






陈宝权课题组 TOG 2020 入选论文解读:基于骨骼一致性的单目视频人体运动重建
本文是对 2020 年 9 月发表于计算机图形学顶级期刊 ACM Transactions on Graphics(ToG)的论文《基于骨骼一致性的单目视频人体运动重建(MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency)》的解读。该论文由北京大学与山东大学、北京电影学院、以色列特拉维夫与耶路撒冷大学合作,针对从单目视频中提取人体运动的问题,区别于直接回归关节坐标的方法,作者在神经网络中利用正向运动学,预测出时序一致的人体骨架及所对应的关节旋转,减小了网络预测的空间搜索范围,网络输出的结果也能直接运用于角色动画的驱动。
论文链接:https://arxiv.org/abs/2006.12075
项目主页:https://rubbly.cn/publications/motioNet
01
背景介绍
人体运动是现实世界中最常见的视觉内容之一,随着图像视频获取设备的大规模普及,对理解人类行为这一机器视觉任务的智能化解决变得日益重要。然而真实场景下的人体运动重建一直是一个具有挑战性的问题,人体高自由度的关节所构成的姿态难以用简单的模板进行匹配,真实场景下的复杂光照、背景也增大了这个问题的难度。
随着深度学习的发展,大量的研究工作致力于从视频序列中,通过有监督的方法预测人体三维关节坐标来表示人体运动[2]。在得到二维关键点或者图形深层特征后,通过在预测的坐标位置和真实坐标位置之间计算损失函数,将这个问题转变为回归问题。
然而,在预测过程中人体结构并未完全考虑。网络不同的关节点的预测结果来源于独立的维度,每一个关节点的预测都会在全局空间中进行搜索,没有相互之间的约束;在同一个视频的预测中,前后帧预测的骨架也会产生不一致,这不仅导致了不平滑的结果,近大远小的投影规则也导致了在深度预测上的二义性。
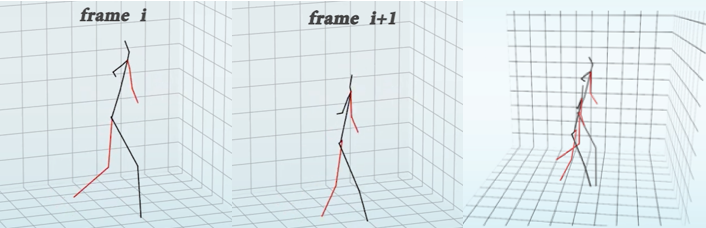
图1. 同一段预测在不同时刻的骨架相对大小 [Pavllo et al., CVPR 2019]
同时,如果想在角色动画中使用这样的数据时,首先需要利用反向运动学(Inverse Kinematics)将关节坐标点转换为对应的旋转。然而,关节位置只能描述在特定坐标维度上的信息,无法描述自身的旋转,因此这样不完整的运动信息很难直接运动于角色动画的驱动。

