






陈宝权课题组 ICML 2021入选论文解读:基于装配的视频无监督部件分割
本文是第三十八届国际机器学习会议(ICML 2021)入选论文《基于装配的视频无监督部件分割(Unsupervised Co-part Segmentation through Assembly)》的解读。该论文由北京大学陈宝权-刘利斌研究团队与山东大学、北京电影学院未来影像高精尖创新中心合作,提出了一种无监督的图像部件分割方法,创新性地采用了将部件分割过程和部件装配过程相结合的自监督学习思路,利用视频中的运动信息来提取潜在的部件特征,从而实现对物体部件的有意义的分割。
论文链接:https://arxiv.org/abs/2106.05897
代码地址:https://github.com/Talegqz/unsupervised_co_part_segmentation

01
引 言

部件分割 (co-part segmentation) 是计算机视觉领域中的一个重要问题。它通过识别图片中目标对象的组成部件 (part) ,并将属于每个部件的像素聚类到一起,可以为有铰链结构的物体提供较为紧凑且有意义的部件结构 (part-structure) 表示。它可以应用于运动追踪、动作识别、机器人操纵以及自动驾驶等具体任务,因而具有重要的研究价值。
随着深度学习的发展以及大量的标注数据集的出现,基于监督的学习方法已经在包括部件分割在内的很多视觉问题上超越了传统的方法。但这类学习方法往往需要大量的先验知识,并且高度依赖高质量数据集标注,较难应用到未曾见过的物体上。
在本项研究中,我们提出了一种无监督的图像部件分割方法,创新性地采用了将部件分割过程和部件装配过程相结合的自监督学习思路,利用视频中的运动信息来提取潜在的部件特征,从而实现对物体部件的有意义的分割。我们通过在人体、人手、四足动物、机械臂等不同研究对象的视频上的测试,证明了这一无监督图像部件分割方法有效性。同时,定量实验的对比也表明该方法的效果优于现有的基于无监督学习的工作,达到了较高的水平。
02
方 法
我们的方法基于一个假设,即视频中的运动物体是由不变的部件组成,视频中帧与帧的区别只是部件的不同位置和缩放之间的区别,通过部件之间的仿射变换,我们可以将视频中的一帧转换为另一帧。基于这一假设,我们利用神经网络分析两张图片之间的转换,自动将图片分割为不同的部件并学习其对应的变换方式,进而根据另一张图片的信息重新组装这些部件,从而实现无监督的部件分割。
对于单张图片来说,部件的分割装配过程如下图所示。首先,我们利用编码器把输入图片编码为部件特征和部件变换。然后,其中的部件特征将通过解码器生成相应的部件图片和部件蒙版。最后,这些部件图片将根据对应的部件蒙版被组装成最终的图片。
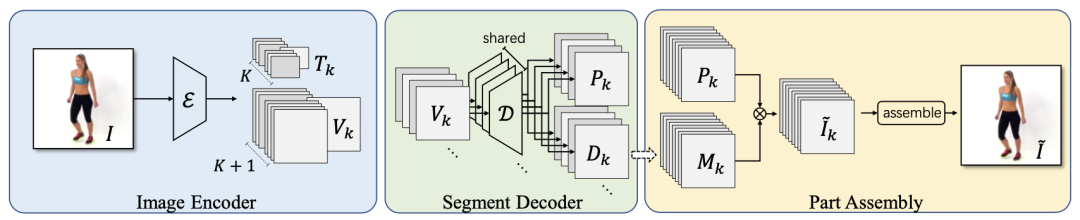
部件分割装配的结构
而在训练时,我们每次随机从视频中选择两帧作为源图片和目标图片。我们假定视频中部件都存在一个标准的特征表示,而每个部件的变换是相对于标准特征的变换。在此基础上,我们可以通过逆变换将源图片的部件特征变换到标准特征,然后再利用目标图片的变换得到新的变换特征,通过这个新的特征可以生成预测的目标图片。
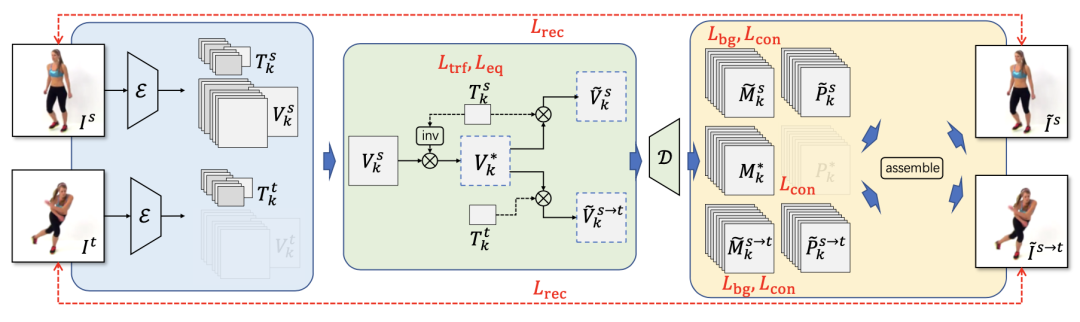
基于部件分割装配的训练过程
在训练过程中,我们要求神经网络能够尽可能地重构目标图片。由于上述组装过程的约束,只有更准确的分割才能实现更好的生成结果。因而通过这种方式,我们实现了对图片分割的自监督学习。而进一步地,我们限定变换为只包括旋转、缩放、平移的仿射变换,并且假定在标准特征空间中每个部件的中心在原点位置,同时协方差矩阵为单位矩阵。在训练中我们要求在经过变换后,部件的中心应该与变换的平移部分一致,而部件的协方差矩阵与旋转缩放矩阵一致。基于这个约束,我们可以使网络学到的部件分割和变换有更明确的物理意义,增加了结果的可解释性。
03
实验结果
我们的方法不需要任何标注,可以直接应用于人体、手、四足动物和机械臂等对象。

人手、马、人体以及机械臂的分割结果
而与其他现有的无监督方法相比,我们的方法实现了更加一致且紧凑的分割,并在分割一致性和前景准确性的定量实验上超过了现有的方法。


在 VoxCeleb 和 Tai-Chi-HD 数据集上与其他方法的对比结果
如下图所示,我们的网络可以学习到每个部件的分割,并可以将部件重新组合为输入图片。

部件分割的结果展示
每个部件的图片由解码器得到,最后组装为源图片
同时,在损失函数约束下,我们可以学习到可解释的仿射变换,其中估计的变换与每个部件运动的方向相一致。

仿射变换可解释性的对比
图片分别对应 Motion Co-part 的结果,以及我们的方法在不使用变换损失函数和使用变换损失函数下所训练的模型结果
另外,通过在较大的数据集上训练,我们的模型可以扩展到同类型的新图片上。例如下图所示,我们可将在 Tai-Chi-HD 和 VoxCeleb 等数据集上训练的模型无缝应用到在 Youtube 上找到的同类新视频上。更多细节可以参见论文及代码。


国际机器学习会议(International Conference on Machine Learning)是由国际机器学习学会(IMLS)主办的年度机器学习国际顶级会议(CCF A类),每年举办一次。ICML 2021将于2021年7月18日-24日在线上举办。