






王亦洲课题组 ICCV 2021 入选论文解读:半监督二维人体姿态估计中的模型坍塌问题研究
本文是计算机视觉领域顶级会议ICCV2021入选论文《An Empirical Study of the Collapsing Problem in Semi-Supervised 2D Human Pose Estimation(半监督二维人体姿态估计中的模型坍塌问题研究)》的解读。
该论文由北京大学王亦洲课题组与微软亚洲研究院合作完成,研究了一致性学习算法在二维人体姿态估计中的模型坍塌问题,并提出了构建预测难度存在差异的样本对来解决该问题。本文提出的算法可以有效地利用无标记数据中的信息,显著提高了姿态估计模型的泛化能力。
论文地址:https://arxiv.org/abs/2011.12498
代码链接:https://github.com/xierc/Semi_Human_Pose
01
研究背景
二维人体姿态估计在公开数据集上的精度不断获得提升,但因为部署场景和训练数据的差异,绝大多数模型在实际使用时都会面临泛化性能降低这一挑战。半监督学习为解决这一问题提供了可能,它利用少量标注数据和大量无标注数据(比如来自实际部署场景)进行共同训练,期望提升模型在目标场景下的泛化能力。
目前半监督学习的方法中,结果最好的方法大多基于一致性训练(Consistency-based)[1][2]。也就是要求模型在一张图像的不同扰动(Perturbation)上产生一致的输出,从而去探索无标签图像中存在的特征。一致性损失如公式所示,f ( ) 代表模型输出,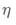 表示扰动参数。但是,目前绝大多数工作都只在分类任务上进行了算法有效性的验证。
表示扰动参数。但是,目前绝大多数工作都只在分类任务上进行了算法有效性的验证。
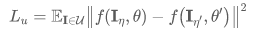
