






王亦洲课题组CVPR 2020入选论文解读:用于人体姿态估计的预训练信息融合模型
导读
本文是计算机视觉领域顶级会议CVPR 2020入选论文《MetaFuse: A Pre-trained Fusion Model for Human Pose Estimation》的解读。
论文地址:https://arxiv.org/abs/2003.13239

01 引言
从多视角图像中估计出人体关键点的 3D 坐标,是计算机视觉中一个重要的任务。许多工作的流程为:首先从每个相机视角估计出 2D 坐标,然后使用三角化(Triangulation)等方法,计算出对应的 3D 坐标。这类方法的最终结果质量,通常取决于 2D 坐标的精确度。但是,如果存在遮挡等问题,预测的 2D 坐标会存在较大的误差。
在预测 2D 坐标过程中,融合多个视角的信息可有效解决遮挡等问题。但是目前方法中,融合模型的参数依赖于特定相机对,难以泛化到新的环境。针对这一问题,本文提出将原有的融合模型分解为(1)所有相机共享的通用模型(2)针对特定相机的轻量变换矩阵。并且使用元学习算法,在大规模多相机数据中进行预训练,从而最大化模型的泛化能力。在多个公开数据集上的实验,证明了该模型(MetaFuse)在新环境中只需少量样本即可有效迁移。
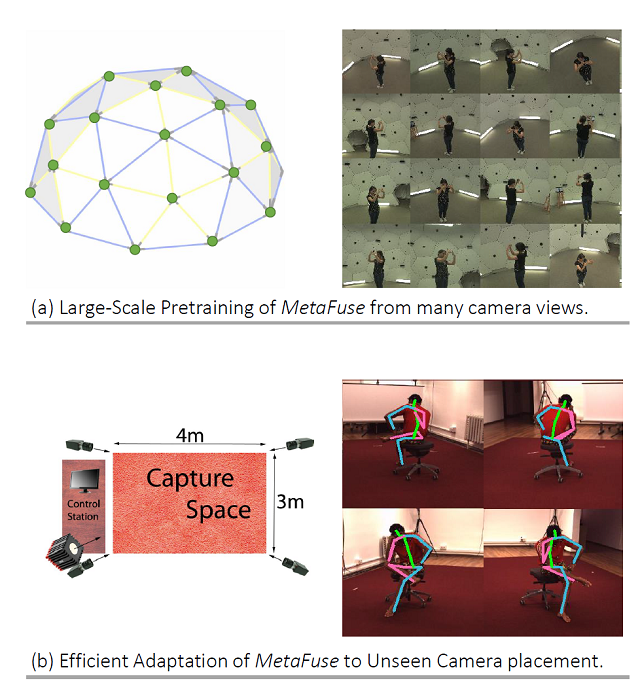
图1:MetaFuse示意图
02 预备知识:多视角信息融合
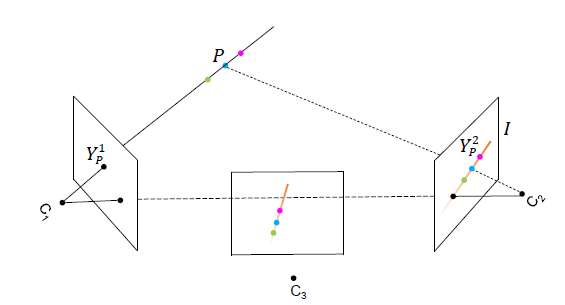
图2:多视角信息融合的几何解释
首先介绍多视角信息融合的基础知识[1]。由对极几何(Epipolar Geometry)可知,相机1中的一个像素点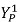 ,在另一个相机2中,对应的像素点必定位于一条直线 I(Epipolar Line)上。因此,我们可以将直线 I 对应的特征信息,融合到该点
,在另一个相机2中,对应的像素点必定位于一条直线 I(Epipolar Line)上。因此,我们可以将直线 I 对应的特征信息,融合到该点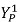 中。具体公式如下所示:
中。具体公式如下所示:
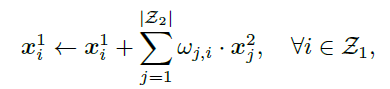
其中 ωj,i 是一个标量,代表了相机2中像素 j 与相机1中像素 i 的关联程度,如何确定其取值是融合过程中最关键的问题。在[1]中提出的 NaiveFuse 模型中,直接采用了全连接层(FCL)的方式,来融合一个相机对之间的信息。如图3所示,将视角1中卷积网络预测的 Heatmap 拉伸为一维向量,然后经过全连接层转换后与视角2的初始 Heatmap 相加,即可得到视角2的最终预测。该融合模块(FCL)可以和卷积网络一起,使用真实标记作为监督,进行端到端的训练。
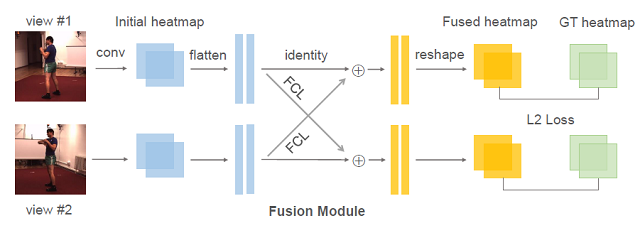
图3:NaiveFuse模型
但是,全连接层简单地将一个视角中的所有像素,和另一视角中所有像素相连接。它的参数对位置的敏感性高,当相机姿态稍微变化时就可能急剧改变。因此,该方法很难迁移到不同的多相机环境中。此外,全连接层的参数量较大(一般为 642×642),在小数据量训练的情况下存在过拟合的风险。
