[NeurIPS 2023] Find What You Want: Learning Demand-conditioned Object Attribute Space for Demand-driven Navigation
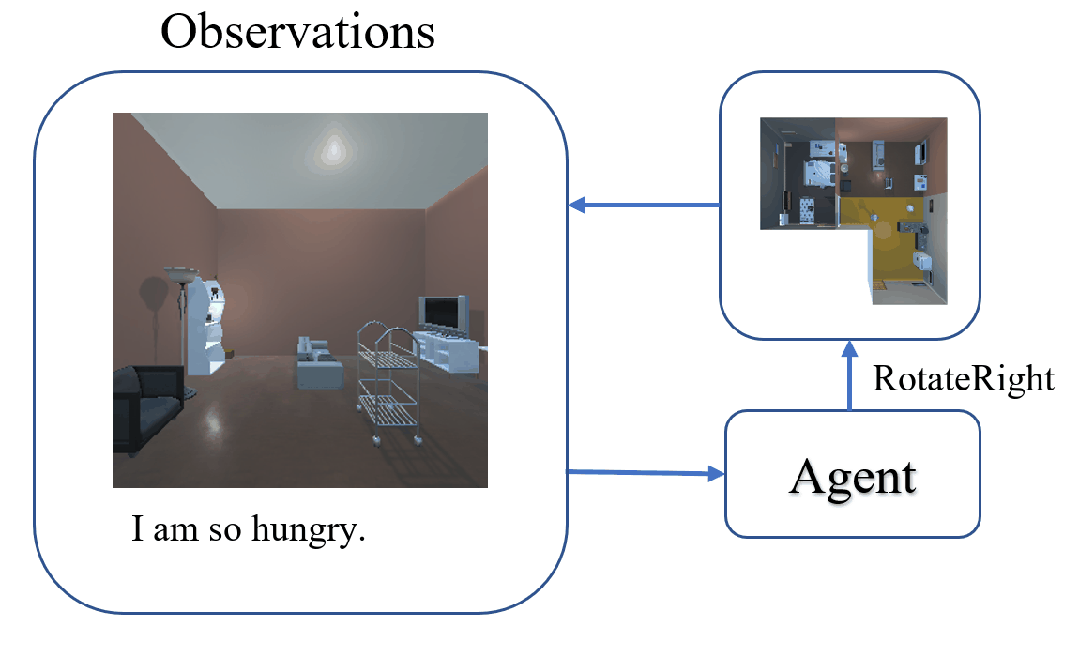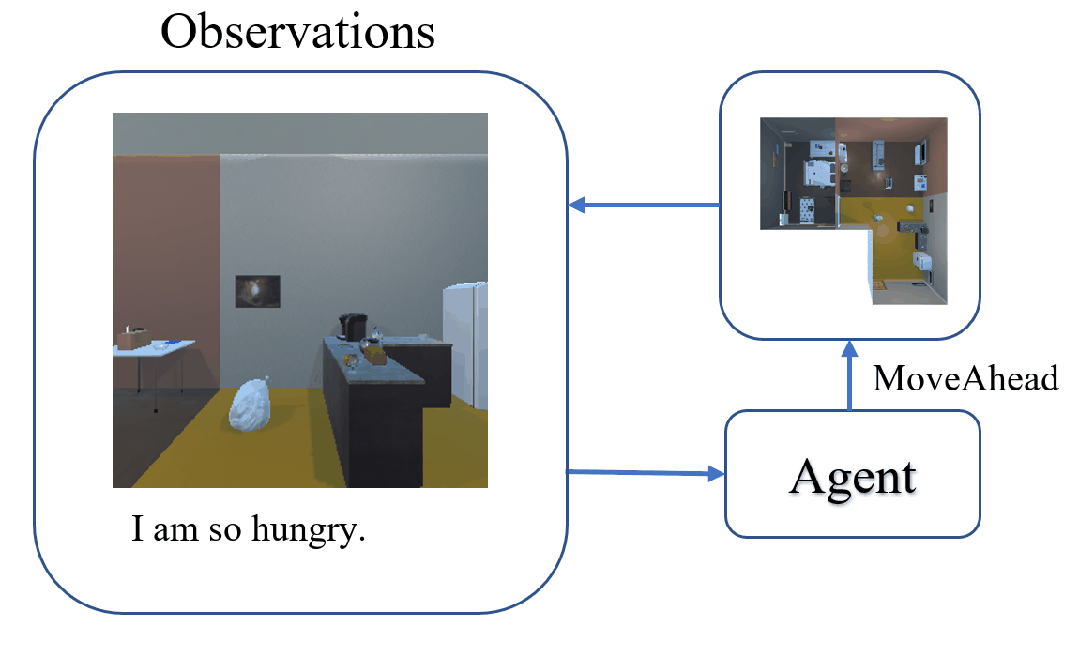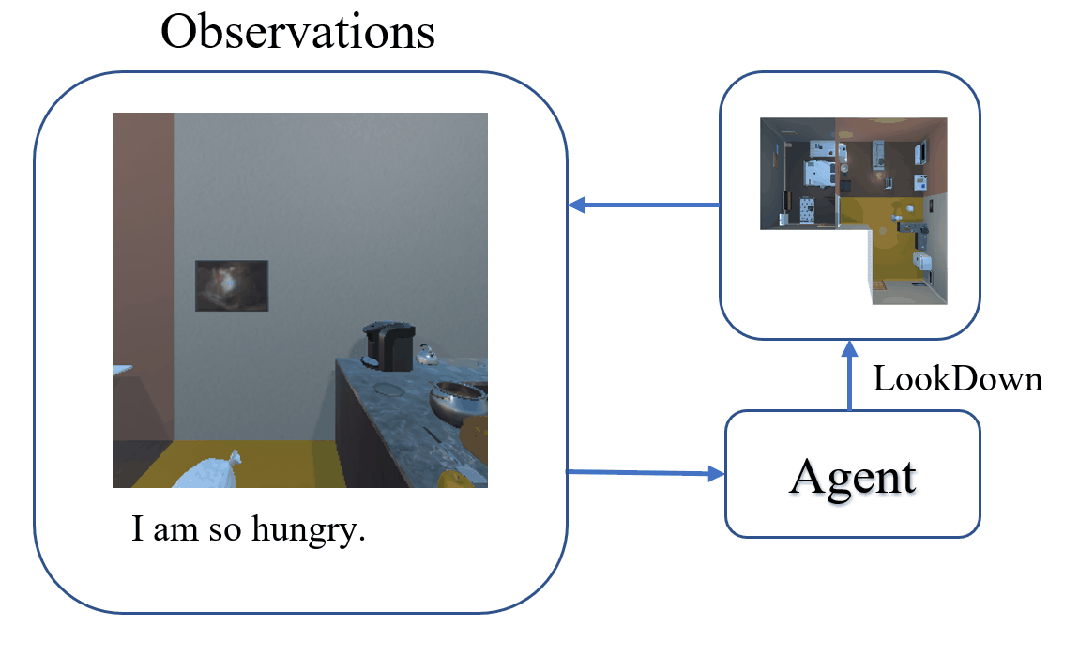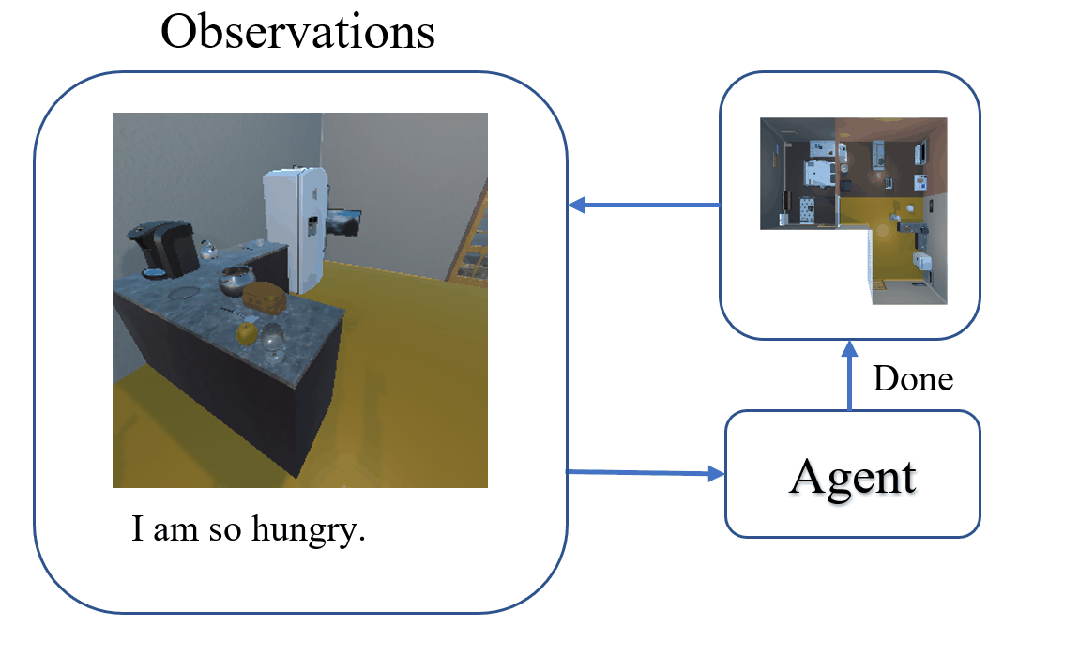
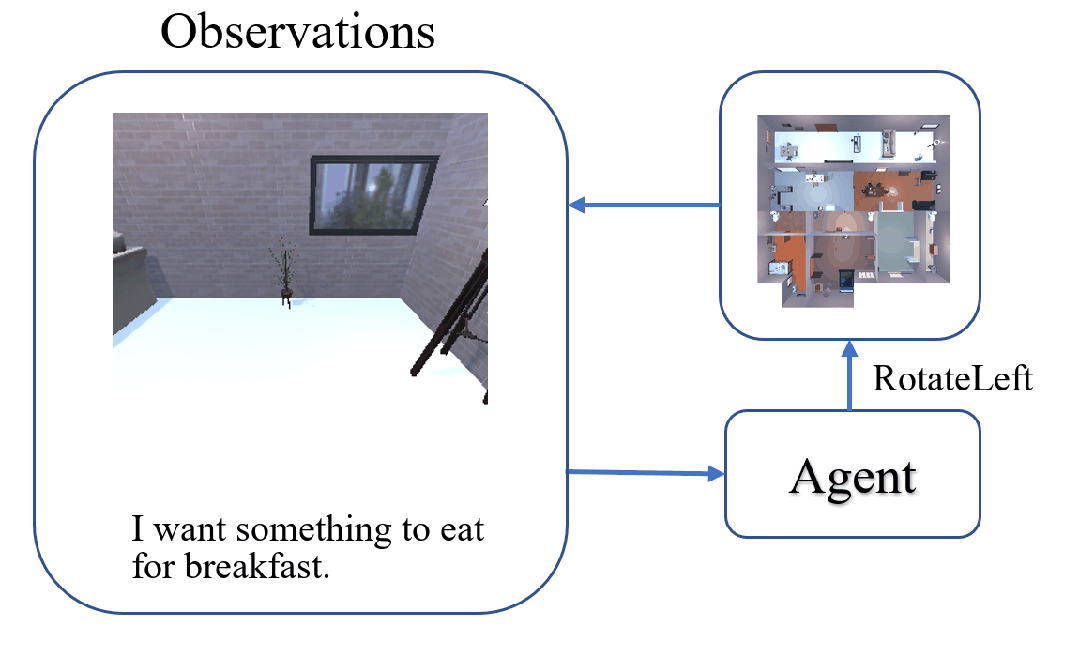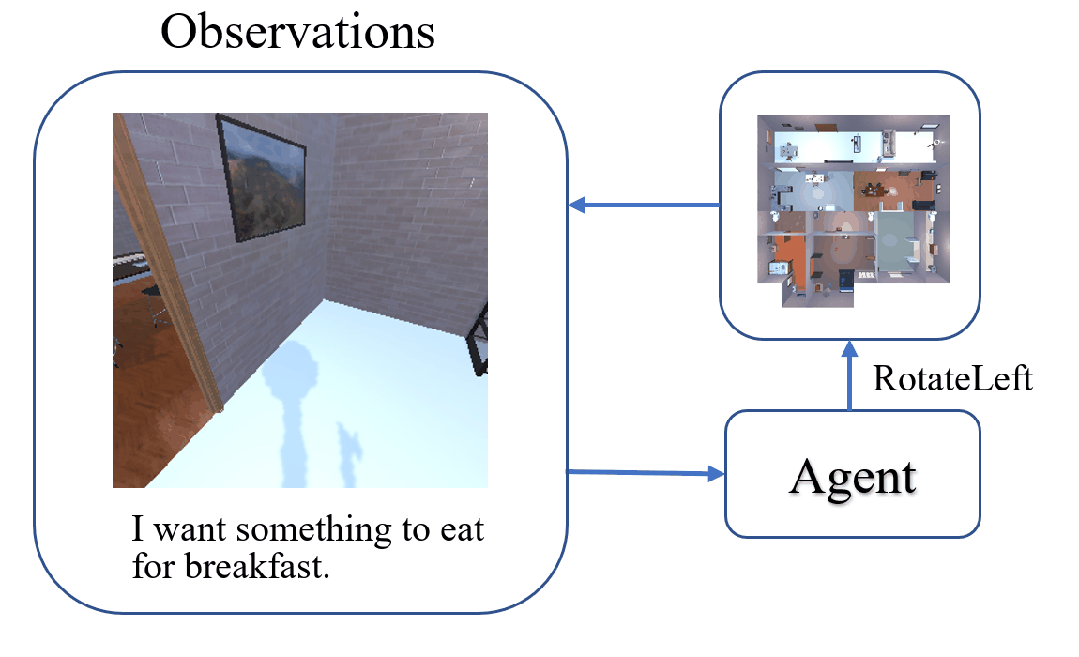