但当我们把这些方法应用到二维人体姿态估计时,我们发现大部分的一致性训练方法都遇到了模型坍塌的问题(Model Collapsing)—— 模型在有标注的图像上能够预测出正确的heatmap,但在无标注的图像上对每个像素的预测都是0。注意在这种情况下,虽然一致性损失是最小的,但模型在无标签数据上却没有学到任何有意义的信息。
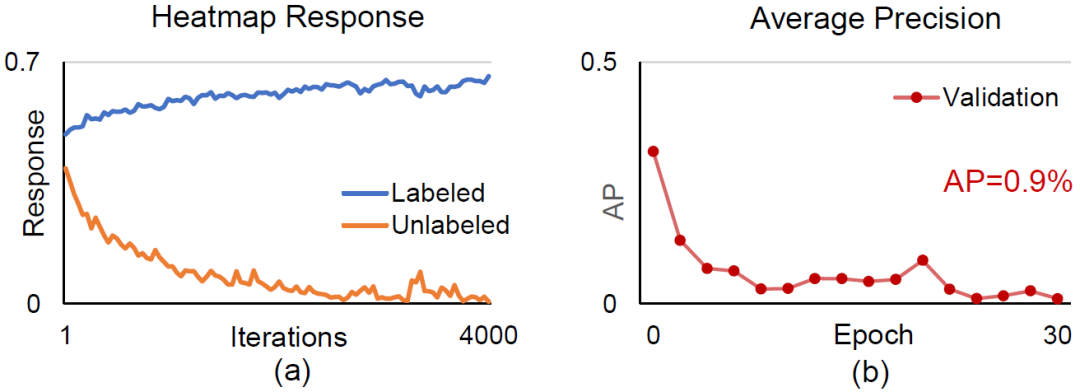
图1. 经典的一致性训练方法在二维人体姿态估计任务上的表现。(a) 预测 Heatmap 响应的变化。(b) 平均精确率的变化。
具体情况如图1 (a) 所示,随着训练次数的增加,模型在无标注数据上产生退化的输出(整张图像被预测成背景)。有意思的是模型在标注数据上依然能够产生正确的输出,这个观察意味着网络能够区分训练图像来自于无标注/有标注数据集。在图1 (b) 中,模型在验证数据集上的精度逐渐接近于0,可确认此时发生了退化。
02
问题分析
在文章里,我们通过实验对这个现象进行了深入分析,发现可能是类别不均衡问题导致的。在人体姿态估计任务中,一张图像中绝大部分像素属于背景,只有一小部分属于前景(对应关节点附近的高斯区域)。因此该任务中存在非常严重的类别不均衡问题。
当模型针对两个对应的像素(来自于两个 Perturbations)产生不一致的预测时,比如一个预测为1(前景),一个预测为0(背景)。经典的一致性训练方法中,试图同时更新两个预测值,从而移动决策边界,使得两者位于边界的同一侧。而因为类别不均衡问题的存在,决策边界倾向于移动到全局来看样本数目更稀疏的少数类别区域(也就是前景)。因此,随着训练的进行,我们发现越来越多的像素被预测成背景。图示分析可见图2。
图片
图2. (A) 进行无监督训练前的决策边界。(B) 经典的一致性训练方法试图让同一图像在不同扰动下的预测保持一致,因此该损失函数倾向于驱动决策平面移动到样本数量较少的前景区域,从而导致越来越多的像素被预测成背景。(C) 本文提出的方法,具体介绍见下文。