03 本文方法
本文的主要贡献在于两个方面。第一是将原有的 NaiveFuse 模型分解为两个部分,形成了更紧凑且可迁移性更好的模型。第二是在有着大量相机对的数据中,使用元学习算法来进行训练,目的是让模型经过少量数据微调(Fine-Tuning)后,即能迁移到未知的多相机环境中。
如图2所示,如果已知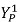 在视角2中对应的线段 I。将视角2切换为视角3时,可以通过对线段 I 进行合适的仿射变换,得到视角3中对应的极线。受此启发,假设存在一个通用的融合模型 ωbase,它用于连接视角1中单个像素和视角2中的所有像素。那么对于视角1的其他像素而言,可以通过对 ωbase 进行仿射变换,得到对应的融合权重。
在视角2中对应的线段 I。将视角2切换为视角3时,可以通过对线段 I 进行合适的仿射变换,得到视角3中对应的极线。受此启发,假设存在一个通用的融合模型 ωbase,它用于连接视角1中单个像素和视角2中的所有像素。那么对于视角1的其他像素而言,可以通过对 ωbase 进行仿射变换,得到对应的融合权重。
计算过程如下所示,其中 T 代表仿射变换,θi 代表视角1中像素 i 对应的仿射变换参数(2×3 的二维矩阵)。而 ωi 则连接了视角1中像素 i 和视角2中所有像素,尺寸与 Heatmap 相同,为 H×W。仿射变换的实现参考了 Spatial Transformer Network[2]。
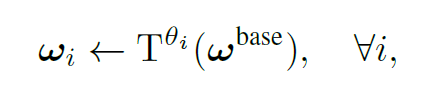
对于不同的相机对,同样可以对 ωbase 进行仿射变换来得到所需的融合模型。该过程实际上将原有模型分解为(1)所有相机对共享的通用模型 ωbase;(2)针对特定相机对和特定像素位置的轻量变换矩阵 θ。与 NaiveFuse 模型不同,通用模型在相机姿态变化时更加稳定。
此外,本文还采用了 Model-agnostic Meta-learning(MAML)的元学习框架[3],来学习更好的初始化模型。元学习(Meta-Learning)的主要目标,是在不同任务组成的分布中学习,从而使模型能快速适应新任务。在本文中,一个任务指的是对一个相机对进行信息融合。训练过程中,使用大量不同的相机对数据进行 Meta-Training。目的是训练出更好的参数初始值,该初始值可以更快地迁移到新的相机对。
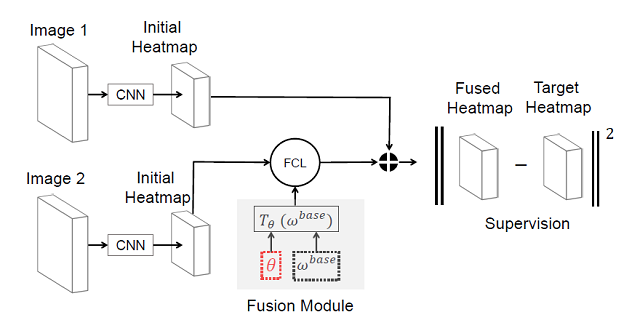
图4:MetaFuse训练流程
本文提出的方法 MetaFuse,总体训练流程如图4所示。第一步,先使用所有数据来训练卷积网络(CNN)部分。第二步,固定卷积网络参数,使用 Meta-Training 训练得到最优的 ωbase 和 θ 初始值。在测试阶段遇到新的环境(相机对)时,只需要少量标记样本对仿射变换参数 θ 进行微调。
04 实验与分析
数据集
实验的训练集是 CMU Panoptic Dataset, 从中选取了20个相机的数据用于训练(Meta-Training)。测试数据集为 H36M(Human3.6M),Total Capture 数据集等。在 H36M 等数据集中,只使用少量标记数据进行微调(50~500个)。