图2. 关节坐标位置表示方法中的二义性:同样的关节坐标可以代表不同的旋转
为了解决这些问题,本文设计了一种使用骨骼位置+动态关节旋转的方式表示人体动作的双通路网络结构,提供了以旋转为主要表达方式的人体运动重建解决方案,同时利用脚步接触信号等方式,提高了结果的可视效果。
02
方法简介
方法的核心为正向运动学,给定父关节初始位置,通过应用不同的变换方式得到子关节位置。人体的任何一个动作,都有正向运动学的参与。该过程的基本数据结构为旋转,通过不同关节之间的旋转组合,可以实现不同的人体姿态。本文通过神经网络的方式,实现了正向运动学的过程。
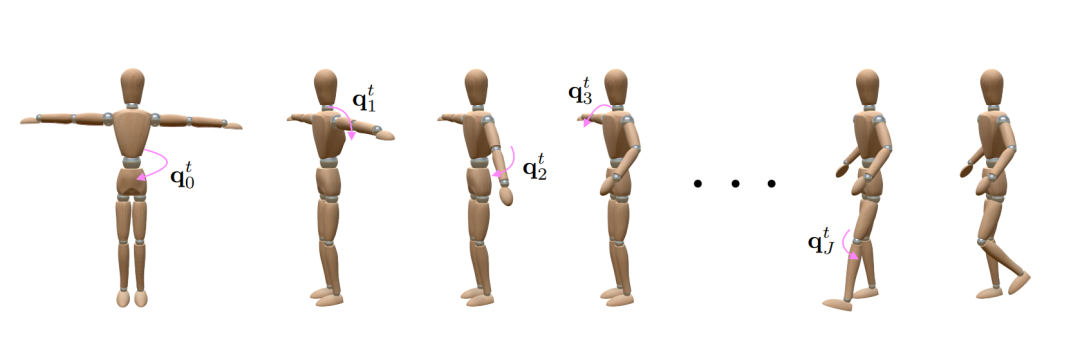
图3. 将旋转运用到T-pose上的正向运动学过程
网络由双分支的编码器组成,其中,第一个分支负责预测关节旋转、地面接触信号、全局坐标等信息,而另一个分支负责预测以骨骼长度为基本元素组合而成的初始姿态(T-pose),然后关节旋转与 T-pose 输入到正向运动学(FK)层,得到组合而成的三维动作序列。
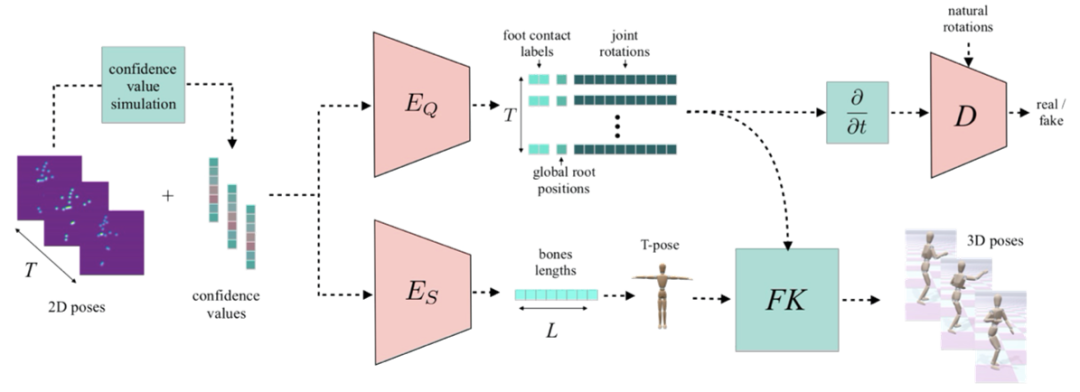
图4. 网络结构示意图
对于 T 帧的输入,第一个分支会产生 T 帧的输出,而第二个分支会通过池化的方式进行信息的压缩,只产生 1 帧输出,作为时序统一的骨架信息。在我们的解决方案中,将预测出的骨骼长度应用到固定的骨骼拓扑结构上,形成 T-pose。然后第一个分支所产生的每一帧的旋转,通过 FK 应用到时序统一的 T-pose 上,便得到了这个骨架在不同帧下的人体姿态。预测的序列通过与真实三维动作进行坐标上的误差比对,进行网络的收敛。
网络的输入是由其他方法产生的二维运动序列,在训练过程中,本文使用数据集中的真实三维运动数据,然后通过投影的方式得到所对应的二维数据。但为了适应在真实视频中因为快速运动、遮挡等因素所产生的噪音,本文在训练数据中模拟噪音的分布,将代表关节预测置信度作为网络输入的另一个维度。
为了提高生成效果的质量,除了最后关节坐标的损失函数,本文还使用了以下方法提高结果的质量:
脚步接触信号