03
本文方法
上面的分析促使我们在计算一致性损失的时候,应该考虑两个输出的准确性,从而用相对准确的预测去监督另外一个预测。我们在统计中发现,对图像进行简单的图像增强后得到的结果要比进行困难的图像增强更准确。基于此,我们提出了一个非常简单的训练方式。
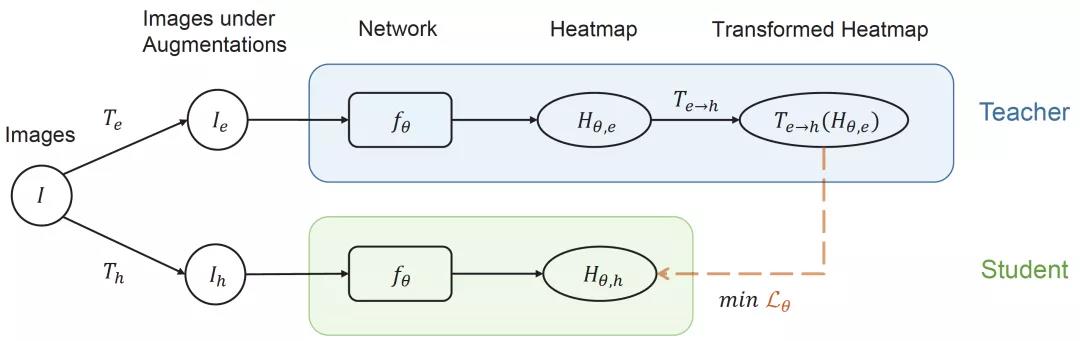
图3. 本文提出的 Easy-Hard 数据增强方法
如上图所示,针对一张无标签图像,我们分别进行一次“Easy”和“Hard”的图像增强,并将其分别输入姿态估计模型预测 Heatmap。当网络接收来自于简单增强的图像时,得到的预测值被当作 Teacher,用于监督对应的接收困难增强的图像的预测。
值得注意的是,这里的梯度传播是单向的,也就是说困难增强的图像的结果并不会去指导对应的简单增强的图像,从而尽可能降低因为错误的监督而导致模型退化的可能性。这种方法可以成功避免退化的问题,其训练过程和结果可参考图4。
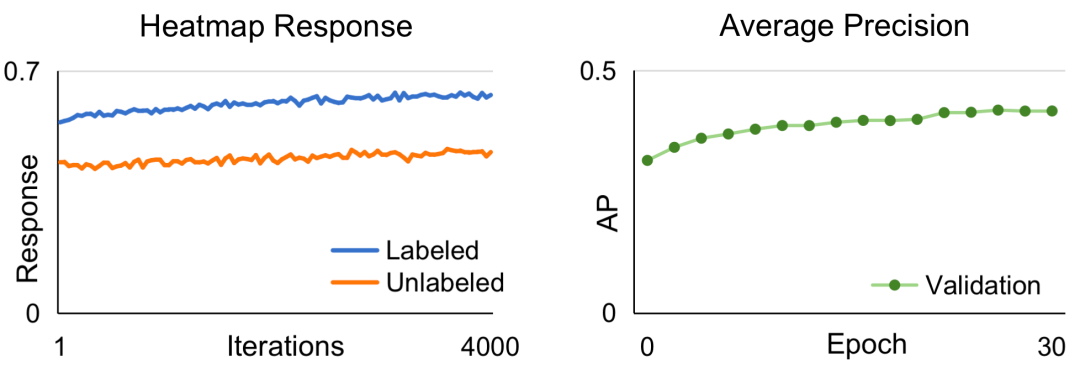
图4. 本文方法成功解决了模型退化的问题
双重网络
在 Easy-Hard 增强方法解决了模型退化问题的基础上,本文中进一步提出了双重网络的训练方式。双重网络通过增加 Teacher 和 Student 预测间的差异,来避免一致性训练过早收敛,从而提高了半监督学习的效果。
如图5所示,该方法同时训练两个参数独立且初始化不同的网络,并且在它们之间通过无标记样本来交换信息。该方法同样使用了 Easy-Hard 增强方法来避免模型退化。具体来说,模型一在简单样本下得到的预测,将用于监督模型二在困难样本下的预测。反之亦然,模型二的预测值也同样用于指导模型一的训练,两者互为教师和学生模型。
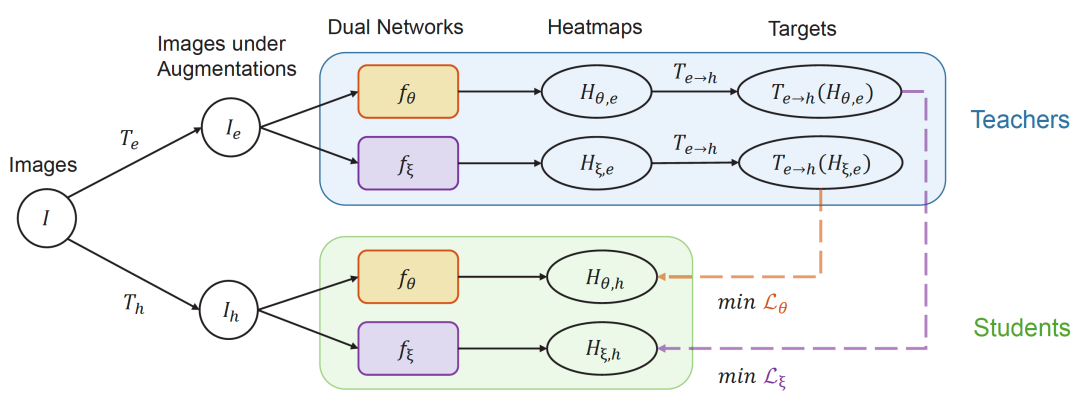
图5. 本文提出的双重网络模型
04
实验结果
我们在多个数据集和多个基线方法上进行了大量的实验,验证了本文提出的训练方式可以取得非常好的效果。
