






静园5号院科研讲座:西蒙弗雷泽大学张皓教授谈三维形状正确表达及生成
2019年4月24日,加拿大西蒙弗雷泽大学张皓教授来访北京大学前沿计算研究中心,在静园五院作了题为“Finding the Right Representations For Generative Modeling of 3D Shapes ”的学术报告。报告由中心执行主任陈宝权老师主持,听众大多为来自北京大学信息科学技术学院的师生,也包括了来自国防科技大学,北京电影学院、清华大学等单位的研究人员。

张皓老师报告中
在这次讲座中,张皓老师以三维形状的正确表达方式为线索,介绍了他们在三维形状隐式曲面表达IM-GAN,三维形状生成GRASS,三维虚拟室内场景生成GRAINS等方面的工作。
早在1950年,图灵就提出了图灵测试。其内容是:测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置向被测试者随意提问。 进行多次测试后,如果有超过30%的测试者不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。 虽然在2014年,就已经有电脑程序通过了图灵测试。张皓老师称,真正能够称之为“人类”的机器人,不应该仅仅是像人类一样谈话就可以,它应该具有人类才有的真正从无到有的、独到的到创造力。

在机器学会创造之前,首先要学会生成。现在已经有大量基于深度神经网络来进行生成声音,图像,三维形状,三维虚拟场景的工作。 在二维图像生成方面,已经有一些让人印象深刻的工作。英伟达(Nvidia)提出的PG-GAN能稳定地训练生成高分辨率图片,如上图所示。
编者注:三维形状,本文中指代3D Shape
在三维形状生成方面,也有了一些工作。但相比于二维的生成,三维形状的生成具有一些特殊的挑战。
三维形状生成的挑战一:缺乏通用表达形式

不同于图像或者语言,三维形状没有统一标准的表达或者编码方式。三维形状基本的表达方式有:三角形面片组成的网格,体素化形成的模型,由三维点组成的点云等。大多数这种表示的方法分辨率不高。而大多数现有三维形状表达形式在深度学习网络中多用于“识别”,而非“生成”。
三维形状生成的挑战二:数据的获取和交互

三维数据的获取,获取能交互的三维形状是困难的。到目前为止,针对三维模型的分析和生成任务,我们依然缺少大规模的三维数据。
三维形状生成的挑战三:交互和功能

我们在三维世界中和三维物体进行交互。最终,我们不仅仅是能看到三维物体,我们还能与三维物体产生交互,这就要求我们输出的三维形状能够具备这种交互性,也就是说必须要有功能性。
在最终生成具备功能性的三维形状之前,我们首先要生成高质量的三维形状。目前,神经网络生成的三维模型仍然在视觉上充满缺陷:分辨率非常低、几何/结构/拓扑方面仍旧有很多噪声。张皓老师他们其中一个主要研究方向就在于:找到三维形状的正确表达方式,用来去训练深度神经网络,再去用这样的网络去“生成”高质量的三维形状。
“形状”的定义

为了生成高质量的三维形状,首先要搞清楚问题的本质:什么是形状?形状的解释是这样的,"某人或某物的外在形式或外观特征,一个区域或人物的轮廓"。形状是由这个物体的边界或者说是外轮廓定义的。不同于图像的特征,形状的边界关心的是什么在形状的内部,什么在形状的外部。要生成高质量的三维形状,我们需要知道哪些点在形状的外部,哪些点在形状的内部。

在GRASS之前的多数三维形状生成工作如上图所示,基于卷机神经网络的生成模型,通过对编码数据或者噪声的反卷积,得到生成的形状。这些形状的生成基于图像特征到体素值的映射关系。三维形状生成的工作有3D-GAN,它是使用生成对抗网络学习2D图像到3D模型的映射,生成网络负责生成3D模型,对抗网络判断这些模型是真是假。3D-GAN中,三维形状表达为体素,网络映射了一个200维的向量到分辨率的体素模型。
这种映射确实端到端解决了三维形状生成的问题,这种直接从二维数据处理方法延伸出来的思路确实比较直接,但是这种映射合理吗,是否包含了冗余的信息,真正正确的映射关系应该是怎样的呢?

