






王亦洲课题组入选TPAMI论文解读:从虚拟到现实,一种基于强化学习的端到端主动目标跟踪方法
近日,北京大学王亦洲老师课题组与腾讯AI Lab合作论文《End to end Active Object Tracking and Its Real world Deployment via Reinforcement Learning》被人工智能顶级国际期刊TPAMI接收。该研究也入选了2018腾讯AI Lab犀牛鸟专项研究计划。该论文主要提出了一种基于强化学习的端到端主动目标跟踪方法,通过自定义奖赏函数和环境增强技术在虚拟环境中训练得到鲁棒的主动跟踪器,并在真实场景中对模型的泛化能力进行了进一步的验证。
IEEE Transactions on Pattern Analysis and Machine Intelligence(IEEE TPAMI)是人工智能领域最顶级国际期刊(CCF A类,SCI一区,2017年影响因子9.455),对论文的原创性有很高的要求,并以严苛的审稿过程著称,每年收录的论文数量十分有限。
简介
主动目标跟踪是指智能体根据视觉观测信息主动控制相机的移动,从而实现对目标物体的跟踪(与目标保持特定距离)。主动视觉跟踪在很多真实机器人任务中都有需求,如用无人机跟拍目标拍摄视频,智能跟随旅行箱等。然而,传统的实现方法是将图像中的目标跟踪和相机控制分成两个独立的任务,这导致系统在进行联调优化时变得繁琐复杂。此外,要单独实现这两个任务的代价也是高昂的,既需要大量人工标注目标位置用于训练跟踪模块,也需要在真实系统中通过试错整定相机控制器参数。
为了解决上述问题,本文提出一种基于深度强化学习的端到端的解决方案,即用一个Conv-LSTM神经网络直接将图像序列输入映射成控制信号输出(如前进、左转等)。为了避免人工标记数据和在真实环境试错,我们使用仿真环境进行训练。我们进一步提出了一种环境增强技术和自定义的奖赏函数,以保证训练得到一个鲁棒的端到端主动跟踪器。
实验证明,在仿真环境训练得到的跟踪器能取得很好的泛化能力,在没见过的目标外观、移动轨迹、背景外观和干扰物体出现等情况下都能较稳定工作。当目标偶然消失时,跟踪器也能鲁邦地恢复跟踪。我们还发现,这种只在仿真器中训练得到的主动跟踪器是有可能直接迁移到真实场景中工作的。我们分两阶段实验,验证了这种虚拟到现实迁移的能力。首先,我们在VOT数据集进行了定性测试,即观察动作输出的合理性。最终,我们系统解决了虚拟到现实的问题,将主动跟踪器成功部署在真实移动机器人上,并进行了定量测试。
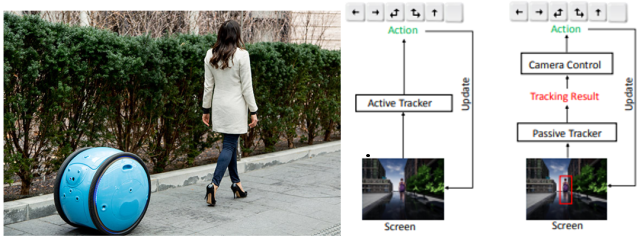
左图:一个机器人主动跟随目标移动(图源:网络)
右图:对比基于强化学习的端到端主动跟踪和传统的跟踪方法
主要贡献
论文的主要贡献包括:
1. 一种基于强化学习的端到端主动目标跟踪的方法;
2. 设计了一种用于主动跟踪的奖赏函数用于训练,并采用环境增强技术提升模型泛化能力;
3. 第一个实现将端到端主动跟踪器从虚拟环境迁移部署到现实世界。
本文以之前会议版本(ICML2018)的论文[1]为基础,主要扩展实现了从虚拟到现实的迁移(第三点贡献),即提供了将在虚拟环境中训练获得的端到端跟踪器成功部署在真实机器人上的实现方案。具体地,为了克服因虚拟与现实之间的差异带来的挑战,我们主要考虑解决以下三个问题:
1. 如何进一步增强环境来提升模型的泛化能力?
