






王亦洲课题组入选ICLR2019论文解读:你追踪我逃跑,一种用于主动视觉跟踪的对抗博弈机制
日前,第七届国际学习表征会议(The 7th International Conference on Learning Representations, ICLR 2019)公布了论文接收名单,北京大学信息科学技术学院计算机科学技术系/数字视频编解码技术国家工程实验室教授、前沿计算研究中心副主任王亦洲老师课题组共有2篇文章被接收。今天带来其中一篇《AD-VAT: An Asymmetric Dueling mechanism for learning Visual Active Tracking》的深入解读。该论文由王亦洲老师博士生钟方威、严汀沄与腾讯AI Lab研究员孙鹏、罗文寒合作,在王亦洲老师指导下完成。
ICLR是深度学习领域的顶级会议,也是国际发展最快的人工智能专业会议之一。会议采取公开评审的审稿制度,因其在深度学习领域各方面(如人工智能、统计学和数据科学),以及计算机视觉、计算生物学等重要应用领域发表和展示前沿研究成果而享誉全球。ICLR2019将于2019年5月6—9日在美国路易斯安那州新奥尔良市举行。
什么是主动视觉跟踪?
主动视觉跟踪(Visual Active Tracking)是指智能体根据视觉观测信息主动控制相机的移动,从而实现对目标物体的跟踪(与目标保持特定距离)。主动视觉跟踪在很多真实机器人任务中都有需求,如用无人机跟拍目标拍摄视频,智能跟随旅行箱等。要实现主动视觉跟踪,智能体需要执行一系列的子任务,如目标识别、定位、运动估计和相机控制等。然而,传统的视觉跟踪方法的研究仅仅专注于从连续帧中提取出关于目标的2D包围框,而没有考虑如何主动控制相机移动。因此,相比于这种“被动”跟踪,主动视觉跟踪更有实际应用价值,但也带来了诸多挑战。
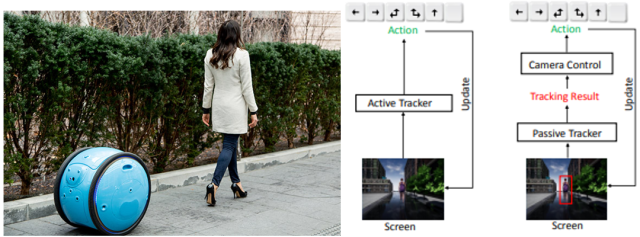
左图:一个机器人主动跟随目标移动(图片来自网络)
右图:对比基于强化学习的端到端主动跟踪和传统的跟踪方法[1]
深度强化学习是一种有前景的方法,但仍有局限性
在前期的工作[1][2]中,作者提出了一种用深度强化学习训练端到端的网络来完成主动视觉跟踪的方法,不仅节省了额外人工调试控制器的精力,而且取得了不错的效果,甚至能够直接迁移到简单的真实场景中工作。
然而,这种基于深度强化学习训练的跟踪器的性能一定程度上仍然受限于训练的方法。因为深度强化学习需要通过大量试错来进行学习,而直接让机器人在真实世界中试错的代价是高昂的。一种常用的解决方案是使用虚拟环境进行训练,但这种方法最大的问题是如何克服虚拟和现实之间的差异,使得模型能够部署到真实应用当中。虽然已经有一些方法尝试去解决这个问题,如构建大规模的高逼真虚拟环境用于视觉导航的训练,将各个因素(表面纹理/光照条件等)随机化扩增环境的多样性。
对于主动视觉跟踪的训练问题,不仅仅前背景物体外观的多样性,目标运动轨迹的复杂程度也将直接影响跟踪器的泛化能力。可以考虑一种极端的情况:如果训练时目标只往前走,那么跟踪器自然不会学会适应其它的运动轨迹,如急转弯。但对目标的动作、轨迹等因素也进行精细建模将会是代价高昂的且无法完全模拟所有真实情况。
让目标与跟踪器“斗”起来
