




可视计算与学习实验室
一、课题组简介
可视计算与学习实验室由陈宝权教授于2018年创立,面向一系列新兴技术,主要服务于与可视计算密切相关的机器人和内容创作领域。可视信息是人类、智能机器进行日常生活和交流的关键,为后者提供理解和分析,在计算机图形学、计算机视觉、机器学习、大数据、虚拟现实和增强现实以及机器人等领域吸引了广泛关注。
二、课题组成员
 |
| 陈宝权 |
| 计算机图形与可视化 |
三、课题组代表成果
1. 物理仿真
随着计算机图形学技术的飞速发展,逼真的几何形状和渲染效果已经不再是人们关注的唯一重点。具有物理真实感的运动生成与控制,以及基于物理原理的交互响应等成为计算机图形学领域的热门研究方向。针对现有物理仿真工作中普遍存在的计算量大,解算速度慢,可控性差,以及效果逼真度有限等问题,本小组的主要研究内容包括如下几个方面:
(1)磁流体仿真
在计算机图形学领域,研究者们已能够在宏观的尺度下模拟流体的运动,同时真实地反映出微观机理所引发的表面相互作用。铁磁流体作为一种新兴的纳米材料,其独特物理性质使得它在工业生产与艺术创作中越来越具有重要的地位。但针对铁磁流体的完全基于物理的仿真模拟还处于初级阶段。本课题扩展了传统的基于网格的流体模拟方法,使之具有耦合与磁场间相互作用的能力;巧妙地采用了浸润边界与虚拟流体相结合的方法,在兼顾了正确性与稳定性的同时,解决了物理量界面跳变的困难。

(2)数据驱动的物理模型反演
具有物理真实感的计算机动画关键在于建立所仿真对象的数学模型。现有模型中存在的过度简化和模型参数与真实系统存在的较大偏差,严重损害了仿真结果的精确性与逼真性,极大的限制了计算机动画技术的实际应用。随着传感器技术和动作捕捉技术的飞速发展,数据驱动方法为计算机动画提供了一种新的途径。通过各种信息获取设备获得研究对象的真实行为数据后,即可利用机器学习、概率统计等数学理论和方法从数据中分析获得所研究对象数学模型,再通过各种仿真技术得到新的运动轨迹。
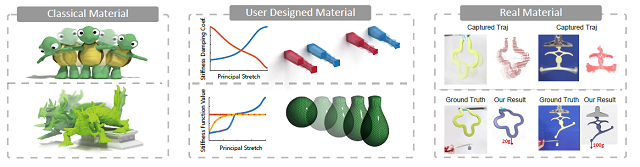
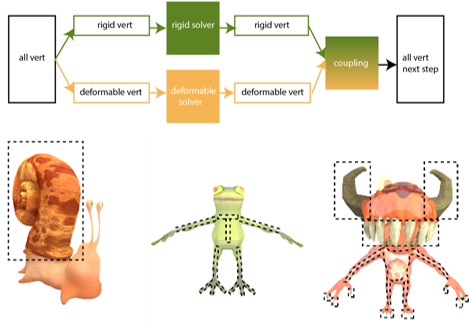
(3)带有骨骼的弹性物体模拟
在计算机游戏,虚拟现实和其他很多与计算机交互的应用中, 模拟的对象通常是有带有骨骼的弹性物体。 因为自然界中常见的动物多为带有骨骼的弹性物体。 布娃娃系统常常被用来模拟带有骨骼的结构, 但是布娃娃系统只是模拟了骨骼的集合, 因此不能够展现弹性物体的效果。 如果单纯使用弹性物体的模拟又不能表现出内在骨骼的效果。本课题专注于模拟弹性物体和刚体的结合体,从而省略了弹性物体和刚体耦合的处理。 并且对于弹性物体和刚体部分基于各自运动的规律和数学公式分别进行加速。
2. 三维形状表征和形体生成
三维形状表征和形体生成是计算机图形学和计算机视觉领域的一个重要问题。图形学关注物体在三维空间的表达形式、三维特征和分布,而计算机视觉关注如何三维感知和推断,从图片估计和恢复三维结构及其他高级属性信息。
基本的三维结构数据形式包含体素(voxel)、点云(point clouds)、多边形网格(mesh)以及隐式曲面(implicit function)等。三维表征学习在上述数据形式的基础上,将三维形状整体地或者逐部件地映射到低维空间,采用深度神经网络等参数化模型来对三维结构分布进行学习。我们从多个角度展开研究,包括考虑物体不同组件的语义和功能信息,数据驱动的三维形状生成和形状补全,以及跨类形状融合等课题。

