






王亦洲课题组 CVPR 2021 入选论文解读:“上下文建模”框架下的3D人体姿态估计
本文是对发表于计算机视觉和模式识别领域的顶级会议 CVPR 2021的论文 “Context Modeling in 3D Human Pose Estimation: A Unified Perspective(“上下文建模”框架下的3D人体姿态估计)”的解读。
该论文由北京大学王亦洲课题组与北京电影学院等单位合作,通过从一个宏观视角审视现有的利用肢体关节“上下文”信息辅助进行3D人体姿态估计的诸多方法,从而针对性的提出改进,使得可以很好地结合深度神经网络与人体肢体先验知识,实现对3D人体姿态更精准的估计。实验证明,该方法显著提升了未见过场景中的泛化性能。论文链接:https://arxiv.org/abs/2103.15507
01
背景介绍
利用计算机视觉技术对场景中的人进行3D姿态估计是当前重要的研究问题之一,该任务比2D姿态估计的难度更大,因为估计过程存在严重的歧义——关节点之间的相对深度未知(多个3D姿态可能对应相似的2D投影)。心理学实验表明“上下文信息”在人类视觉系统为解决歧义起着重要作用。遵循这个想法,人体关节点可以在人体姿态估计中相互充当对方的“上下文”,即估计出一个关节点的位置有助于另一个关节点的定位。例如,在距离肩膀一定的上臂长度范围内,极有可能定位到肘关节。已有诸多工作依赖于“上下文建模”方法进行人体3D姿态估计,例如图形结构模型(PSM)或图神经网络(GNN),不仅如此,也有工作探索了利用周围环境作为关节点的“上下文”,以进一步缩小搜索空间。
但是,目前没有研究对这些方法进行严格的比较。因此,本文从一个宏观视角审视现有的利用肢体关节作为“上下文”信息辅助进行3D人体姿态估计的诸多方法,推导了一个通用的基于“上下文”建模的3D人体姿态估计公式(公式1、图1),其中 PSM 和 GNN 都是其特例。