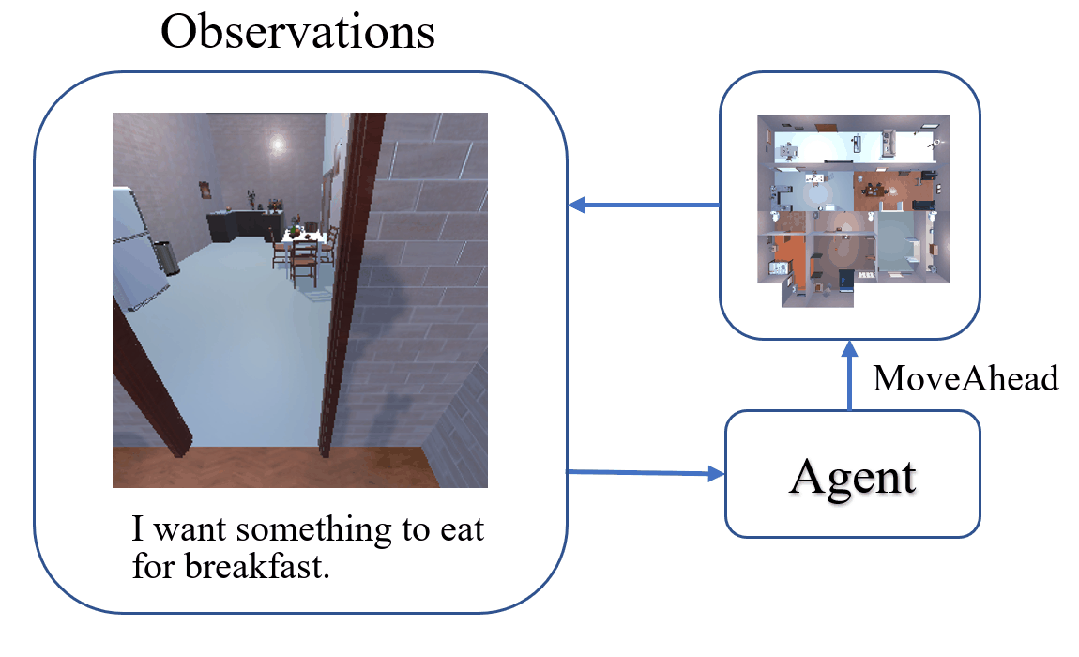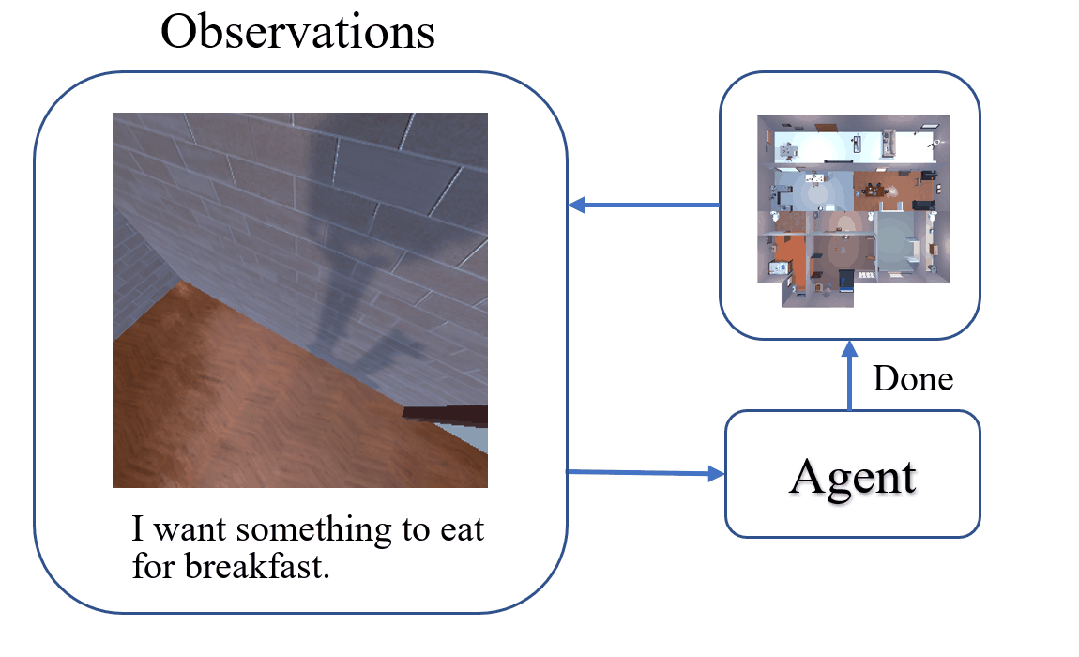
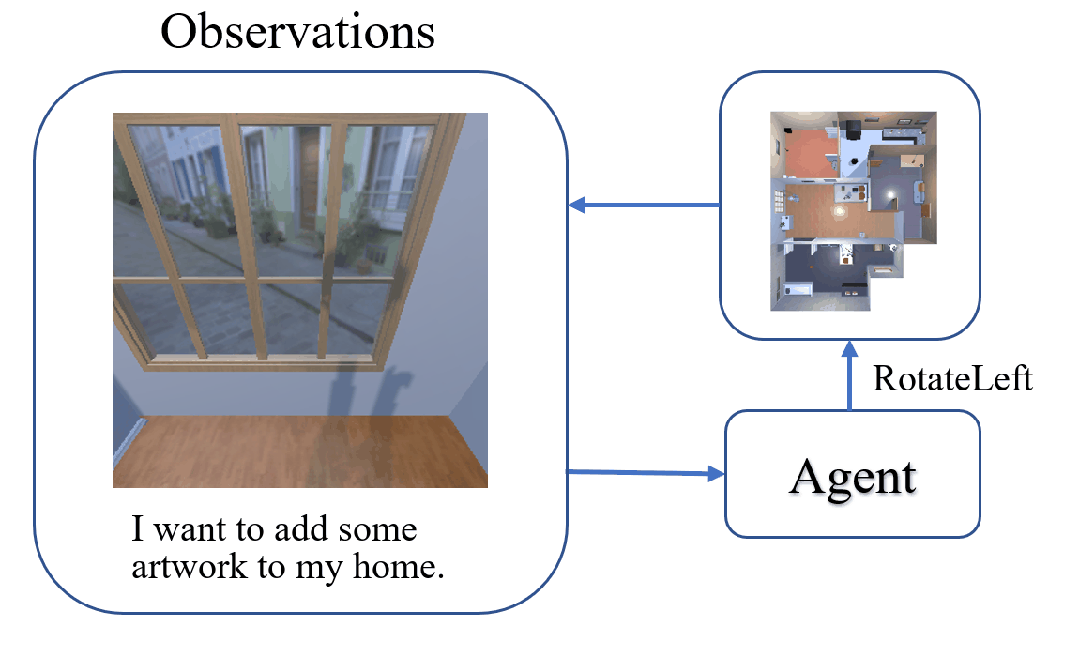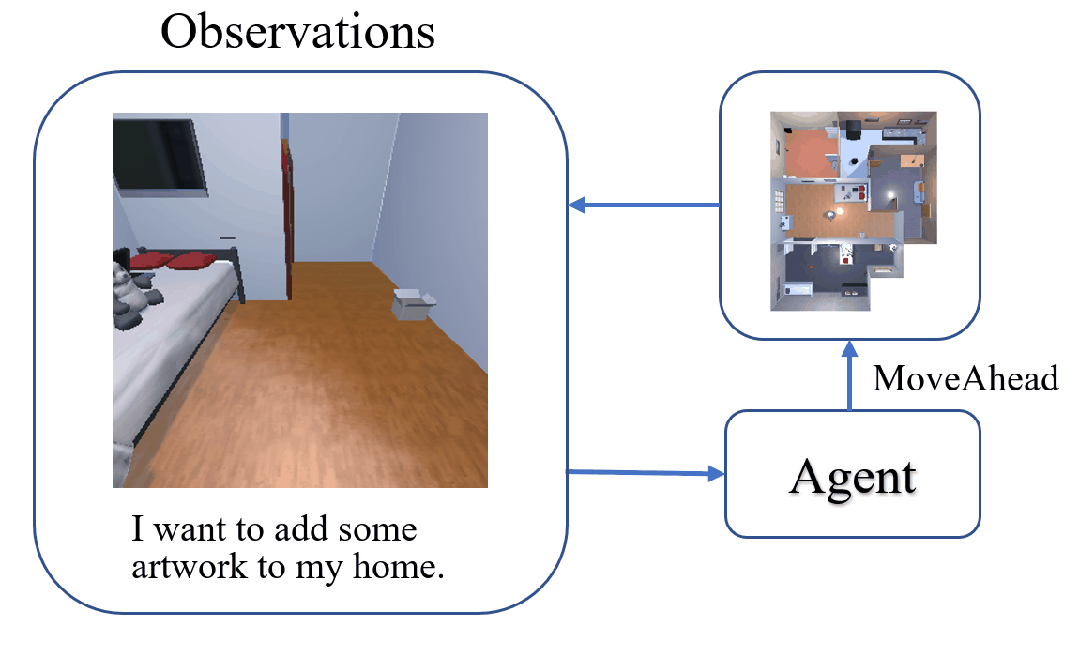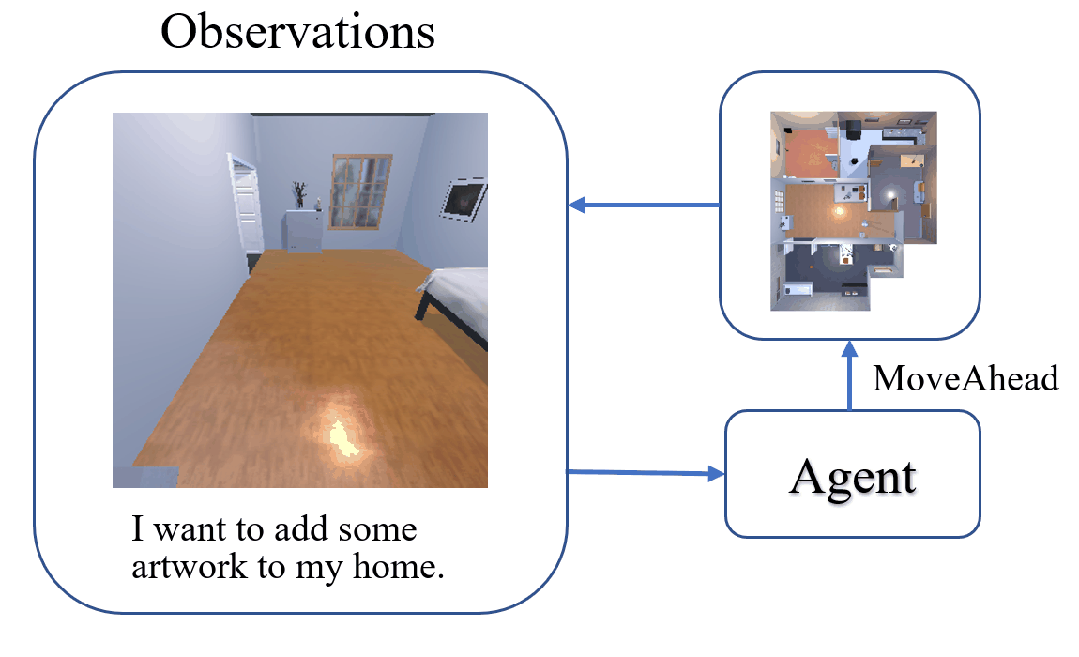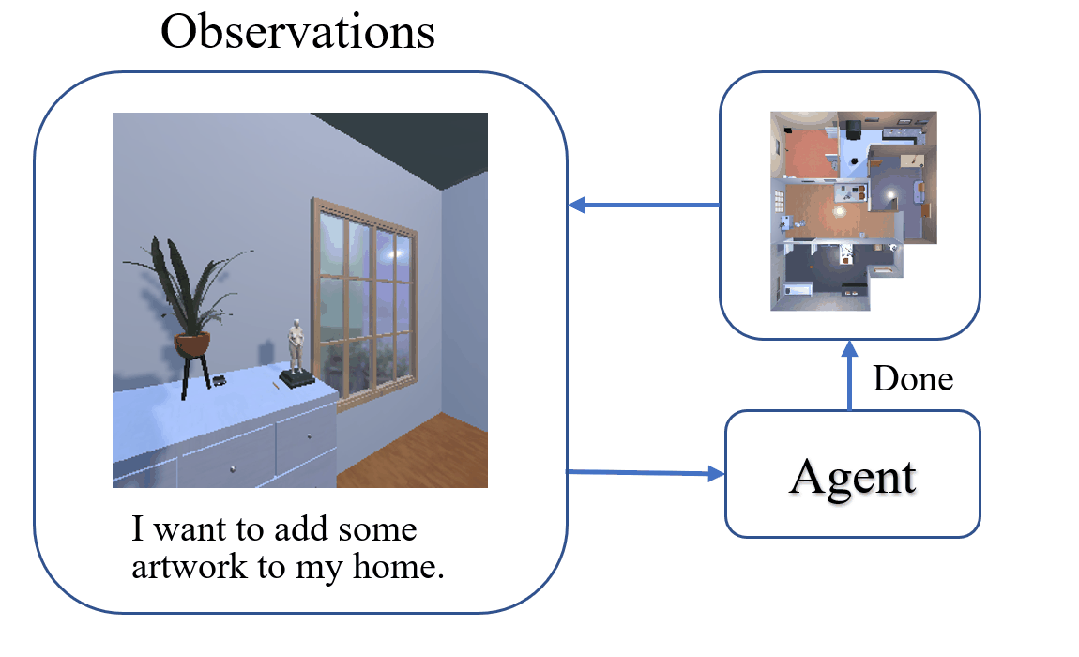
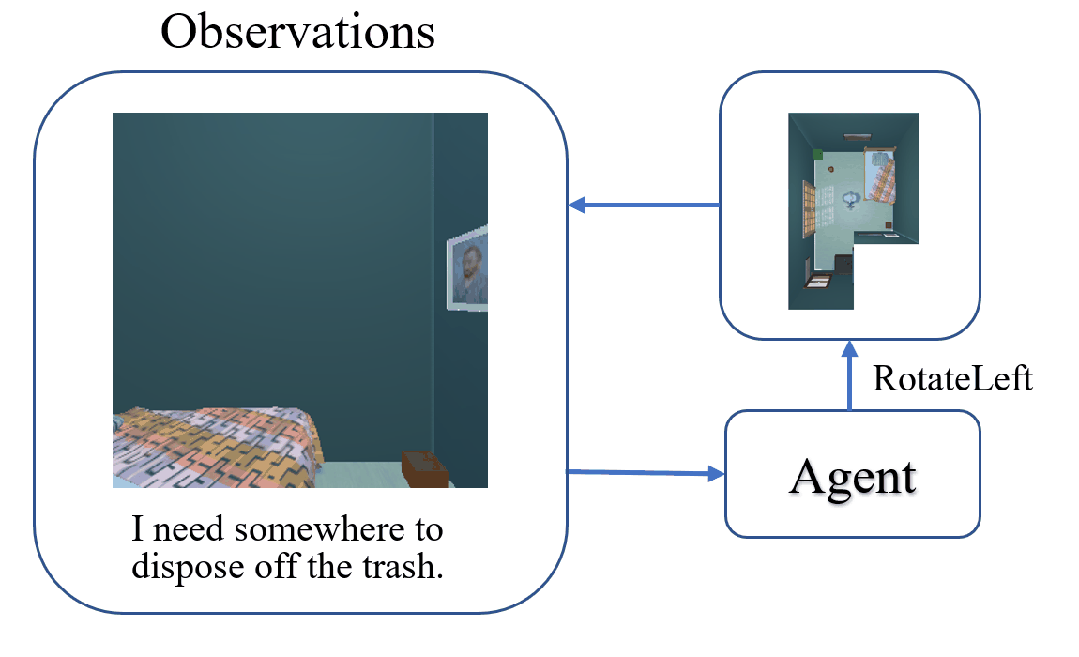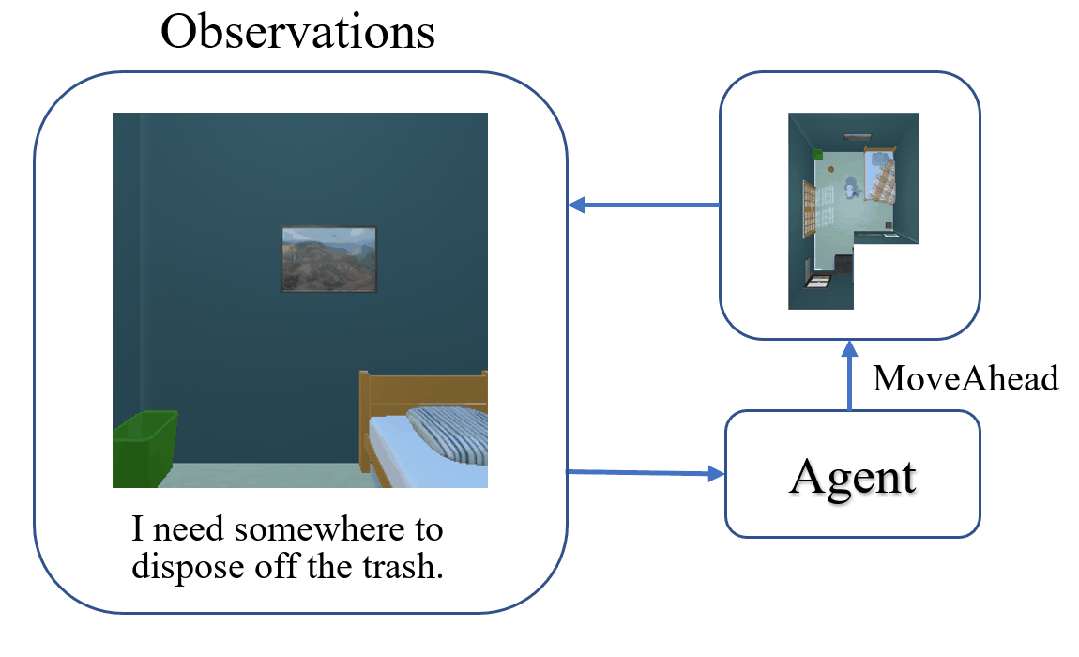