2. 什么样的动作空间更适合真实机器人?
3. 如何将网络输出的动作映射成真实的控制信号?
主要方法介绍
首先我们生成了大量的虚拟跟踪场景用于训练和测试。然后,我们采用Conv-LSMT网络结构实现端到端的映射(输入图像,输出动作),并用经典的强化学习算法A3C[2]进行训练。为了保证训练的鲁邦性和有效性,我们提出了环境增强方法和设计了奖赏函数。具体的介绍如下:
跟踪环境
强化学习的训练需要大量试错,这导致在真实环境下训练主动跟踪器基本上是不可能的。因此,我们基于两种游戏引擎(VizDoom 和 Unreal Engine)分别构建了不同的跟踪场景用于训练和测试,如下图所示:
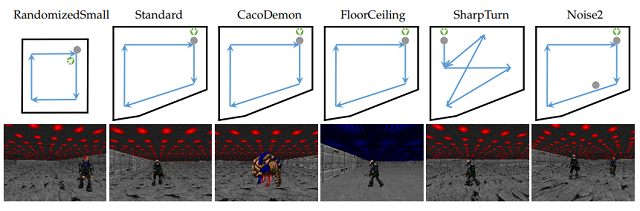
Vizdoom环境的地图和示例。其中,绿色点代表跟踪器(箭头代表方向),灰色点代表目标,蓝线代表规划的目标的路径,黑线代表墙壁。最左边的场景为训练环境,其余场景为测试环境,包含了不同的目标轨迹、目标外观、背景颜色,以及干扰物体等情况。
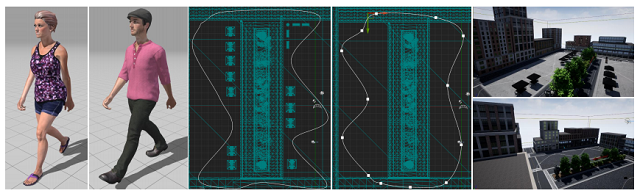
Unreal Engine环境的地图和示例。从左到右分别为两种外观的目标(Stefani和Malcom),两种轨迹(Paht1和Path2)和地图(Square1和Square2),对应的两种场景的示例,通过不同组合构成了不同的跟踪场景。我们用其中一种组合进行训练,其余组合环境进行测试。
网络结构
端到端的主动跟踪器主要由三个部分组成:观测编码器(Observation Encoder),序列编码器(Sequence Encoder)和演员-批评家网络(Actor-Critic Network)。如下图所示:
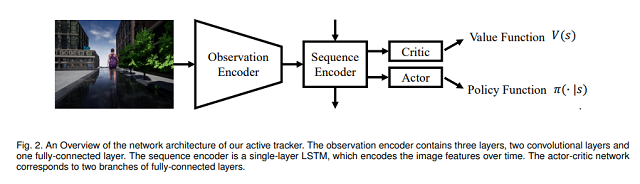
每个部件有着特定的功能,都是实现端到端主动跟踪必不可少的组成部分:
1. 观测编码器主要将原始图像编码成一个特征向量,作为序列编码器的输入。与很多图像编码网络一样,它通常包含了卷积层、池化层和全连接层等。
2. 序列编码器将历史观测特征进行融合,从而获得一个包含时序特征的表示,作为后续演员-批评家网络的输入。因为对于主动跟踪问题而言,除了要识别和定位目标,相应的时序特征(目标的速度、移动方向等)也是至关重要的。一般,它的功能由循环神经网络来实现。
3. 演员-批评家网络共享序列编码器的特征作为输入,分别输出近似的价值函数和动作策略。近似的价值函数代表着期望的累计奖赏值,主要在训练时用于计算演员的策略梯度,来更新网络。当动作空间为离散时,演员输出选择每种动作的概率;当动作空间为连续时,演员输出每一维度动作的平均值和标准差,并用高斯分布来表示动作分布。实验中,它们分别由全连接层来实现。
奖赏函数
在强化学习中,奖赏函数会引导智能体学习,对最终学习效果起着至关重要的作用。针对主动目标跟踪任务,我们需要设计一个奖赏函数以引导智能体学习。最直观的想法应该是在目标接近期望位置时给与奖励,在远离时给与惩罚。因此,我们以跟踪器为中心定义了一个平行于地面的坐标系,y轴指向相机前方,x轴由相机左方指向正右方。对应的,我们用(x,y)和ω分别表示目标相对跟踪器的位置和朝向。从而,我们得到了如下一个奖赏函数:
