






静5青年讲座回顾:刘峻宇博士谈量子人工智能:从近期到容错
2023年7月10日,来自芝加哥大学的刘峻宇博士访问北京大学前沿计算研究中心,在静园五院做了题为“Quantum AI: From Near-term to Fault-Tolerance”的报告。报告由中心助理教授李彤阳老师主持。

刘峻宇博士报告现场
刘俊宇博士首先介绍了量子计算领域的现状。目前的量子计算机能控制一定数量的量子比特,计算过程中存在着不可忽视的噪声,这被称为嘈杂中型量子时代(noisy intermediate-scale quantum era, NISQ era)。量子比特数量以及噪声的干扰严重限制了当下的量子计算机的应用,研究者们也在探索如何在这样的限制下发挥量子计算的优势。
接着刘博士介绍了一些当下量子计算领域的重要问题和自己的思考:
1. 在硬件方面:
如何消除噪声。目前的对于噪声的主要解决方案有两种,一是量子纠错(quantum error correction),一个有着长远价值但因其巨大开销在实践上非常困难的解决方案,二是量子错误缓解(quantum error mitigation),一个在近期的折衷方案,但是其规模难以扩大。那么是否存在量子纠错和量子错误缓解之间的的方案?能否对于特定的算法设计更容易实现的量子纠错算法?是否存在混合的量子纠错算法优于现有算法?
2. 在软件方面:
1) 找到应用前景。当下的几个著名的量子算法的应用的限制不小:分解质因数的 Shor 算法局限在密码学和金融领域,Grover 算法只能拿到根号加速,HHL/量子线性方程求解算法可能需要量子随机存储器(QRAM)并且有被去量子化的可能,量子模拟目前主要还是被用于物理和量子化学中。探索这些算法更多的应用领域是一个重要的理论和实践方面的问题。
2) 一些其他的软件相关的问题:噪声对算法一定是有害的吗,我们能否在算法中利用噪声;如何看待启发式的算法和被证明有量子优势的算法。
接着进入本次讲座的正题:量子机器学习。量子机器学习是指在量子设备上运行一些和机器学习相关的算法。刘博士将自己和量子机器学习相关的工作分成了 NISQ 时代以及未来的容错量子计算(fault-tolerant quantum computing)时代两类并分别进行了介绍。

在 NISQ 阶段,刘博士主要介绍了自己关于量子神经正切核理论(quantum neural tangent kernel theory, QNTK theory)相关的工作。
在 NISQ 阶段,一类由参数化量子电路和经典优化器组成的变分量子算法(variational quantum algorithms, VQAs)被认为可能取得优于经典算法的效果。这里参数化量子电路由一些参数化的量子门组成。接下来,定义和该量子线路的某个观测量的期望相关的损失函数,并通过对该观测量的测量以及经典的优化器来寻找损失函数的最低值,这就是变分量子算法的基本框架。而 QNTK 理论则试图回答以下问题:如何选取参数化量子电路的结构,优化过程的收敛速度,优化过程的动力学性质,以及量子机器学习和机器学习的区别。
首先我们列出在梯度下降在步长很小时量子电路参数Θ和残差ε近似满足的差分方程D_{\varepsilon}=-\eta K_{\varepsilon},仿照经典 NTK 理论,这里K被称为量子神经正切核。可以注意到,如果K为常数,那么ε的解ε(t)=(1-\eta K)^{t}ε(0)是指数下降的,但一般情况下K是随Θ变化的,甚至是高度震荡的,所以无法得到解析解。