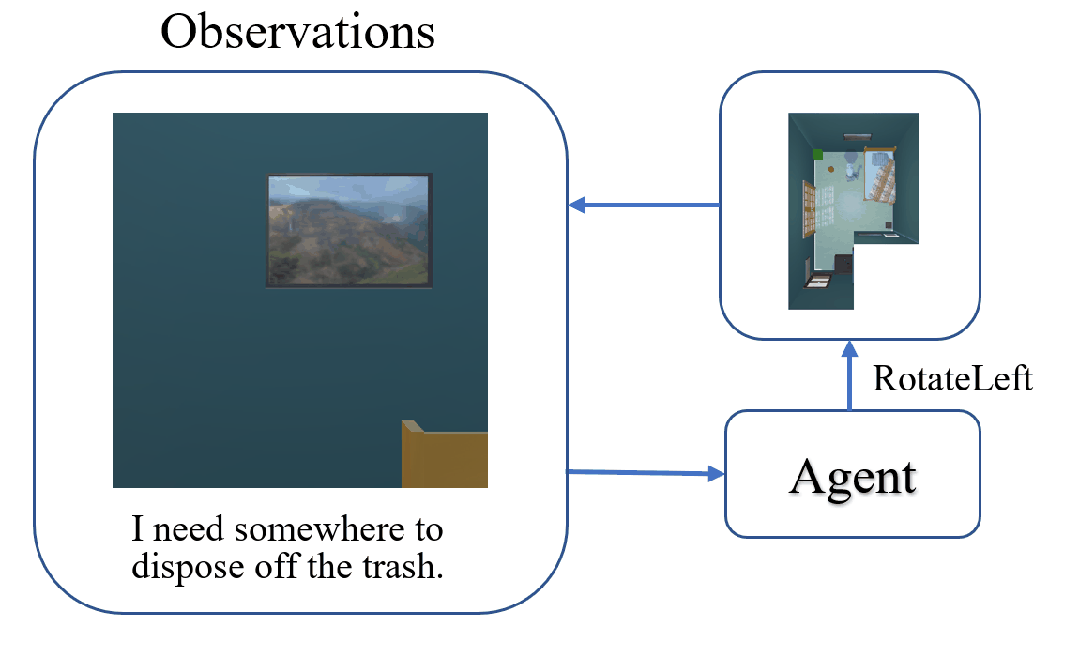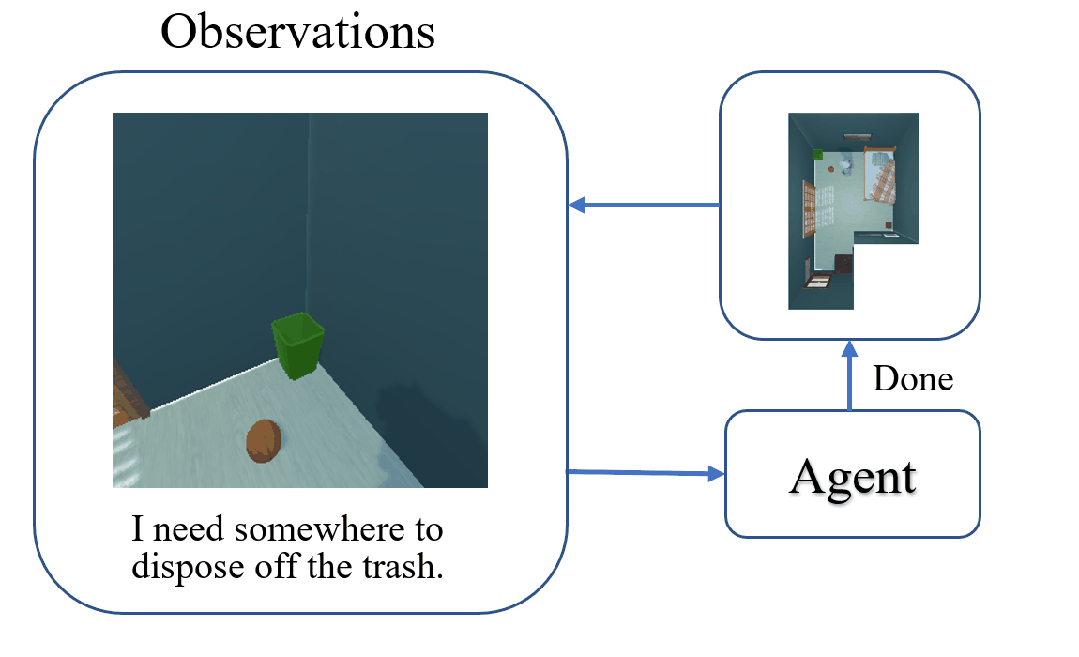
The task of Visual Object Navigation (VON) involves an agent's ability to locate a particular object within a given scene. In order to successfully accomplish the VON task, two essential conditions must be fulfilled:1) the user must know the name of the