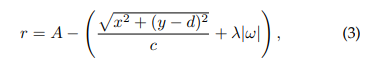
其中,A,c,d,λ均大于0,为可以调整的超参, d代表了期望保持的距离。在这个奖赏函数引导下,智能体最终学会控制相机位置,保持目标始终在其正前方距离为d处。下图为地图俯视图下的示例:
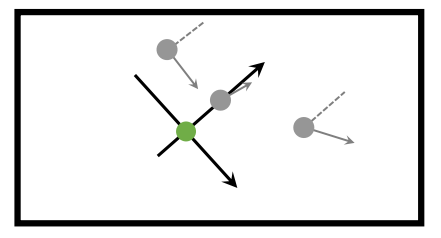
绿点代表了跟踪器,灰点代表了不同位置和朝向(箭头指向)的目标,虚线与跟踪器的y轴相平行。
环境增强技术
为了保证模型的泛化能力,我们提出了简单但有效的环境增强技术用于训练。我们主要采用了以下随机化方式:
1. 随机生成跟踪器和目标的初始位置和朝向
2. 将输入图像进行左右镜像对称(对应的动作空间也将镜像对称)
3. 随机隐藏一定数目的背景物体

上述三点(细节见原文),一定程度上保证了跟踪器的泛化能力。
为了更近一步提升模型的泛化能力以便直接迁移至真实场景,我们对关键要素进行了更进一步的随机化,包括:
1. 目标和背景的表面材质(纹理图案、反射率、粗糙度等);
2. 光照条件(光源位置、方向、颜色和强度);
3. 目标移动(轨迹和移动速度)。具体地,从地图中随机选择一个位置并用内置导航模块生成相应路径引导目标移动。在移动过程中随机调节速度,其范围在(0.1m/s, 1.5m/s)之间。
纹理和光照的随机化主要为了提升观测编码器的泛化能力,避免网络对特定场景和目标外观过拟合。而目标移动的随机化是为了提升序列编码器的泛化能力,避免网络对特定的移动轨迹过拟合。
下图为采用上述随机化方法后生成的示例:

实验验证
首先,我们分别在ViZDoom和UE环境中开展实验,并在VOT数据集中定性验证了模型迁移到真实场景的可能性。之后,我们将介绍如何将主动跟踪器部署到真实机器人上工作,并分别在两个室内室外真实场景中进行了定量实验。
在虚拟环境中进行训练和测试
这里,我们将展示几段虚拟环境中的演示视频(实验细节可参考原文),展示我们的方法训练得到的跟踪器在VizDoom和UE环境中的结果。


虚拟到真实迁移的可能性
我们选择了几段VOT数据集中的片段定性验证模型迁移到真实数据集的可能性。因为输出动作无法直接作用到已经录制好的视频序列,控制下一时刻的观察,因此我们只能通过观察当模型输入给定视频序列时对应的动作输出与真实期望的情况是否一致来判定定性分析模型性能,如目标在画面左边时,观察是否输出左转动作。
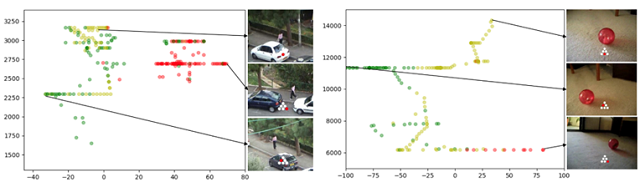
跟踪器输出置之间的关动作与目标大小和位系图。横坐标代表目标中心相对画面中心的偏差,纵坐标代表目标包围框的面积,绿点代表输出左转动作,红点代表右转动作,黄点代表停止/后退。