正向运动学中骨骼链的存在,使得父关节所产生的预测误差会不断在末端关节中累积,导致了脚步滑动、末端关节抖动的问题。因此在训练过程中,我们同时预测脚步与地面的接触信号,当脚关节接触地面时,其关节运动应该相对稳定,因此预测得到的关节角速度应该接近0。
生成结果的对抗训练
本文使用旋转作为运动的表达形式,因此可以很灵活的在旋转上应用各种操纵器,满足角色动画的要求。例如本文所使用了对抗学习的方法,使得预测出的关节旋转的相对变化,尽可能接近真实的旋转。在做抬手的动作时,判别器会倾向于手部不应该出现奇怪的自旋转,从而让网络输出这样认为是“真实”的结果。
03
结果展示
在不同视频上展示的结果可以看出,本文所提出的方法具有能够从复杂背景、运动中提取出合理的三维运动的能力。

图5. 不同视频下的网络输出
与其他方法进行了定性比较可以发现,其他算法在关节位置的正确性、旋转的合理性上都存在较大的问题。尤其是在快速运动或存在遮挡的情况下,这些方法往往会出现错误的预测。

图6. 对比结果, Kanazawa [2018], Pavllo [2019], Mehta [2017]
同时,由于预测的骨架在视频前后的一致性,本文产生的结果不会在深度上产生二义性,因此相比起其他方法,本文能得到更精准的全局坐标。
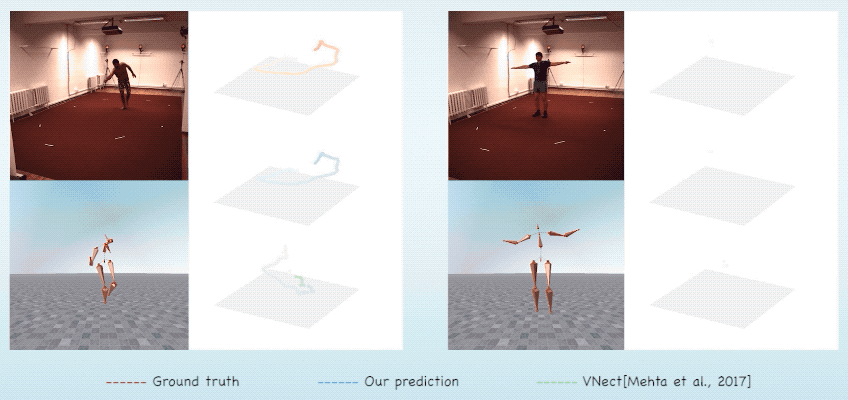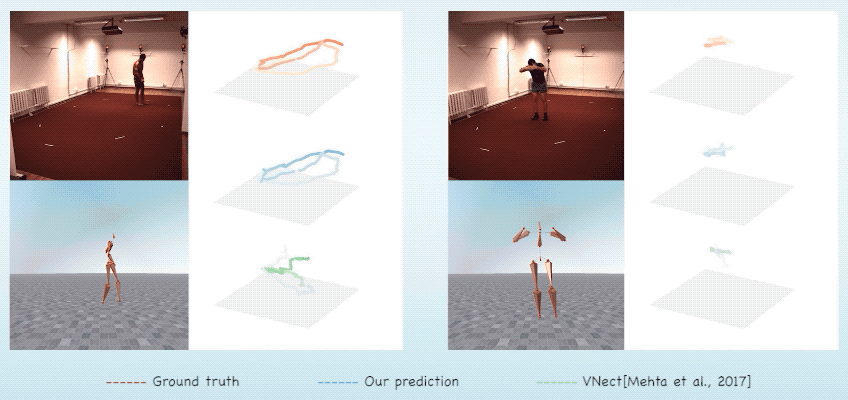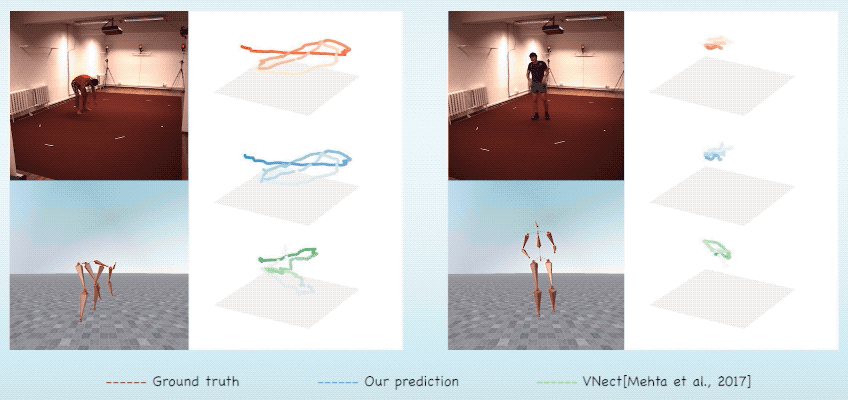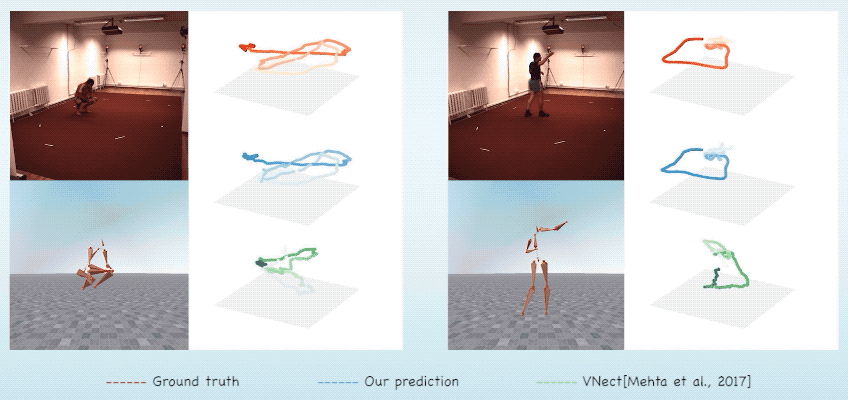
图7. 全局位置预测对比结果
参考文献
[1] Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. 2018. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. arXiv preprint arXiv:1812.08008 (2018).
[2] Pavllo, D., Feichtenhofer, C., Grangier, D., & Auli, M. (2019). 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 7753-7762).