desired object; and 2) the user-specified object must actually be present within the scene. To meet these conditions, a simulator can incorporate pre-defined object names and positions into the metadata of the scene. However, in real-world scenarios, it is often challenging to ensure that these conditions are always met. Human in an unfamiliar environment may not know which objects are present in the scene, or they may mistakenly specify an object that is not actually present. Nevertheless, despite these challenges, human may still have a demand for an object, which could potentially be fulfilled by other objects present within the scene in an equivalent manner. Hence, we propose Demand-driven Navigation (DDN), which leverages the user's demand as the task instruction and prompts the agent to find the object matches the specified demand. DDN aims to relax the stringent conditions of VON by focusing on fulfilling the user's demand rather than relying solely on predefined object categories or names. We propose a method first acquire textual attribute features of objects by extracting common knowledge from a large language model. These textual attribute features are subsequently aligned with visual attribute features using Contrastive Language-Image Pre-training (CLIP). By incorporating the visual attribute features as prior knowledge, we enhance the navigation process. Experiments on AI2Thor with the ProcThor dataset demonstrate the visual attribute features improve the agent's navigation performance and outperform the baseline methods commonly used in VON.
Paper: https://arxiv.org/abs/2309.08138
Project: https://sites.google.com/view/demand-driven-navigation/home