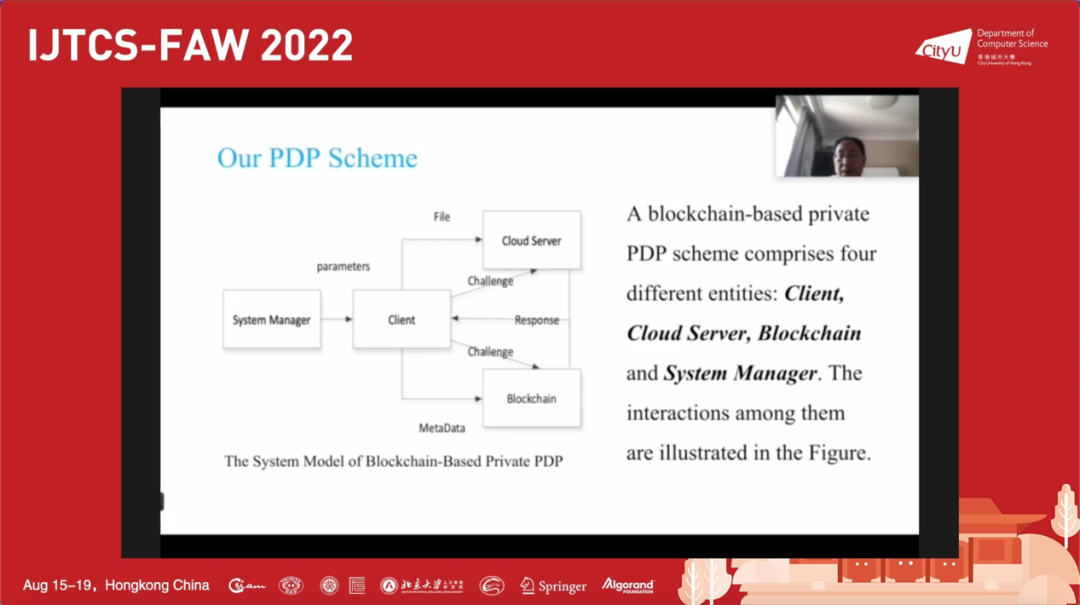
可证数据持有(Provable Data Possession,PDP)是在云存储中证明用户数据正确性、完整性的重要方式。在该报告中,讲者指出现有 PDP 设计存在空间和时间开销大、对大文件不适用的缺陷,提出用基于区块链的 PDP 方案来解决这一问题,并给出了相应的安全性分析和性能比较。
PDP 采用概率检测模型,用户仅需持有少量的元数据即可检查存储在云端的数据是否完整。讲者指出,目前的 PDP 方案主要有两种,一是基于大整数分解的难解性,二是基于双线性配对。为实现远程数据完整性检测,在上传文件时需要将文件分成多个分组、并为每个分组产生相应的标签,而现有方案在这一过程将产生巨大的计算和通信消耗,因此并不能用于实际的大文件处理。
在该报告中,讲者给出了可用于大文件的基于区块链的 PDP 方案。这一方案由用户、云服务器、区块链、系统管理员四个实体构成,具体实现包括六个阶段:首先由系统管理员生成系统参数;接着用户生成上传文件的元数据,将文件本身发送给云服务器,同时将元数据发送给区块链,云服务器负责文件本身的存储,区块链记录文件的元数据;之后当用户需要检查数据完整性时,用户会选择合适的参数发送给云服务器和区块链;云服务器需要基于该参数计算出文件完整性证明,并将该证明返回给用户;用户接收数据后,从区块链获取文件的元数据,将二者结合检查云端文件是否完整;基于检验的结果,用户可以在文件损坏时向云服务器索取赔偿。
最后,讲者给出该系统不可伪造和正确性的证明,并展示了对性能测试的结果:实验表明,该方案的数据冗余远小于其他现有方案。