






王亦洲课题组入选ICCV2019论文解读:基于医疗影像的早期诊断中不确定样本的检出
本文是计算机视觉领域顶级会议ICCV 2019入选论文 《基于医疗影像的早期诊断中不确定样本的检出(Learning with Unsure Data for Medical Image Diagnosis)》的解读。

该论文由北京大学王亦洲课题组与微软亚洲研究院、首都医科大学、深睿医疗合作,研究了基于医疗影像进行早期诊断,所遇到的不确定样本问题。所谓不确定样本,是指在早期诊断中无法给出明确的“是否患病”诊断的样本。这一类型数据在医疗影像中广泛存在。本文提出的 UDM 模型旨在将这部分数据准确识别。肺结节和阿尔茨海默疾病的实验结果表明,本文提出的方法能够很好地将这部分样本准确识别。
什么是“不确定性医疗数据”?
基于医疗影像的早期疾病诊断可以大大提高疾病治愈率。然而处于早期诊断任务中,除了疾病与健康两类样本外,还存在另一类样本,即处于疾病发展过程中,然而还未完全发展成疾病的样本。对于这类样本,医生很难在当下判断其是否患病。我们称这一类样本为不确定样本,它在早期的医疗影像中大量存在。如果草率地将这部分样本归为是否患病,则有可能带来重大医疗损失。将这类不确定样本检测出来,能够带来如下好处:
1. 能够及时对这些样本进行随访检查,从而避免医疗损失;
2. 能够降低患病检出的假阳性;
3. 使得模型在剩余(确定)样本中得到更加准确的分类。
一个典型的例子是阿尔茨海默疾病,有一种介于严重认知障碍(AD)和健康(NC)的状态,称为轻度认知障碍(MCI)。患有 MCI 的人群中只有一部分人会发展成 AD(如图1),而在发展过程中,医生很难对早期 MCI 样本做出是否一定会转成 AD 的判断。对这部分人群,需要不断跟进的检查,而不能简单地给出是否患病这样的二分类标签,因为这样会造成极高的误诊率,而误诊会造成严重的医疗事故,比如错过最佳治疗时间,误服药造成副作用等。
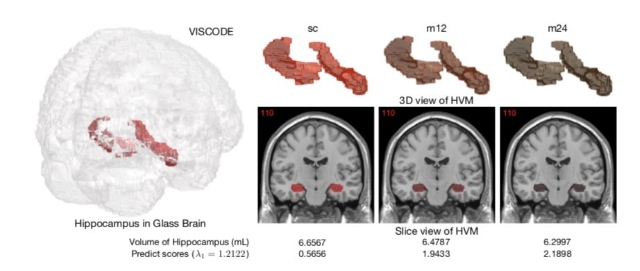
图1:对MCI患者的随访检验
HVM代表海马体积,体积越小患病几率越大。m12,m24分别代表随访12和24个月后的情况。二维切片图下分别列上了海马体积和我们模型的预测分数。
样本的“不平衡与误诊损失”问题
由于疾病早期有大量这种不确定性数据,因此数据往往面临样本不平衡问题。此外,我们认为,将健康误诊为患病和将患病误诊为健康导致的后果是不同的:很多情况下后者会造成更高的损失。因此,我们希望模型在诊断时将后者的误诊率降到最低。本文的目的是通过模型将上述问题解决,从而精确地将这些不确定数据检验出来,以建议患者通过随访检验来跟进疾病发展情况。
不确定性数据模型
本文将不确定样本问题的检出建模为三分类问题:患病样本、不确定样本、健康样本。针对一般的多分类问题,常用方法会用交叉熵作为损失函数来进行分类。然而,这类方法没有利用样本间按照疾病程度呈递增有序关系的信息,即按照疾病程度排列顺序为,患病样本,不确定样本和健康样本。为了弥补这一缺陷,我们基于 Margin 的思想提出新的损失函数,从而较好地利用这样的先验知识。同时,我们在模型中加入对样本不平衡和误诊问题的考虑和解决方法,模型具体流程图见图2。
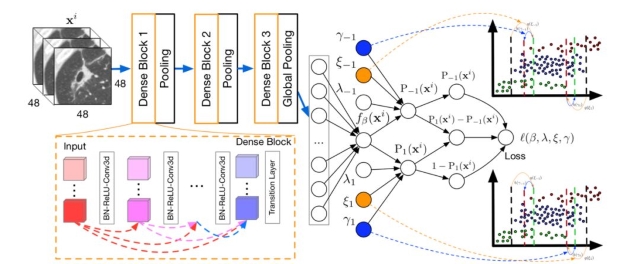
图2:模型流程图
左边为用于做分类的Densenet网络,ξ1, ξ-1代表cost-senstive的参数,用于解决样本不平衡问题,γ1, γ-1代表模型根据误诊类型调整诊断策略的参数。
首先由于每一类的疾病程度有递增关系,因此我们这里采用Margin的思想对其进行建模:

其中 fw(·) 代表参数为 w 的学习模型,比如深度神经网络等,w 为可训练的参数。而在不确定性数据中,我们假定数据分为三类,其中1代表患病,0代表不确定,-1代表健康, (λ1, λ-1) 为阈值参数。这样我们可以根据 εi 的分布 G 来得到如下损失函数,作为负对数似然函数:

