






IJTCS-FAW 2022 | 机器学习与形式化方法分论坛精彩回顾
第三届国际理论计算机联合大会(International Joint Conference on Theoretical Computer Science-Frontier of Algorithmic Wisdom,IJTCS-FAW)由北京大学讲席教授邓小铁于2020年牵头发起,第三届于2022年8月15日-19日线上线下交互举行。大会由中国计算机学会(CCF)、国际计算机学会中国委员会(ACM China Council)、中国工业与应用数学学会(CSIAM)联合主办,香港城市大学(CityU)承办,北京大学前沿计算研究中心、北京大学人工智能研究院协办。
8月19日,大会“机器学习与形式化方法”分论坛如期举行,由新加坡管理大学孙军教授主持。小编为大家带来论坛精彩回顾。
QVIP: An ILP-based Formal Verification Approach for Quantized Neural Networks
张业迪,上海科技大学

在很多应用场景比如自动驾驶下, AI 的判断失误将会给社会带来巨大的损失,因此在这些场景下我们需要为 AI 的行为提供保证,AI 的鲁棒性就是这种保证的度量标准之一。具体而言,AI 的鲁棒性是指当我们给数据施加微小扰动后,AI 是否还能返回与之前一样的正确的结果。AI 的鲁棒性主要分为定性鲁棒性和定量鲁棒性,其中定性鲁棒性指的是输入在给定的扰动范围内,AI 一定能返回相同的(正确的)结果;而定量鲁棒性衡量了当我们添加的扰动服从某一分布时,AI 返回相同的(正确)结果的概率。
报告考虑了量化神经网络(QNN)上的定性鲁棒性的验证,其中 QNN 指的是网络参数以及神经元的输入输出值均不再是实数,而是 n-bit 的浮点数,即存在精度限制。由于量化精度的存在,针对同一个输入 DNN 和 QNN 的输出结果可能不同,进而针对同一个待验证的属性,两者的验证结果也会所有出入,因此以往面向 DNN 的验证工具并不能直接被用在 QNN 上。目前针对 QNN 的工作包括基于 SAT,SMT,BDD 等方法对神经网络直接编码,进而完成定性或者定量的验证。这篇工作则考虑了用整数线性规划(ILP)来对 QNN 进行定性的鲁棒性验证:给定一个基于 p- 范数的输入(扰动)空间,他们将 QNN 在该扰动空间的鲁棒性验证问题转化成一个 ILP 问题,整个转化过程保留了 QNN 的原始语义。在 MNIST 数据集上,他们的方法相比于目前最优的 SMT 方法在验证速度上有巨幅的提升。与此同时,该工作还为求解最大鲁棒半径提供了一种可行有效的方法,实验发现 QNN 的鲁棒性会随着 n 的提高而提高,讲者认为这是因为除去网络结构对可靠性的影响之外,神经网络的量化也会对可靠性产生影响,并且精度越高,这种影响就会越小。
Copy, Right? A Testing Framework for Copyright Protection of Deep Learning Models
王竟亦,浙江大学

大型的深度学习网络往往在实际中具有较好的表现,但训练它们也需要大量的花销,因此盗用别人训练好的深度学习模型成为一种更加便捷的手段,而这也会给模型的拥有者带来损失。一种防护办法是给深度学习模型加上水印,这种方法分为黑盒水印和白盒水印两种:黑盒水印不需要知晓网络的内部结构,将带有水印的数据作为训练集,同时训练模型使之给出正确的输出,如果其他模型在带有水印的数据上也能返回正确的输出,那就可以怀疑其他模型抄袭了我们的模型;白盒水印与黑盒水印的工作方式类似,但不同的是白盒水印将签名添加到模型的参数中。水印方法存在一些问题,比如水印可能会降低模型的效率,甚至会给模型带来新的安全风险。
报告给出了三种威胁深度学习网络版权的模型,一种是 fine-tuning,盗取模型后对模型参数微调;一种是剪枝方法,对模型剪枝后再进行微调操作;最后一种是将无标签的数据提供给神经网络得到有标签的数据,再利用有标签的数据进行模型训练。
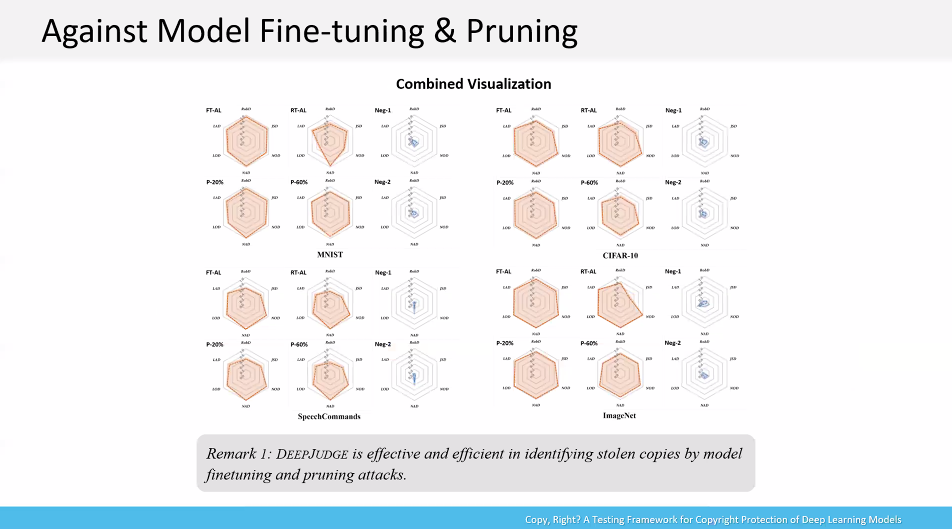
报告提出了一种测试的框架,叫做 DEEPJUDGE,这种框架能判断一个可疑模型是否抄袭了受害模型并给出证据。框架首先生成测试集来作为受害模型的指纹,这些测试集可以用攻击算法(黑盒场景)或通过激活神经元的边界行为(白盒场景)来产生,之后用这些测试集来度量受害模型和可疑模型的一系列指标,这些指标包括:鲁棒距离,神经元输出距离、激活距离,神经元层输出距离、激活距离,如果两个模型指标的相似性超过一定基准,则判断属于抄袭。实验表明在可能的抄袭手段内,如图所示,抄袭得到的模型的指标相似度远大于两个独立训练的模型的指标相似度。实验也进一步证明了该测试框架对于模型窃取攻击,以及在面对拥有防御信息的攻击者时的鲁棒性和灵活性。
最后,讲者认为报告提出的框架背后的测试思想在可信深度学习中的鲁棒性、公平性、隐私性等问题上也有潜在应用价值。同时讲者对他提出的框架的应用性仍持保留意见,因为这个框架可能需要结合一些法律上的支持,及解决在更加复杂深度学习应用场景下(比如迁移学习等)的技术问题。
Adaptive Fairness Improvement Based on Causality Analysis
Mengdi Zhang, Singapore Management University