对比方法
用于对比的 Baseline 方法包括:
1. No Fusion,不进行视角间的信息融合;
2. Full Fusion,使用所有目标数据,进行 NaiveFuse 的训练;
3. 使用少量数据训练 NaiveFuse;
4. AffineFuse,使用常规梯度下降方法训练参数分解后的模型,并使用少量数据微调;
5. MetaFuse,使用元学习来训练参数分解后的模型,并使用少量数据微调。
实验结果
在 H36M 数据集的 2D 检测结果如图5所示,其中横坐标表示用于微调的样本数量,纵坐标表示关节点检测成功率(Joint Detection Rate)。可以看出,NaiveFuse 在样本数量较小时效果差,出现了过拟合的现象。AffineFuse 的表现超过了 NaiveFuse,验证了参数分解的有效性。而本文提出的 MetaFuse,在不同的数量时都超过了其他方法,验证了元学习算法可进一步增强模型的泛化性能。
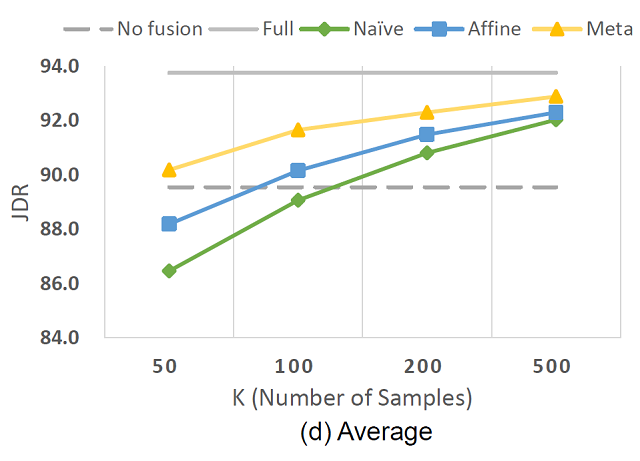
图5:H36M数据集的2D结果
在 H36M 和 Total Capture 数据集中,得到的 3D 结果分别如表1和表2所示。3D 姿态估计的准确度,使用真实 3D 坐标和预测坐标的Mean Per Joint Position Error(MPJPE)来衡量。
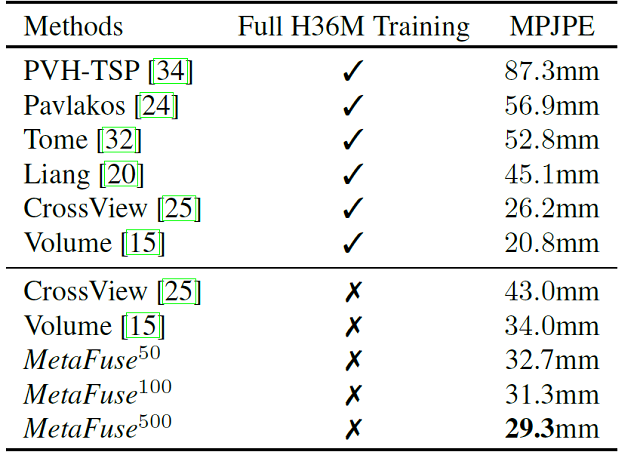
表1:H36M数据集的3D结果
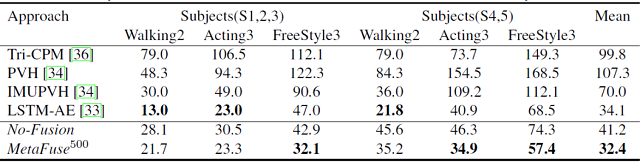
表2:Total Capture数据集的3D结果
图6对多视角信息融合的过程进行了可视化。

图6:信息融合过程可视化
05 总结
本文提出了 MetaFuse,一种在新的测试环境中只需少量样本即可训练的多视角信息融合模型。该方法可以和目前任意的 2D 人体姿态估计模型相结合,并且可迁移到任意的多相机环境中。在多个公开数据集中的实验结果,验证了该模型的泛化能力。
参考文献
[1] Haibo Qiu, Chunyu Wang, Jingdong Wang, Naiyan Wang, and Wenjun Zeng. Cross view fusion for 3d human pose estimation. In ICCV, pages 4342–4351, 2019.
[2] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks. In NIPS, pages 2017–2025, 2015.
[3] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model agnostic meta-learning for fast adaptation of deep networks. In ICML, pages 1126–1135. JMLR. org, 2017

IEEE Conference on Computer Vision and Pattern Recognition(IEEE CVPR)是计算机视觉领域国际顶级会议(CCF A类),每年举办一次。CVPR 2020将于2020年6月16-18日在美国西雅图举行。