公式1. 基于“上下文”建模的通用公式
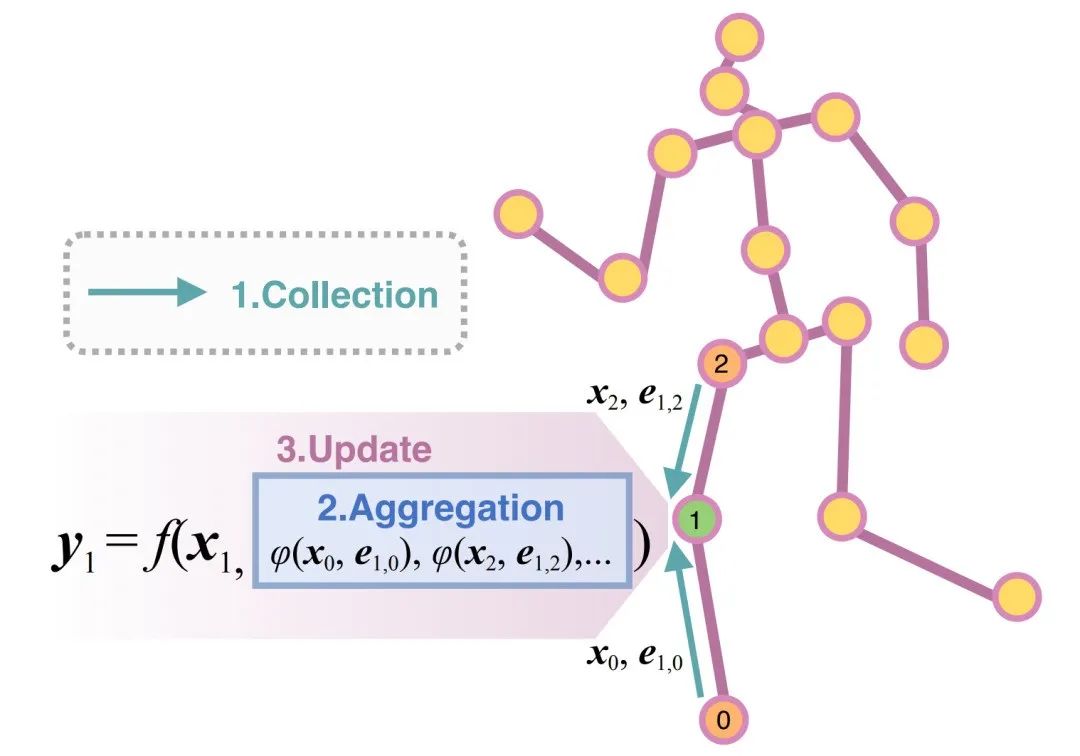
图1. 3D人体姿态估计任务中的“上下文建模”公式
在估计某一关节点的时候,首先从其“上下文”关节点(由输入的人体图结构定义)中收集特征,接着整合收集到的特征,最后利用这些特征来更新该关节点。
02
回顾PSM和GNN
一方面,PSM 是深度学习时代蓬勃发展前的用于多视角下估计人体姿态的通用模型,该方法可以被表述如下:
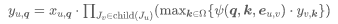
通俗地说,PSM 将人体关节点构成的骨架看做一棵树结构,通过最小化所有关节点上定义的能量函数,找到离散化三维空间中每个关节点最可能存在的体素位置。当人体结构图是无环图时,“上下文信息”从子节点流向父节点,从而利用动态规划进行优化。
另一方面,随着深度学习的发展,基于深度学习方法的全连接网络(Fully Connected Networks)和 GNN 可以通过拟合大量数据完成该任务,但是均无法利用人体所提供的丰富的先验知识,如人体肢体长度等。前期兹海等人提出的局部连接网络(Locally Connected Networks)(传送门:TPAMI 2020 | 用于单目3D人体姿态估计的局部连接网络)统一表述了 GNN 类的方法,本文对其进行了进一步重新设计,使其具有与 PSM 类似的形式:
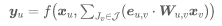