不过在某些特定的情况我们仍能拿到近似解,例如在懒惰训练(lazy training)的情况下,Θ变化很小,K的变化不超过常数倍,这时可以用微扰论来分析ε的变化。另一种情况是仿照经典对宽度趋于无穷的神经网络的分析,我们假设参数化量子线路是随机产生的,并且其分布比较均匀(满足k-design 条件),那么可以计算出量子神经正切核K的均值\bar{K}=\frac{L \operatorname{Tr}\left(O^{2}\right)}{N^{2}} \propto L正比于参数个数L,标准差\Delta K \propto \frac{\sqrt{L}}{N^{2}}正比于\sqrt{L},也就是说随着参数L的增大,相对标准差\Delta K/\bar{K}会很小,也就是K高概率是一个常数,因此我们可以用\bar{K}来近似描述残差ε衰减的速率。但同时也注意到\bar{K}和希尔伯特空间的维数N平方反比,因此理论上会出现梯度过小,难以优化的贫瘠高原(barren plateaus)现象,但毕竟这是极限情况下的理论分析,在实际问题中K不一定这么小。刘博士接着展示了一些在 IBM 量子计算机上的实验结果,能够观察到在训练接近结束时出现的懒惰训练现象以及\bar{K}和\Delta K随参数量变化的规律。在监督学习中,K会由数变成矩阵,这时需要研究更复杂的量子元核(quantum meta-kernel)来分析。
接着刘博士简单介绍了自己关于噪声对变分量子算法的影响的工作,例如噪声对于逃离鞍点的帮助。
上面的部分都是与 NISQ 阶段算法相关的理论,接下来,刘博士介绍了自己和容错量子计算阶段的机器学习算法相关的工作,该工作主要依赖于 HHL 算法和对耗散常微分方程的线性化。
HHL 算法是被用来解线性方程组的量子算法,相比经典算法在矩阵维数上有指数加速。而对于耗散的常微分方程,通过卡莱曼线性化方法(Carleman linearization)可以将其以较小误差转化为线性方程,从而使用 HHL 算法加速求解。
在优化中最常见的梯度下降过程就是一个耗散的过程。而对于一般的机器学习中的优化过程,耗散性取决于海森矩阵的特征值:矩阵的正特征值越多,系统耗散性越强,此时上述的量子算法越有效。经过实验发现,在学习的早期,海森矩阵的特征值正负分布一般不对称,量子算法一般会有优势,而在发现海森矩阵的特征值分布变得正负对称时,可以将训练转移到经典计算机。
接下来是一些算法实现中的问题,对于训练数据在经典和量子计算机间的转移,需要假设神经网络和量子态都是稀疏的,才能保证高效的量子-经典数据转换,这就需要对神经网络进行剪枝,但又不能损失太多表现。同时,对于高维海森矩阵的谱的估计,需要使用蒙特卡洛算法来加速。
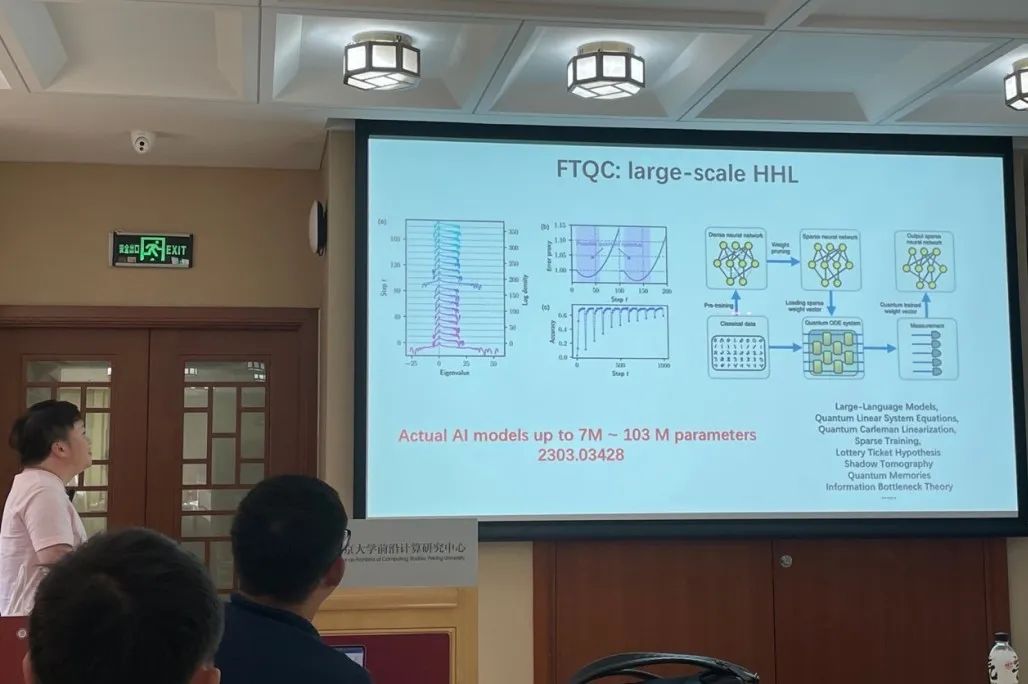
最后作为总结,刘博士认为量子机器学习是一个很重要的领域。短期来看,变分量子算法是 NISQ 设备上最主要的机器学习算法,可以通过 QNTK 理论来分析其表现,另一方面噪声对学习的影响也值得探索。长期来看,HHL 算法是量子机器学习的重要基础,刘博士和合作者对稀疏耗散机器学习算法应用了 HHL 算法,并展示了其通常是高效的。