因此,作者提出了一种基于对抗博弈的强化学习框架用于主动视觉跟踪的训练,称之为AD-VAT(Asymmetric Dueling mechanism for learning Visual Active Tracking)。在这个训练机制中,跟踪器和目标物体被视作一对正在“决斗”的对手(见下图),也就是跟踪器要尽量跟随目标,而目标要想办法脱离跟踪。这种竞争机制,使得他们在相互挑战对方的同时相互促进共同提升。当目标在探索逃跑策略时,会产生大量多种多样的运动轨迹,并且这些轨迹往往会是当前跟踪器仍不擅长的。在这种有对抗性的目标的驱动下,跟踪器的弱点将更快地暴露随之进行强化学习,最终使得其鲁棒性得到显著提升。在训练过程中,因为跟踪器和目标的能力都是从零开始同步增长的,所以他们在每个训练阶段都能够遇到一个能力相当的对手与之竞争,这就自然得构成了从易到难的课程,使得学习过程更加高效。然而,直接构造成零和游戏进行对抗训练是十分不稳定且难以收敛的。
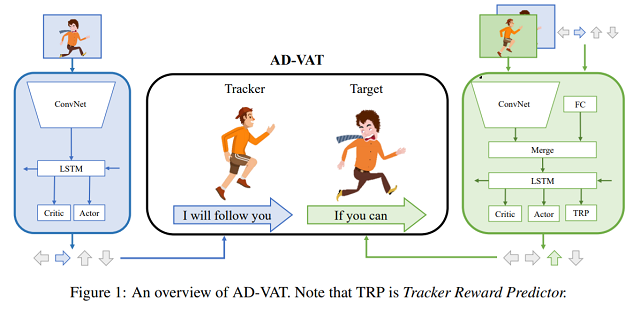
如何让对抗更加高效且稳定?
为解决训练的问题,作者提出了两个改进方法:不完全零和的奖赏函数(partial zero-sum reward)和用于目标的跟踪可知模型(tracker-aware model)。
不完全零和奖赏是一种混合的奖赏结构,仅鼓励跟踪器和目标在一定相对范围内进行零和博弈,当目标到达一定距离外时给予其额外的惩罚,此时将不再是零和博弈,因此称之为不完全零和奖赏。这么设计奖赏函数是为了避免一个现象,当目标快速远离跟踪器时,跟踪器将不能观察到目标,以至于训练过程变得低效甚至不稳定。
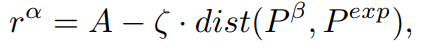
上式为跟踪器的奖赏函数,沿用了[1]中的设计思想,惩罚项由期望位置与目标之间的距离所决定。
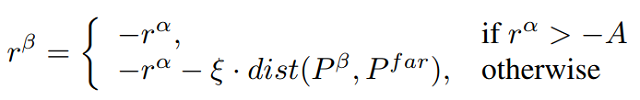
上式为目标的奖赏函数,在观测范围内,目标与跟踪器进行零和博弈,即奖赏函数为跟踪器的奖赏直接取负。在观测范围外,将在原来的基础上得到一个额外的惩罚项,惩罚项的取值取决于目标与跟踪器的观测边界的距离。
跟踪可知模型是为了让目标能够针对跟踪策略学会更优的对抗策略,所谓“知己知彼,百战不殆”。具体的,除了其自身的视觉观测外,还额外获得了跟踪器的观测和动作输出作为模型的输入。为了更好地学习关于跟踪器的特征表示,作者还引入了一个辅助任务:预测跟踪器的即时奖赏值。
基于以上改进,“决斗(Dueling)”双方在观测信息、奖赏函数、目标任务上将具备不对称性(Asymmetric),因此将这种对抗机制称之为“非对称决斗(Asymmetric Dueling)”。
实验设置
作者在多种不同的2D和3D环境开展了实验以更进一步验证该方法的有效性。2D环境是一个简单的矩阵地图,用不同的数值分别表示障碍物、目标、跟踪器等元素。作者设计了两种规则生成地图中的障碍物分布(Block, Maze)。作者设计了两种基于规则的目标运动模型作为基准:漫步者(Rambler)和导航者(Navigator)。漫步者是随机从选择动作和持续的时间,生成的轨迹往往在一个局域范围内移动(见Block-Ram中的黄色轨迹)。导航者则是从地图中随机采样目标点,然后沿着最短路径到达目标,因此导航者将探索更大范围(见Block-Nav中的黄色轨迹)。
将这些不同种的地图和目标依次组合,构成了不同的训练和测试环境。作者只用其中的一种地图(Block)用作训练,然后在所有可能的组合环境中测试,从而证明模型的泛化能力。
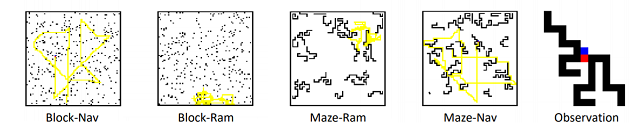
3D环境是基于UE4和UnrealCV[3]构建的虚拟环境。作者只用一个采取域随机技术(环境中物体表面纹理、光照条件都可以进行随机设置)的房间(DR Room, Domain Randomized Room)进行训练,然后在三个不同场景的近真实场景中测试模型的性能。