可以很容易地验证本文提出的“上下文建模”公式(公式1、图1)可以表述 PSM 和 GNN。并且通过公式可以看出 PSM 的优势在于,它可以显式地利用肢体长度约束,而 GNN 可以从大量数据中学习到隐式先验。受此启发,基于该通用公式,本文提出了 ContextPose,使得可以很好的结合 PSM 和 GNN 的优点。
03
模型概览
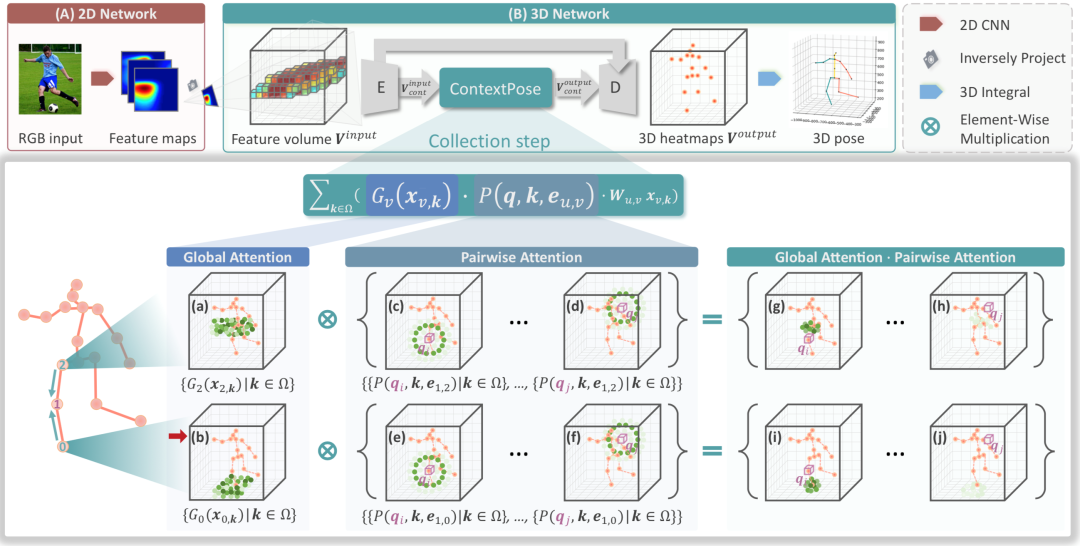
图2. 嵌入了ContextPose的3D人体姿态估计网络示意
其中着重显示了ContextPose为右膝盖关节收集其上下文关节信息的过程。
图2显示了嵌入了 ContextPose 的3D人体姿态估计模型流程。给定一个输入图像,它首先通过已有的2D网络(CNN)得到丰富的2D特征。接着利用相机参数将2D特征反投影回3D空间,构成3D特征。然后利用3D的编解码网络估计每个体素包含每个关节点的可能性(即3D关节热度图)。ContextPose 可以方便地嵌入到3D网络中,以更好地融合来自不同位置的不同关节点的特征。具体来说,它通过所有体素的“上下文关节”特征的线性组合来更新当前体素内的关节点特征。其中线性组合的权重由它们的上下文的空间关系(成对注意力)和外观(全局注意力)联合确定。图2的底部显示了 ContextPose 如何为右膝盖关节计算全局注意力和成对注意力以收集其上下文关节信息。
04
实验结论
本文在两个基准数据集上评估了本文的方法,观察到 ContextPose 达到最好水平并且具有强大的跨数据集泛化能力。表1为在 H36M,即目前最大的三维人体姿态估计基准数据集之一上的表现,评价指标是预测姿态与真实姿态的平均关节误差值,单位毫米。特别地,本文的方法比 PSM,FCN,GNN 和 LCN 的性能都要高得多,这证明了 ContextPose 上下文建模策略的有效性。
