






王鹤课题组 IROS 2022 入选论文解读:基于生成对抗演示自模仿学习的类级别泛化物体操纵
本文是 RA-L with IROS 2022入选论文 Learning Category-Level Generalizable Object Manipulation Policy via Generative Adversarial Self-Imitation Learning from Demonstrations 的解读。该论文由北京大学前沿计算研究中心王鹤课题组完成,文章研究了在 ManiSkill [1] 物体操纵数据集上的类级别泛化的物体操纵问题,并提出了一些基于生成对抗演示自模仿学习的算法用于解决该类问题。
论文地址:https://arxiv.org/abs/2203.02107
项目主页:https://shen-hhao.github.io/Category_Level_Manipulation/
01 引 言
在真实世界的复杂情景下,可泛化的物体操纵对于智能多功能机器人而言是十分重要的技能。尽管近来强化学习(reinforcement learning)取得了一定的进展,对于几何上多样化的铰接物体(articulated object)仍难以训练出可泛化的操纵策略。
在这项工作中,我们假定没有提供密集奖励(dense reward),而是仅有终点奖励(terminal reward),以此背景下使用模仿学习来实现类别泛化的物体操纵策略的学习。对于此类富有挑战的任务设定,以生成对抗模仿学习(GAIL)[2] 结合 Soft Actor-Critic (SAC) [3] 为基线算法,我们提出了一些会使模仿学习算法失效并且阻碍对于未知实例泛化的关键问题:
1. 在生成对抗的方法下多种训练实例一起学习会导致判别器的奖励减少至0,并且使模仿学习停滞;
2. 对于不同物体的演示由不同策略所生成,故用单一策略难以模仿;
3. 在训练集上策略可能会偏重部分训练实例的成功,导致策略有倾向性而不能泛化到未知实例。
我们提出了3个改进基线算法的方法:生成对抗演示自模仿学习(Generative Adversarial Self-Imitation Learning from Demonstrations),判别器的逐渐增强(Progressive Growing of Discriminator)与类级别的实例平衡专家缓冲器(Category-Level Instance-Balancing (CLIB) Expert Buffer),从而精确地解决了这些问题。在 ManiSkill [1] 物体操纵数据集上的实验和后续的消融实验验证了每一种方法的有效性以及对于类级别泛化能力的提升。
02 方法介绍

图1. 方法流程图,我们的方法基于GAIL结合SAC,橙色部分为在此之上的改进方法。
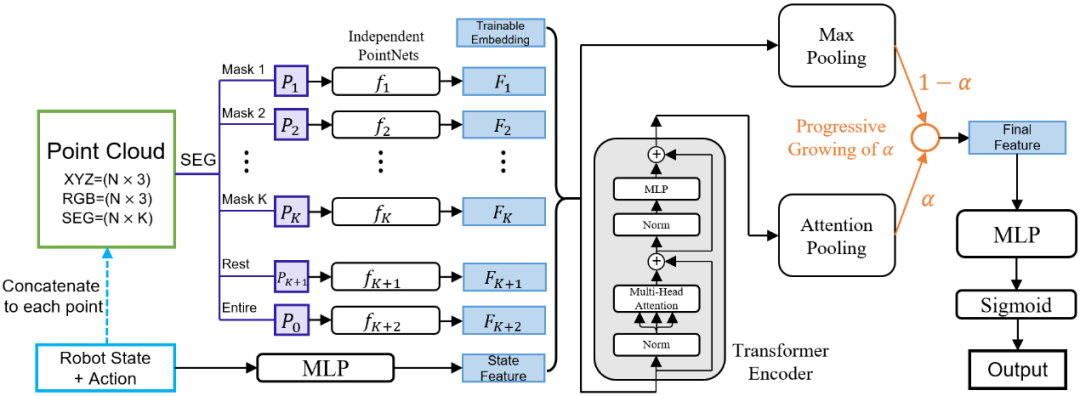
图2. 逐渐增强判别器的网络结构
判别器的逐渐增强
Progressive Growing of Discriminator
如图2所示,在训练过程中,判别器会由一个简单的初始结构逐步过渡到一个更复杂的结构以逐步提升其判别能力。我们采用了 [1] 中的 PointNet 结构作为其初始网络结构,采用了 [1] 中的 PointNet+Transformer 结构作为最终结构;图2中的 α 在训练过程中将线性地从0变化到1,从而实现结构的过渡与判别器的逐渐增强,解决了判别器在训练开始时过强的问题且实现判别器与策略的同步增长。
生成对抗演示自模仿学习
Generative Adversarial Self-Imitation Learning from Demonstrations
对于在 GAIL 中奖励会随训练下降,我们结合了 GASIL [4] 和 SILfD [5],在专家缓冲器(expert buffer)中以专家演示初始化,并且在训练过程中逐步用自我策略生成的成功轨迹填充。采用此方法后,专家缓冲器中的轨迹将逐步由自我策略生成的轨迹填充,使得轨迹数据分布更加均衡且解决了奖励函数减少至0的问题。
类级别的实例平衡专家缓冲器
Category-Level Instance-Balancing (CLIB) Expert Buffer
在使用了自模仿学习后,我们将专家缓冲器平均分为若干槽位,分布对应于每个训练实例,且以每个训练实例对应的专家演示初始化。在训练的过程中,成功的轨迹将被放入该实例的槽位中,而不是所有的轨迹放在一起。通过这种方式,我们可以控制专家缓冲器中所有成功轨迹数量的均衡,避免了某些实例轨迹占比过高从而使得模仿学习出策略带有偏向性的问题。