政策的公平性是如今很重要的一个社会问题,而神经网络作为一个黑盒,其公平性难以得到考证。尽管神经网络模型本身没有偏好,但如果数据集本身存在偏差,用这些数据训练神经网络时,神经网络可能表现出歧视。对于公平性提升的主要方法,可以大概分为三类:一类公平性提升方法在预处理阶段起作用,它可以减少训练集本身带来的歧视;一类方法在处理阶段起作用,它可以调整模型来减轻模型在预测阶段带来的偏差;一类方法在后处理阶段起作用,它可以调整模型的预测结果。
为了检验公平性提升方法的有效性,讲者对这些方法进行了实验。她首先定义了群体公平性和个体公平性作为度量标准,并且在9种公平性提升方法和10种数据集上进行实验。实验表明大多数时候,公平性提升方法的确对公平性产生了正面作用,但也有降低了模型的准确度的可能,而不同公平性提升方法的效果在不同情形下亦有较大差异。在最后,报告给出了一种基于因果分析的框架来在不同的情形下选择适当的公平性提升方法。在同时考虑公平性提升和对准确率的牺牲时,其在大部分情况下能给出使公平性得到最大提升的方法。
Robust Analysis for DNNs from the Perspective of Model Learning
杨鹏飞,中国科学院软件研究所

报告主要聚焦于神经网络的局部鲁棒性,即在输入受到微小扰动的时候,会不会影响神经网络的判断。报告考虑以输入为中心的无穷范数球内的扰动,其核心问题是求解最大鲁棒半径,使得当扰动在最大鲁棒半径的范围内时,神经网络的输出不会改变。
报告介绍了四种现今已有的方法。第一种是用 SMT、MILP 等方法将问题形式化后精确求解,该方法的优点是可靠且完备,其给出的结果必为精确值,但缺点是效率低,只适用于求解小规模网络。第二种是用抽象解释的办法,对神经网络的语义做上近似,因此该方法给出的结果不会高于第一种方法给出的结果,尽管该方法时可靠的,但不完备。第三种方法是用对抗攻击的办法,寻找一个距离输入尽可能近对抗样本,该方法给出的结果不会低于第一种方法给出的结果,完备但不可靠。第四种方法是用统计的办法,允许邻域里有 ε 的测度不满足鲁棒性质,其给出的结果远大于第一种方法给出的结果,不能得到很好的鲁棒半径。之前的一篇工作用实验说明了统计方法给出的结果大约为对抗攻击办法得到的结果的5倍,讲者认为这种现象主要是高维空间的一些奇异性质所致。这四种方法得到的鲁棒半径的大小关系如图所示。

报告给出了一种崭新的方法,称为模型学习。这种方法将大模型输入和输出的行为用小模型学出来,然后在小模型上做验证,其标准和上述第四种方法类似,允许邻域里有 ε 的测度不满足鲁棒条件。但是大模型的表示能力自然强于小模型,用小模型去学一个大模型几乎是不可能的任务,但实际上只需要概率近似正确(PAC)的保证,即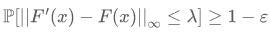 即可,这样只要我们学的小模型 F’ 距离我们需要的性质的边界有至少的距离,那么大模型自然满足我们需要的性质。
即可,这样只要我们学的小模型 F’ 距离我们需要的性质的边界有至少的距离,那么大模型自然满足我们需要的性质。
报告取小模型为线性模型,其原因有二:其一,深度网络作为一个光滑函数(如果激活函数是光滑的),则任一点的邻域是接近线性的;其二,当我们验证线性模型时,不需要担心精度的丢失和效率问题。规定小模型为线性模型之后,此时该问题就转化为求解一个最优化问题,但其约束集是不可数的。一个解决方案是我们随机从约束中采样 N 条约束(相当于在数据的邻域中以均匀分布撒点),可以证明当 N 足够大时,可以保证当有限约束问题满足时,我们有 1-η 的置信度相信无限约束问题最多只有 ε 测度的约束不满足,这样只需要通过求解一个线性规划问题,我们就可以得到具有 PAC 可靠性保障的线性模型。
最后报告给出了一系列实验,实验表明报告给出的方法得到的鲁棒半径显著小于上述第四种办法得到的鲁棒半径,但处于上述第一种办法和第三种办法得到的鲁棒半径之间。注意到第一种办法总是低估了鲁棒半径,而第三种办法总是高估了鲁棒半径,因此报告提出的办法给出的鲁棒半径结果是相当准确的。