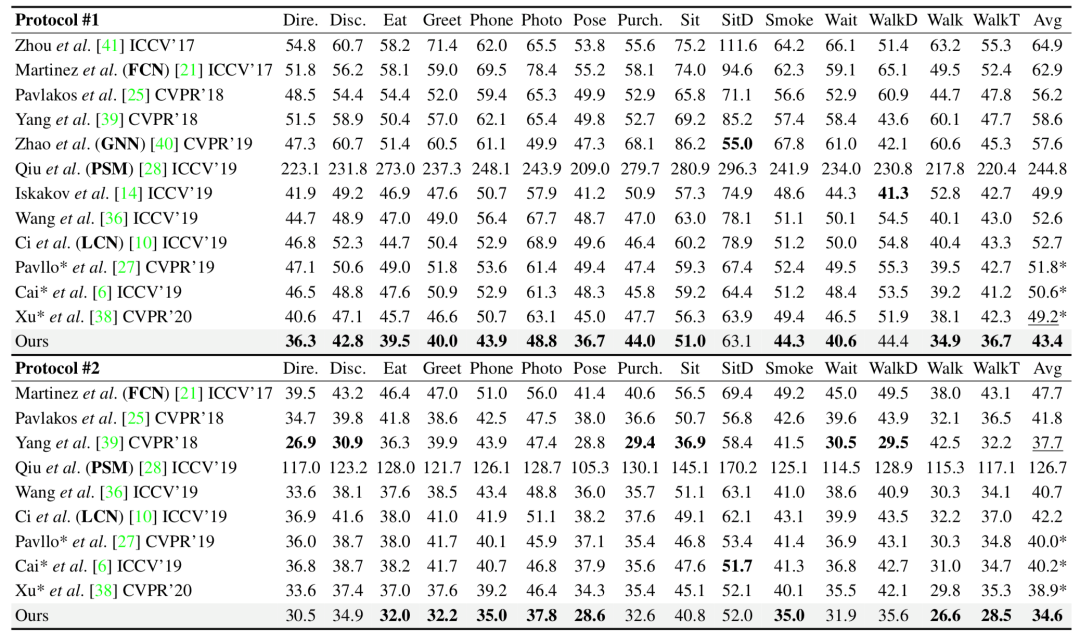
表1. 现有工作与本文的模型在H36M数据集上的定量误差结果(越小越好)
表2显示了 3DHP 数据集上不同方法的结果。在几乎所有场景中,本文的方法(未使用 3DHP 数据集进行训练)都比其他方法(包括 FCN,LCN 和 PSM)获得了更好的 PCK 和 AUC 分数,表明 ContextPose 具有很强的泛化性能,证实了结合深度网络和肢体长度先验的重要性。
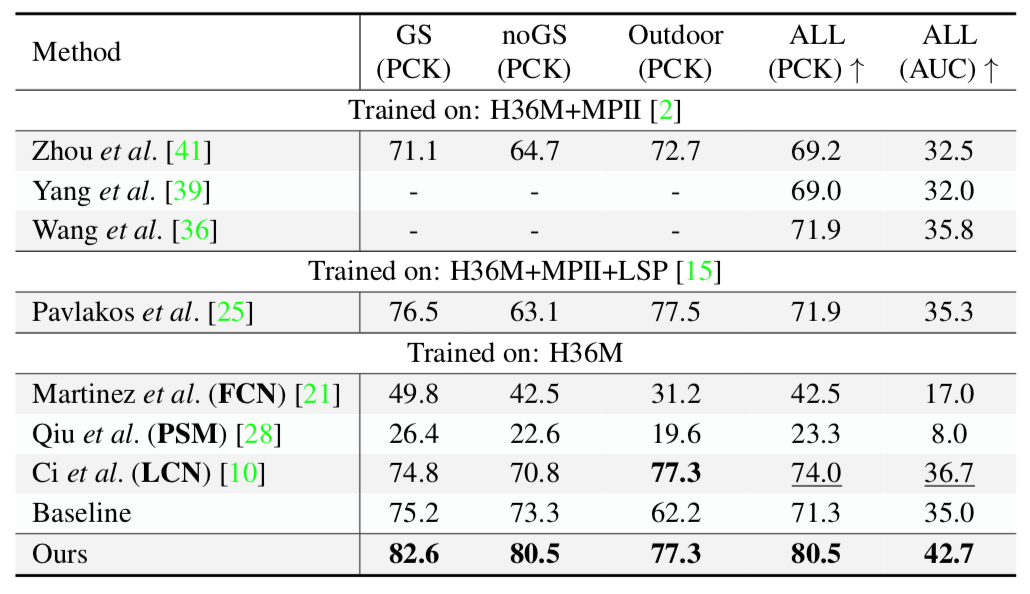
表2. 现有工作与本文的模型在3DHP数据集上的定量误差结果(越大越好)
图3为本文的模型在 H36M 和 3DHP 数据集上估计的3D姿态以及学习到的注意力(后四列随机展示了不同关节点的注意力值)。可以看到,该模型可成功泛化至背景丰富且动作较复杂的未曾见过的场景中。
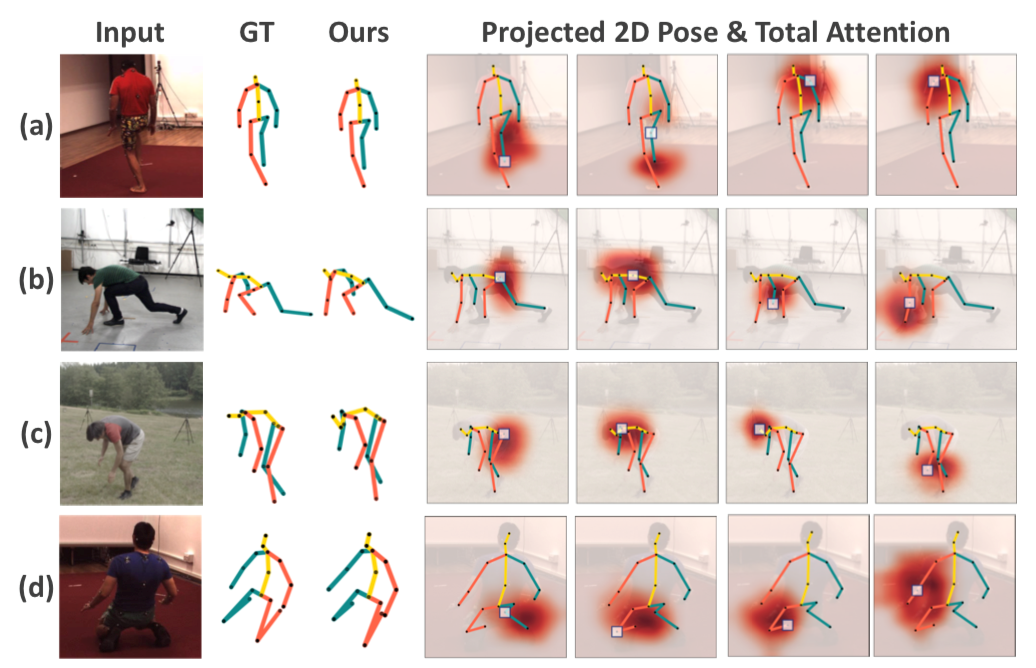
图3. 本文的模型应用在不同场景中的可视化结果
最后一行为失败案例。
05
总 结
本文首先在3D人体姿态估计任务中引入用于“上下文建模”的通用公式,该公式允许并排比较 PSM 和 GNN。基于该公式,本文提出了可以结合二者优点的 ContextPose,在深度网络中施加肢体长度的约束,并对其进行端到端的训练。该方法在两个基准上达到最优,更重要的是,它在未见过的数据集上表现出更好的泛化性能。

IEEE Conference on Computer Vision and Pattern Recognition(IEEE CVPR)是计算机视觉领域国际顶级会议(CCF A类),每年举办一次。CVPR 2021将于2021年6月19-25日在线上举行。