图3. 算法伪代码
03 实验展示
我们的方法(Method V)在 ManiSkill Benchmark [1]上极大地提升了基线算法 GAIL (Method I) [2] 的效果,在训练集与验证集上的成功率分别提高了13%和18%。详细的实验结果见下表。进一步地,我们的消融实验验证了每一项改进对于成功率和泛化能力的提升,我们还对每一项改进做了详细的分析,详细分析与结果请参见论文。
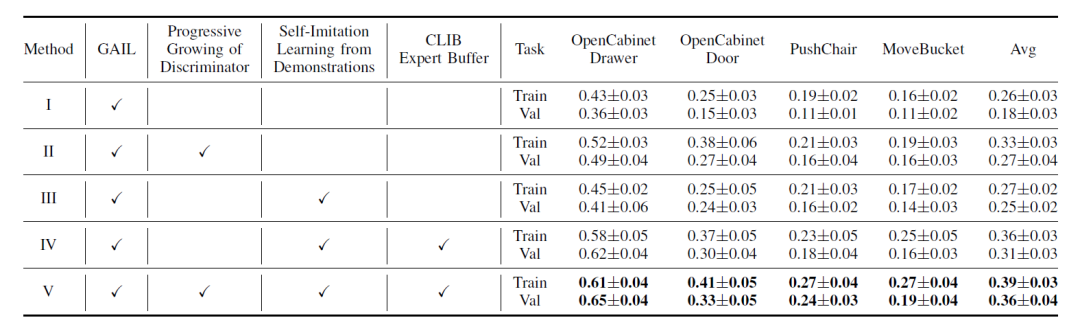
表1. 主要实验结果
同时,我们在有人工设计的环境奖励的情况下验证了我们的方法。我们的方法在有环境奖励的情况下,成功率分别在训练集与验证集上超出了基线算法7%,进一步说明了该算法的适用性。在表2中使用 GAIL+Dense Reward 的方法为我们在之前 ManiSkill 2021挑战赛无额外标注赛道获得冠军的方法(详见:王鹤团队获ICLR 2022机器人ManiSkill挑战赛无额外标注赛道冠军)。
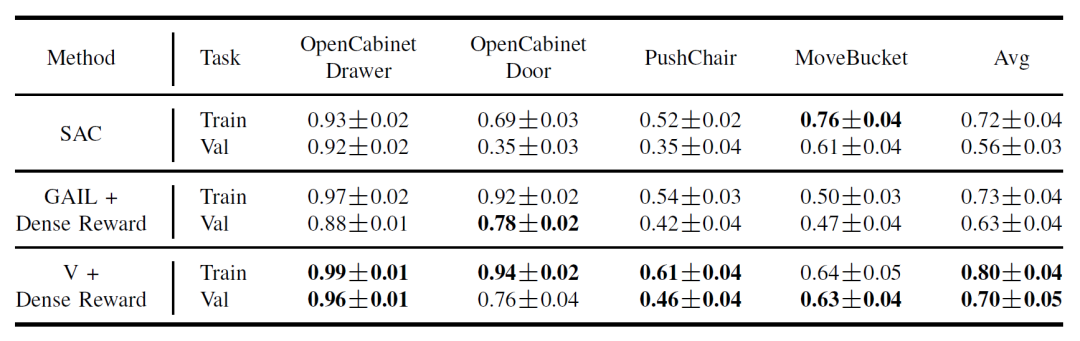
表2. 使用密集奖励的附加实验
04 结 语
本文首次通过从演示中生成对抗自模仿学习的方法来解决类别级物体操作问题,在 GAIL 基线算法之上,提出了几项提升效果的重要方法,包括将 GAIL 与 self-imitation learning from demonstrations 相结合、progressive growing of discriminator 和 category-level instance balancing buffer。我们的消融实验进一步验证了每一项改进可以使成功率和泛化能力显著地提高。
引用文献
[1] Mu T, Ling Z, Xiang F, et al. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations[J]. arXiv preprint arXiv:2107.14483, 2021.
[2] Ho J, Ermon S. Generative adversarial imitation learning[J]. Advances in neural information processing systems, 2016, 29.
[3] Haarnoja T, Zhou A, Abbeel P, et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//International conference on machine learning. PMLR, 2018: 1861-1870.
[4] Guo Y, Oh J, Singh S, et al. Generative adversarial self-imitation learning[J]. arXiv preprint arXiv:1812.00950, 2018.
[5] Pshikhachev G, Ivanov D, Egorov V, et al. Self-Imitation Learning from Demonstrations[J]. arXiv preprint arXiv:2203.10905, 2022.

IEEE/RSJ International Conference on Intelligent Robots and Systems (IEEE IROS),即智能机器人与系统国际会议,是世界机器人和智能系统领域中最著名、影响力最大的顶级学术会议之一,在世界范围内每年召开一次。IROS 2022以「共生社会的具体化人工智能」为主题, 将于2022年10月23-27日在日本京都举行。