由上图可见,当目标在左(右)边上,跟踪器会倾向于输出左(右)转,以期望通过旋转将目标移动到画面中心,另外,当目标尺寸变大时,会更倾向于输出停止/后退动作,以避免目标尺寸变得过大。以上结果,可以说明当输入真实图像时,用纯虚拟环境训练的主动跟踪器仍然是可以输出合理的动作的。但是,用录制好的视频作为输入时,相机无法被跟踪器所控制,这与真实的主动跟踪不完全符合,这就无法最终证明我们方法的实际应用价值。因此,我们将开展实验,将虚拟环境训练的主动跟踪模型迁移到真实机器人上的。
在真实场景中的主动目标跟踪
我们在增强的虚拟环境中进行训练,尝试了不同动作空间(更多的候选动作,连续的动作),并直接将训练得到的模型在不同真实环境(室内,室外)中进行测试。
动作空间的选择
除了采用上文提到的更先进的环境增强技术,我们还尝试了不同的动作空间。最早虚拟环境中的实验只提供了六种动作,而对于复杂的真实场景,要适应不同的目标速度和运动方向,这是不够的。因此,我们扩展了原来六种动作至九种,新增的动作有后退和两种不同速度的前进和后退。加入后退使得机器人可以适应更复杂的轨迹,如目标正面向跟踪器走来时。不同速度使得机器人可以更好地适应不同的移动速度。下表为九种动作在虚拟和真实场景下的设置(第二列为虚拟环境,第三列为真实机器人):
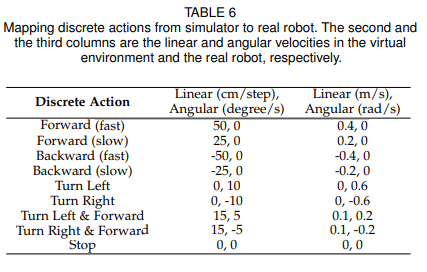
我们也对连续动作空间下的表现能力感兴趣,因此我们尝试了一种二维的动作空间,由线速度和角速度组成。具体的虚拟和现实的设置如下表:
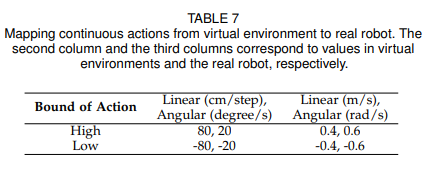
真实场景实验设置
我们采用一个轮式机器人进行实验,如下图 (a) 中所示。机器人上方固定有一个RGB-D摄像头,离地面约80cm高。我们用一个带有8核Intel CPU的笔记本电脑作为计算平台,执行图像采集,神经网络的推理和传送控制指令至底层控制器等系列任务。每个50ms (20Hz) 跟踪器的状态和动作会更新迭代一次。
我们分别在室内房间下图 (b) 和室外阳台下图 (c) 进行测试,以衡量模型部署到真实场景工作的性能。

真实场景实验的部署设置。(a) 为实验所用的机器人;(b) (c) 分别为用于测试的室内、室外场景。
室内房间包括了一张桌子和反射的玻璃墙,玻璃墙会使得机器人在运动过程中观测到的背景发生动态变化。另外,墙上还贴了一张与目标外型接近的海报,可能会对跟踪者产生干扰。为了控制变量,目标将沿着红线进行行走。下图为执行连续动作的主动跟踪器在室内的演示序列。
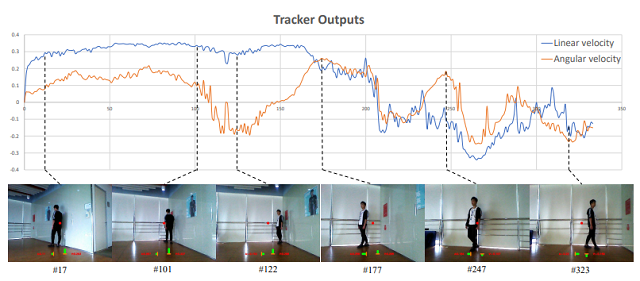
执行连续动作的主动跟踪器在室内场景的观测与输出动作的关系。注意,数值极性对应不同速度方向。 至于角速度,正值为左,负值为右。至于线速度,正值为向前,负值为后退。图像中心的红点是一个参考点,可以帮助我们标记目标和机器人的相对位置。 底部绿条的长度代表速度的大小,水平条代表角速度,垂直条表示线速度。 橙色线代表零值。
室外阳台的背景包含了建筑物、桌子、椅子、植物和天空。相比于室内场景,室外阳台更加复杂,因为物体是随机杂乱摆放的。另外,由于光线不均匀,相机很难准确曝光,这就需要跟踪器适应不同曝光程度的图像观测(如下图序列)。测试时,目标将沿着场地行走一圈。