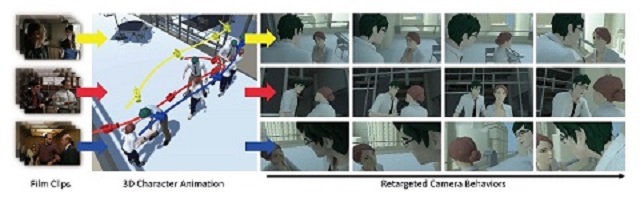
3. 视频和运动合成
相机运动控制是在虚拟内容创作与真实场景拍摄中都有广泛的应用。基于固定参数化控制的相机模型的表达形式较为单一,而基于优化的方法则需要消耗较多的计算时间。同时,在电影等艺术影像的拍摄中,镜头往往具有特殊的语义信息,传统方法很难捕获并利用。本课题以相机拍摄手法的分析、提取与利用为切入点,通过深度神经网络从无标注的生成和真实影像数据中学习相机运动与人物行为的联系,将复杂的控制信息映射到低维空间,再重新应用到新的场景拍摄中。在该模型框架下,用户可以通过指定不同的样例视频,来获得不同的目标场景拍摄结果,且拍摄的效果与指定的样例视频具有相似的视觉效果。
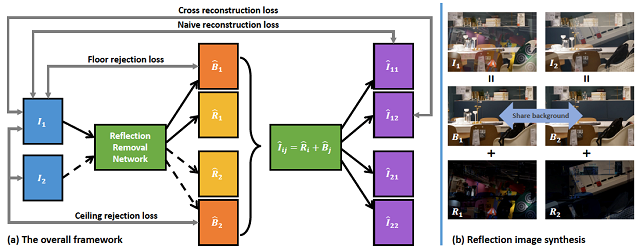
4. 图像分析与处理
从图像中感知场景信息、对图像进行复原和增强是计算机视觉、计算机图形学中的一个重要研究方向。目前,计算机视觉和图像处理中的很多任务如图像分割、图像识别、运动识别、深度估计、三维重建等,都会受到场景颜色纹理或者光照现象的干扰。因此,如何从图像中分解出场景的材质问题信息和光照信息具有重要的研究价值。当相机隔着玻璃拍摄场景时,常会受到相机一侧的光经过玻璃反射产生的干扰。合理去除图像中的反光成分,同时不引入新的噪声,不仅可以提升图像的可视效果,而且有助于图像识别、图像分割等其他视觉任务,是图像处理任务中的重要课题。针对以上问题,获取具有标签的真实数据集十分困难,限制了深度学习算法在解决以上问题时的性能。为此,我们从多个方面展开研究,包括构建高质量的渲染的本征分解数据集、结合深度学习与传统算法、设计自监督网络模型以提升效果和泛化能力等。

5. 多机器人环境三维感知
多机协同和场景建模是计算机视觉、计算机图形学和机器人领域的一个重要问题。从无人车、室内服务机器人等人工智能应用,到虚拟、增强现实等人机交互技术,他们都离不开对环境的三维感知。三维感知可以归纳为同时定位与地图构建(SLAM)问题,既要建立周围环境的三维信息,也要确定自身在环境中所处的位置姿态,二者相辅相成。近年来,随着硬件的进步,机器人开始在越来越多的科研和工程项目中发挥作用,同时也引入了新的问题。在复杂的真实环境中,人类有着丰富的知识可以应对不同的状况。如何使机器人能够像人类一样具备应对复杂场景的三维感知能力,是目前研究的热门方向。我们从多个方向研究环境三维感知,主要包括复杂场景中的相机定位(和重定位)、机器人路径规划、多机协同、未知场景探索建模等课题。