上述定义了形状的一种隐式表达的方式。基于这种表达方式,Zhiqin Chen,Hao Zhang等提出了IM-NET,一种隐式区域生成器。IM-NET能够训练学习得到对于任意一个三维点,判断这个点在三维形状的外部还是内部,换句话说它能学习到形状的边界。相比而言,传统的CNN网络学习的是特征到体素的映射。
通过IM-NET与传统的CNN在形状生成等方面的比较,两者主要区别如下:
1. CNN通常假设平移不变性:对于识别问题,这是良好的假设,但对于形状生成的情况并没有必要 ;
2. IM-NET通过全连接层使用MLP;
3. IM-NET采用点坐标作为输入:学习函数在点位置和图像密度上都是连续的,与之相反CNN只有图像密度是连续的。
基于体素的CNN网络生成的体素三维模型,没法区分三维形状的部分信息。这就导致模型有很多低分辨率噪点;三维形状部分与部分之间区分不清晰;对于随后其它的三维形状而言,之前生成的三维形状没有重用性。直觉上来讲,日常生活中我们接触到的三维形状也不是以体素为基础的,而是一个个由部分组成的整体(例如我们组装而成的家具)。
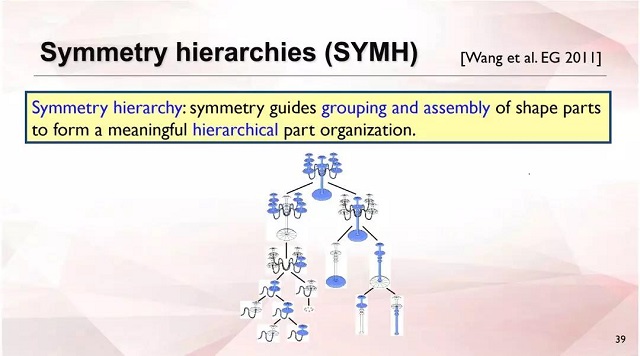
对称层级(SYMH)[Wang et al. EG 2011] 是解决上面问题的一种结构表示。对称层级提出了针对部分区分的一个很好的表达方式,这是一个三维模型的高级结构表示,提供了模型组成部分对称的分层组织,它比局部几何考虑的更有意义。 它的分层组织使其有结构信息,每个叶子结点又能恢复部分的几何信息,它相当于解耦合了三维形状中的结构和几何这两种信息。
我们的神经网络能够训练学习三维形状的这种表达方式吗?我们能把SYMH编码进我们的网络吗?
有一种网络特别适合用来训练这样的数据,递归神经网络-Recusive Neural Network(巧合的是,它的缩写和循环神经网络-Recurrent Neural Network一样,也是RNN)可以处理诸如树、图这样的递归结构。递归神经网络可以把一个树/图结构信息编码为一个向量,也就是把信息映射到一个语义向量空间中。这个语义向量空间满足某类性质,比如语义相似的向量距离更近。在这里,三维形状的结构被表达为一些有组织的盒子,每个盒子被编码为固定维度的向量,也就是SYMH的叶子结点。
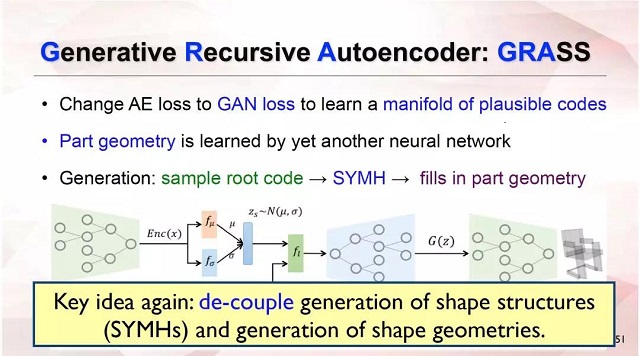
基于递归神经网络设计的自动编解码器,可以把盒子的层次编码转变为一个Root Code,再把这个Root Code 解码为盒子的对称层次结构。当我们把这种自动编解码器的损失转变为GAN的损失时,我们就能用GAN来生成三维形状的结构了,再用其它的学习方法生成结构中部分的几何信息,这样我们就能完整的生成一个具有结构和几何信息的三维形状,这就是GRASS的主要思想。

在GRASS的基础上,GRAINS [Li et al. TOG] 提出了自动生成室内场景的学习网络。
在最后的总结中,张皓老师也指出了未来努力的几个方向:
1. 训练IM-NET非常慢,每个点都要参与其中,是否能够把点变成片,或者聚类成其它形式
2. 除了学习点在外部/内部,是否可以用其它特性,比如法向,纹理,颜色等
3. GRASS训练需要分割好的三维形状,是否可以避免?

报告信息、报告人简介请见:https://cfcs.pku.edu.cn/announcement/invited_talks/235911.htm