为了解决样本不平衡问题,我们这里采用 cost-sensitive 的方法来调整 Margin,从而弥补由于样本不平衡带来的偏差。此外,上面提到,将患病误诊为健康会带来更大的风险,因此我们需要模型能够“激进”地将患病的案例尽可能地检测出来,从而不会错过治疗时机;而对于健康样本,我们可以允许模型相对保守,因为这样的误诊一方面通常情况下不会带来很严重的损失,另一方面也更加谨慎,建议健康患者进行随访检验,这样设计也符合医生的临床诊断策略。因此,我们希望提升患病类别的 recall 以及健康类别的 precision。为了达到这一效果,我们引入参数 (γ1, γ-1),从而进一步调整 Margin。新的概率分布函数为:
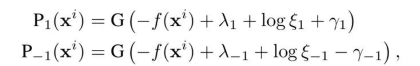
一方面,我们会通过自动学习参数 (ξ1, ξ-1) 来调整阈值参数的边界,这里我们希望 (logξ1, logξ-1) 分别 >0 和 <0,这样我们便可以使得阈值参数 (λ1, λ-1) 的绝对值降低;在预测时,也可以有效地避免模型偏差到不确定这一类(数据中较多的类)。另一方面,我们通过设定超参数 c1>0,使得其约束 γ1>0,从而能够让 λ1 的值进一步降低,进而使得更多疑似患病的样本被检验出来。针对这样的激进保守策略,相应的损失函数为:
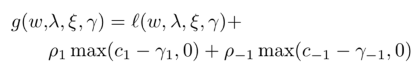
其中,((λ1, λ-1) , (ξ1, ξ-1) , (γ1, γ-1) 为学习参数;(c1, c-1) 为设定超参。
实验结果
我们对肺结节和阿尔茨海默疾病做实验。对肺结节实验,我们用 LIDC-IDRI 数据,包括1010个病人和2660个肺结节。对于每个肺结节,有1-7名医生进行打分,分为1分至5分5个档次。分数越高,代表医生认为恶性可能越大。已有模型都会将平均分为3.5分以上的结节视为恶性,2.5分以下的视为良性。而分数介于2.5到3.5的肺结节将不参与模型训练和分类任务。我们这里将其标为不确定这一类。
对阿尔茨海默疾病实验,我们采用 ADNI 数据,每个样本为两侧海马的核磁共振图像,分为1.5特斯拉和3.0特斯拉磁场强度。其中1.5特斯拉的数据包含64个 AD,208个 MCI 和90个 NC;而3.0特斯拉的数据包含66个 AD,247个 MCI 和110个 NC。对这两个数据,我们用 DenseNet 神经网络对参数进行训练。并采用指标进行评判,它可以作为二分类中 F1-score 的一般形式:
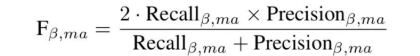
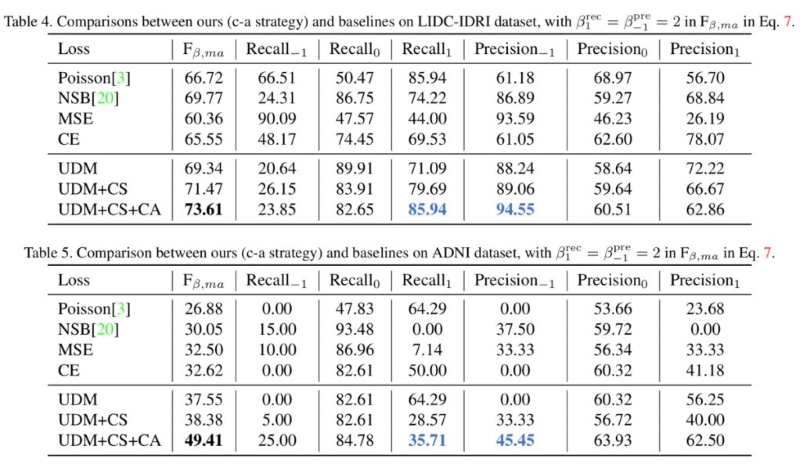
实验结果如下面的 Table 4 和 Table 5所示,UDM 为不确定性模型,UDM+CS 为解决样本不平衡问题的不确定性模型,UDM+CS+CA 为在此之上的激进保守策略模型。可以看出,在两个数据集上,UDM 相比较已有方法都取得了最好的效果,由于解决了样本不平衡问题,UDM+CS 的结果得到了进一步提升,而 UDM+CS+CA 使得模型在恶性结节的召回率很高,从而进一步大幅度提升了评价效果。
在肺结节和阿尔茨海默疾病的实验结果
参考文献:
[1] Yehuda Koren and Joe Sill. Ordrec: an ordinal model for predicting personalized item rating distributions. pages 117– 124, 2011. 2.2, 3.2
[2] GaoHuang, ZhuangLiu, Laurens Van Der Maaten, and Kil- ian Q Weinberger. Densely connected convolutional net- works. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017. 1, 4.2
[3] Samuel G Armato, Geoffrey McLennan, Luc Bidaut, Michael F McNitt-Gray, Charles R Meyer, Anthony PReeves, Binsheng Zhao, Denise R Aberle, Claudia I Hen- schke, Eric A Hoffman, et al. The lung image database con- sortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical physics, 38(2):915–931, 2011. 4.1
[4] Chendi Huang, Xinwei Sun, Jiechao Xiong, and Yuan Yao. Split lbi: An iterative regularization path with structural spar- sity. In Advances In Neural Information Processing Systems, pages 3369–3377, 2016. 4.1
关于ICCV
IEEE International Conference on Computer Vision(IEEE ICCV),即国际计算机视觉大会,是计算机视觉领域国际顶级会议(CCF A类),与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议。ICCV在世界范围内每两年召开一次,ICCV 2019将于2019年10月27-11月2日在韩国首尔举行。