一段跟踪器在室外执行离散动作进行跟踪的序列。红点代表画面中心,水平条形代表跟踪器输出的期望角速度,垂直的则代表期望线速度。橙线代表零值。
真实场景的实验结果
我们对跟踪器在上述两个真实场景下的性能进行了定量测试,主要考虑模型的准确性和鲁棒性。因为在真实场景中我们无法获得计算奖赏函数所需要的具体坐标位置,因此我们需要采用其它方式衡量。我们规定,当跟踪器让目标持续出现在当前画面当中,直到目标走完全程轨迹,视作一次成功跟踪,反之,当目标从画面中持续消失3s以上时,就认为是一次失败的跟踪。关于准确度,我们考虑目标大小和目标到画面中心的偏差两个指标。目标大小的稳定代表了跟踪器对相对距离的控制能力,目标到画面中心的偏差代表了跟踪器对相对夹角的控制能力。我们采用当前流行的检测器YOLOv3[3]来提取目标的包围框,以计算上述指标。
我们在两个真实环境中,分别测试了跟踪器执 行离散动作和连续动作下的性能指标(每种跟踪器在每个场景中分别执行了十次),结果如下表所示:
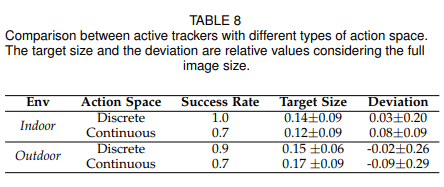
通过上表可见,采取离散动作的跟踪器在两个场景中都可以取得更高的成功率。在室外,离散动作可以让目标大小保持更加稳定(更小的方差)。无论是室内室外,基于离散动作的跟踪器都能保证更小的平均偏差。综合这些结果,说明了采用离散动作可以帮助模型更好更鲁棒地迁移到真实场景。我们猜想对动作空间离散化可以使得智能体对场景中的干扰和机器人控制系统的噪声都更加鲁棒,而连续空间会更加敏感。
下面,我们将分别展示两段主动跟踪器在室内外真实场景中的演示视频。


总结
在本文中,我们提出了一种基于深度强化学习的端到端主动目标跟踪方法。与传统视频跟踪不同,我们提出的跟踪器只需要在模拟器中训练,节省人工标记和在现实世界中的试错调参。实验表明,它对未见过的环境有着良好的泛化能力。 通过开发更先进的环境增强技术并采用更合适的动作空间,我们已成功将跟踪器部署在了一个机器人上,在真实世界中实现主动目标跟踪。
更多细节和实验结果请参考原文:https://ieeexplore.ieee.org/document/8642452/
参考文献:
[1]Wenhan Luo*, Peng Sun*, Fangwei Zhong, Wei Liu, Tong Zhang, and Yizhou Wang. End-to-end active object tracking via reinforcement learning, In ICML 2018.
[2]V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in International Conference on Machine Learning, 2016, pp. 1928–1937.
[3]J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv: 1804.02767, 2018.