实验结果
在2D环境中作者首先验证了AD-VAT相比基准方法能够带来有效提升,同时进行了消融实验来证明这两个改进方法的有效性。
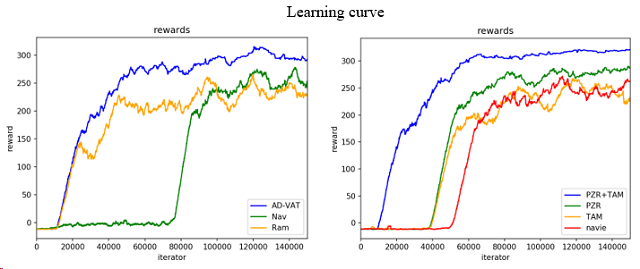
左图左为AD-VAT(蓝线)和基准方法在2D环境中的训练曲线,可见AD-VAT能够让跟踪器学得更快更好。右图为消融实验的结果,对比删减不同模块后的学习曲线,作者提出的两个改进方法能够使对抗强化学习的训练更高效。
作者在3D环境中的实验更进一步证明该方法的有效性和实用性。
在训练过程中,作者观测到了一个有趣的现象,目标会更倾向于跑到背景与其自身纹理接近的区域,以达到一种“隐身”的效果来迷惑跟踪器。而跟踪器在被不断“难倒”后,最终学会了适应这些情况。

作者对比了由AD-VAT和两种基准方法训练的跟踪器在不同场景中的平均累计奖赏(左图)和平均跟踪长度(右图)。其中,雪乡(Snow Village)和地下停车场(Parking Lot)是两个十分有挑战性的环境,每个模型的性能都有不同程度的下降,但该论文提出的模型取得了更好的结果,说明了AD-VAT跟踪器对复杂场景的适应能力更强。
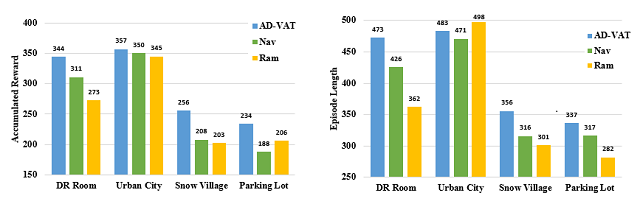
雪乡主要的挑战在于地面崎岖不平,且相机会被下落的雪花,逆光的光晕等因素干扰导致目标被遮挡:

停车场中光线分布不均匀(亮暗变化剧烈),且目标可能被立柱遮挡:

更多细节和实验结果请参考原文:https://openreview.net/forum?id=HkgYmhR9KX
参考文献:
[1] Wenhan Luo*, Peng Sun*, Fangwei Zhong, Wei Liu, Tong Zhang, and Yizhou Wang. End-to-end active object tracking via reinforcement learning, In ICML 2018.
[2] Wenhan Luo*, Peng Sun*, Fangwei Zhong*, Wei Liu, Tong Zhang, and Yizhou Wang. End-to-end active object tracking and its real-world Deployment via reinforcement learning, In TPAMI 2019 (in press).
[3] Weichao Qiu, Fangwei Zhong, Yi Zhang, Siyuan Qiao, Zihao Xiao, Tae Soo Kim, Yizhou Wang, and Alan Yuille. Unrealcv: Virtual worlds for computer vision. In ACM-MM 2017.