






姜少峰课题组 ICML 2023 入选论文解读:k-median问题可以只用均匀采样解决吗?
本文是 ICML 2023 入选论文 The Power of Uniform Sampling for k-Median 的解读。该论文由北京大学前沿计算研究中心姜少峰课题组与南京大学计算机软件新技术国家重点实验室的黄棱潇副教授合作完成。按照理论计算机科学领域惯例,作者按姓名首字母排序。
文章针对k-median 聚类问题,探索使用多少个随机采样样本足以计算出原数据集上的(1+ε) -近似最优聚类中心。论文主要解决了k>1的情况并且能够推广至不同的度量空间。
论文链接:https://arxiv.org/abs/2302.11339
01 问题介绍
k-median 问题是一个经典的聚类问题,旨在寻找一个大小为k的点集作为聚类中心,使得所有数据点到聚类中心的距离和最小化。我们称一个聚类中心C是一个(1+ε) -近似最优解,当且仅当
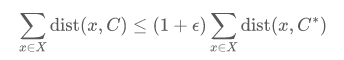
其中,C*为最优聚类中心。
近年来,如何使用数据摘要(data reduction)方法解决聚类问题成为了研究焦点。其中一种被广泛研究的数据摘要方法为核心集(coresets)。简单来说,一个ε-核心集是一个极小数据摘要,使得对于所有的聚类中心C,在核心集上计算得到的目标函数的值与在原数据集上计算得到的值的相对误差不超过ε 。通过在核心集上运行近似算法,我们可以得到原数据集上的一个近似最优解。
然而目前已有的所有核心集构造算法在查询复杂度(query complexity)上不够高效。特别地,这些算法必须访问数据集Ω(n)次(n为数据集大小),而这是因为核心集构造算法依赖于非均匀采样,需要访问整个数据集以计算复杂的采样分布。另外,这种复杂的采样过程也使得算法通常在实践中难以实现。
为了得到具有亚线性询问复杂度(即,o(n)复杂度)的数据摘要算法,我们考虑一种非常自然的方法——均匀采样。尽管先前工作已经证明均匀采样无法在亚线性询问复杂度内得到核心集,但是均匀采样依然凭借着其简单的算法流程在实践中被广泛运用,并且通常能取得不错的实际效果。本文旨在从理论上分析均匀采样作为数据摘要方法的询问复杂度。
02 主要结果
在实践中,我们通常希望得到的聚类是平衡的,即希望每个类都包含几乎相同数量的数据点。
因此,我们尝试在询问复杂度与数据平衡性之间建立联系。定义数据集X的平衡系数β为最大的在(0,1]间的实数满足:存在X的一组最优k-median 聚类方案使得每个类包含的点数至少为βn/k 。本文首先证明了一个理论下限:任何一个可以计算O(1)-近似最优解的算法必然有询问复杂度Ω(1/β),其中β为数据的平衡系数。在极端情况下,β可以等于O(1/n),即存在一个类只包含一个点,此时询问复杂度的理论下界为 Ω(n)。因此该结论同样否定了在没有任何假设的情况下,亚线性询问复杂度算法的存在性。
另一方面,我们证明了如果假设数据集的平衡系数β=w(1/n),那么均匀采样算法足以用于设计亚线性询问复杂度算法。具体来说,我们证明了:对于一个欧氏空间中的数据集X,若它的平衡系数为β,假设我们从X中均匀采样\widetilde{O}\left(\frac{k^{2}}{\beta \epsilon^{3}}\right)个样本得到集合S,那么我们可以利用S计算出在原数据集X上的(1+ε)-近似最优解。我们的算法同样非常简单,只需要在S上计算一个带有平衡系数限制的k-median 问题的 (1+ε)-近似最优解即可。我们通过证明这个解就是在原数据集上的(1+O(ε)) -近似最优解,从而证明了该结论。
值得注意的是,该结论在关于β的相关性上已经接近了理论极限,并且做到了与数据集规模n 以及欧氏空间维度d无关。对比先前的工作,[MOP04] 同样考虑了平衡假设,但是只得到了一个具有常数近似比的算法;[MS18, CSS21, Dan21] 考虑了k=1的情况(在这个情况下,β=1),但是在他们的结果中,询问复杂度或者与d有关,或者具有一个较差的 ε^{-4}的因子。
除此之外,本文的结果还可以拓展到其他度量空间,比如加倍空间(doubling metric space)和有限树宽的图的最短路度量(shortest-path metrics of graphs with bounded treewidth)。
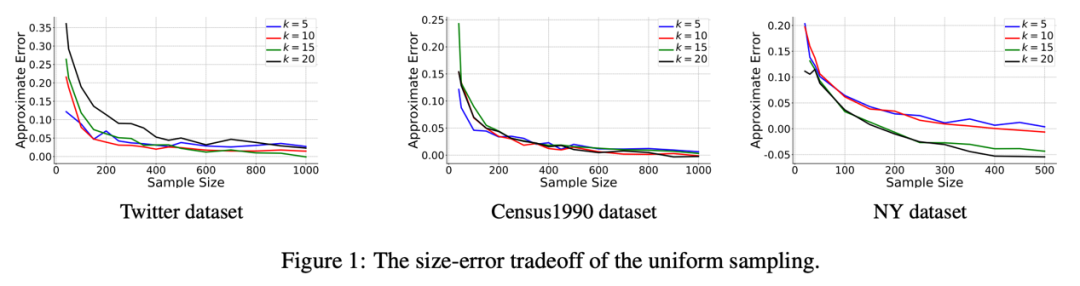
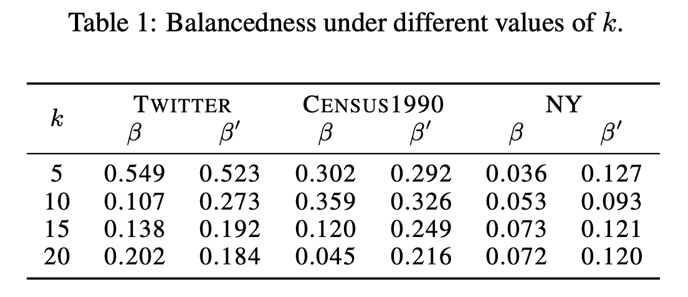
最后,本文在多个数据集上测试了均匀采样的效果。我们对数据集进行采样,在采样样本上运行了一个针对k-median 问题的局部搜索算法(不带平衡系数限制),并估计解在原数据集中的近似比。实验结果表明,均匀采样具有出色的数据摘要能力。此外,通过比较数据集的平衡系数(β)和计算得到的聚类的平衡系数(β'),我们发现在样本集上使用不带平衡系数限制的聚类算法通常可以计算出平衡的解。结合我们的理论结果,这解释了为什么在实践中,通常只需要在样本集上运行聚类算法即可得到不错的解。
参考文献
[CSS21] Vincent Cohen-Addad, David Saulpic, and Chris Schwiegelshohn. Improved coresets and sublinear algorithms for power means in Euclidean spaces. In NeurIPS, pages 21085–21098, 2021.
[Dan21] Matan Danos. Coresets for clustering by uniform sampling and generalized rank aggregation. Master’s thesis, Weizmann Institute of Science, 2021.
[MOP04] Adam Meyerson, Liadan O'Callaghan, and Serge A. Plotkin. A -median algorithm with running time independent of data size. Mach. Learn., 56(1-3):61–87, 2004.
[MS18] Alexander Munteanu and Chris Schwiegelshohn. Coresets-methods and history: A theoreticians design pattern for approximation and streaming algorithms. Künstliche Intell., 32(1):37–53, 2018.