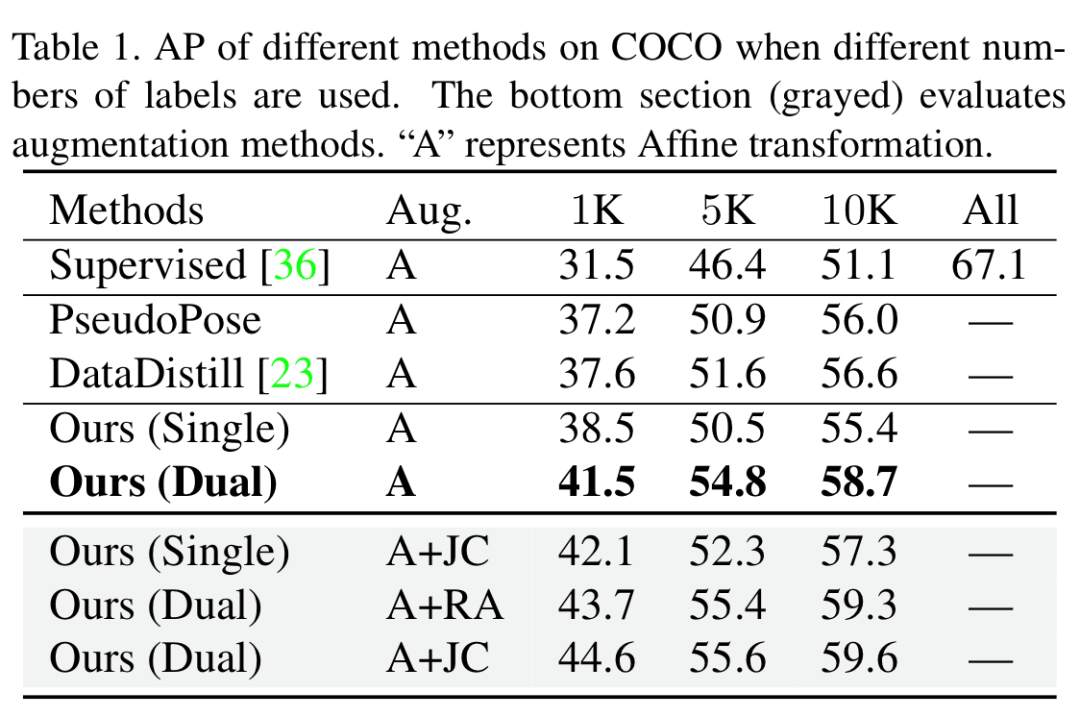
表1. COCO 数据集中半监督学习设置下的结果
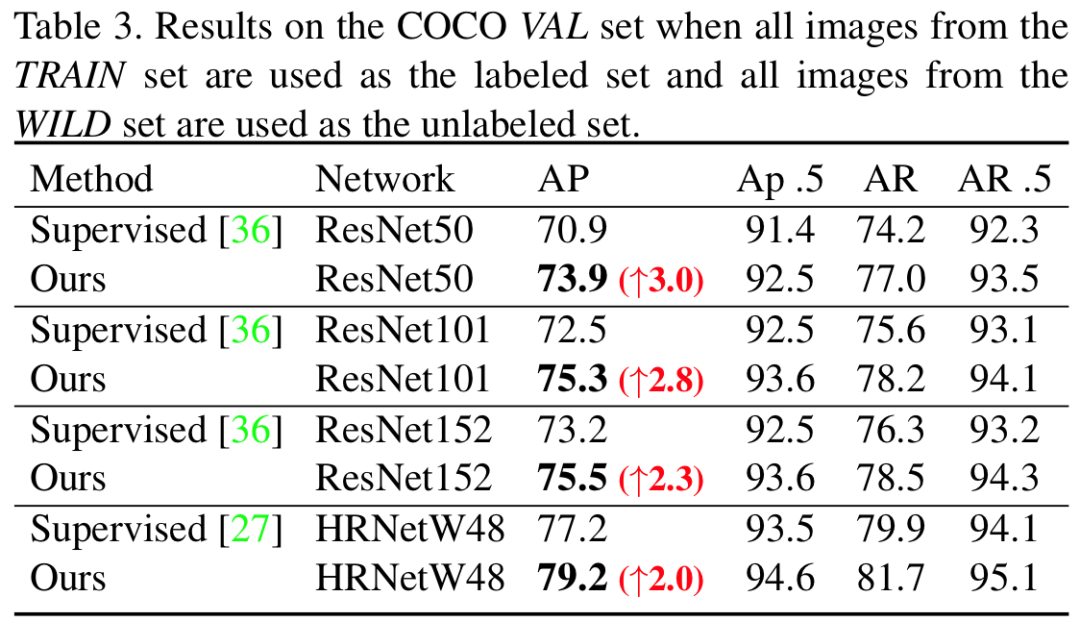
表2. COCO 数据集中使用全量标记样本,在验证集的结果
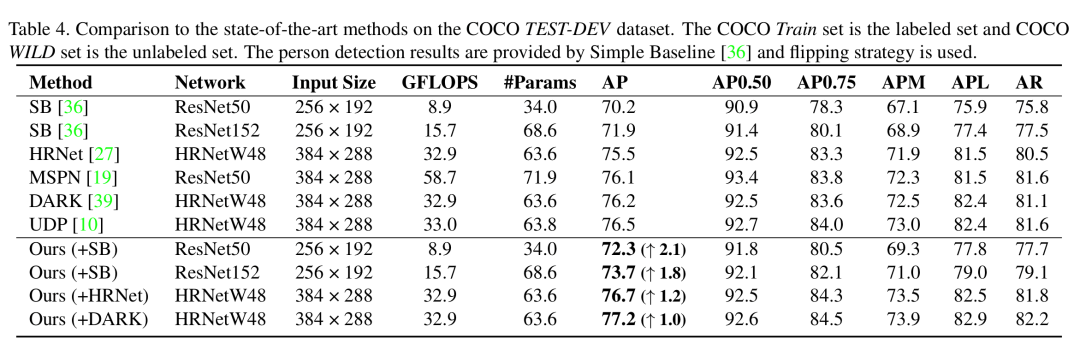
表3. COCO 数据集中使用全量标记样本,在测试集的结果
在 COCO 数据集上,当只使用少量标签数据时(表1),本文的方法大约能提升8%-13%的平均精确率。如表2、表3所示,在使用训练集的全量数据时,本文方法仍然能够增加2%-3%的平均精确率。这些结果都验证了本文方法的有效性和实用性。此外,论文中还汇报了本文方法在领域自适应,模型预训练等任务中的应用结果,也取得了较显著的改善。
参考文献
[1] Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semisupervised learning with consistency and confidence. In Advances in Neural Information Processing Systems, 2020.
[2] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems, pages 5049–5059, 2019.

IEEE International Conference on Computer Vision(IEEE ICCV),即国际计算机视觉大会,是计算机视觉领域国际顶级会议(CCF A类),与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议。ICCV在世界范围内每两年召开一次,ICCV 2021将于2021年10月11-17日在线举行。