






王鹤课题组 CVPR 2023 入选论文解读:UniDexGrasp:通用灵巧手抓取算法
本文是 CVPR 2023 入选论文 UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy 的解读。本论文由北京大学王鹤研究团队与北京通用人工智能研究院、斯坦福大学、清华大学合作,提出了对于一个单独放置在桌面上的物体的点云输入,使用五指灵巧手进行抓取的方法。
我们将灵巧手抓取物体的过程分为两个阶段,第一阶段针对物体点云输入生成若干静态抓取手势,从中挑选一个作为目标手势之后,第二阶段使用基于目标手势的强化学习策略来执行抓取。值得注意的是,我们的抓取算法能够在总共133类3441个物体间泛化,其中包括了241个训练时未见过的物体。同时,我们在最后也展示了将抓取算法分为两阶段的应用前景,即可以通过指定抓取手势来适应下游任务,诸如实现功能性操作等。
论文链接:https://arxiv.org/abs/2303.00938
项目主页:https://pku-epic.github.io/UniDexGrasp/
代码地址:https://github.com/PKU-EPIC/UniDexGrasp

图1. 左半部分:抓取手势生成。对于小图中的每一个物体,我们都生成了若干个拥有不同旋转、位移与手指关节角度的抓取手势。右半部分:基于目标的抓取执行。对于一个飞机形物体,图中左下角和右下角分别展示了两种可能被选定为目标的手势,大图中对应颜色的轨迹便是分别基于这两个目标手势下由策略网络执行的抓取。
01 引 言
机器人抓取是智能体与环境交互的基本能力,是操作的先决条件,几十年来一直被广泛研究。近年来,二指抓夹的抓取算法的研究取得了很大进展,对于抓取未知物体的通用方法也具有较高的成功率。然而,二指抓取的一个基本限制是它的低灵巧性,这限制了它在复杂和功能性物体操作中的应用。灵巧抓取提供了一种更多样化的抓取物体的方式,因此对于机器人功能和精细物体操作至关重要。然而,灵巧手的驱动空间的高维度既是赋予灵巧手这种多功能性的优势,也是难以执行成功抓取的主要原因。作为一种广泛使用的五指机器人灵巧手,ShadowHand[1]拥有26个自由度(DoF),而典型的平行夹持器则为7个自由度。这种高维度加大了生成有效抓取姿势和规划执行轨迹的难度,从而迫使灵巧抓取任务的研究采取与平行抓取任务不同的方法。一些工作已经研究了抓取姿态合成问题,但是它们都假设了输入包含完整的物体几何与状态。很少有工作研究在现实的机器人环境中处理灵巧抓取,但到目前为止,还没有研究提出通用和多样化的灵巧抓取,可以很好地泛化到训练时未曾见过的物体。
在这项工作中,我们解决了这个非常具有挑战性的任务:学习一个通用的灵巧抓取方法,可以在仿真的场景中很好地泛化到数百种训练时见过或是未见过的物体类别,并且输入仅包含相机拍摄的深度信息和描述机器人自身状态的自我感知参数。我们使用的数据集[2]包含来自133个物体类别的5519个物体实例的100多万种抓取手势,这是目前最大的机器人灵巧手抓取数据集。
受二指平行抓取器的成功工作的启发,我们提出将这一具有挑战性的任务分解为两个阶段:1)灵巧抓取手势生成。在此阶段中,我们根据点云观测生成不同的抓取姿势;2)基于目标抓取执行,以在阶段一生成的手势中选取的一个抓取目标手势为条件,生成符合目标手势且物理上可行的运动轨迹。这两个阶段的任务依然非常具有挑战性,对于每个阶段,我们都贡献了一些创新,如第二部分所述。
大量的实验证明了我们方法流程的卓越性能。在抓取手势生成阶段,我们的方法是唯一在保持高抓取质量的同时表现出高度多样性的方法。而从视觉输入到抓取执行的整个的抓取流程也在我们的仿真环境中取得了令人印象深刻的表现,并首次展示了一个通用的抓取策略,成功率超过60%,显著优于所有基准方法。
02 方法简介
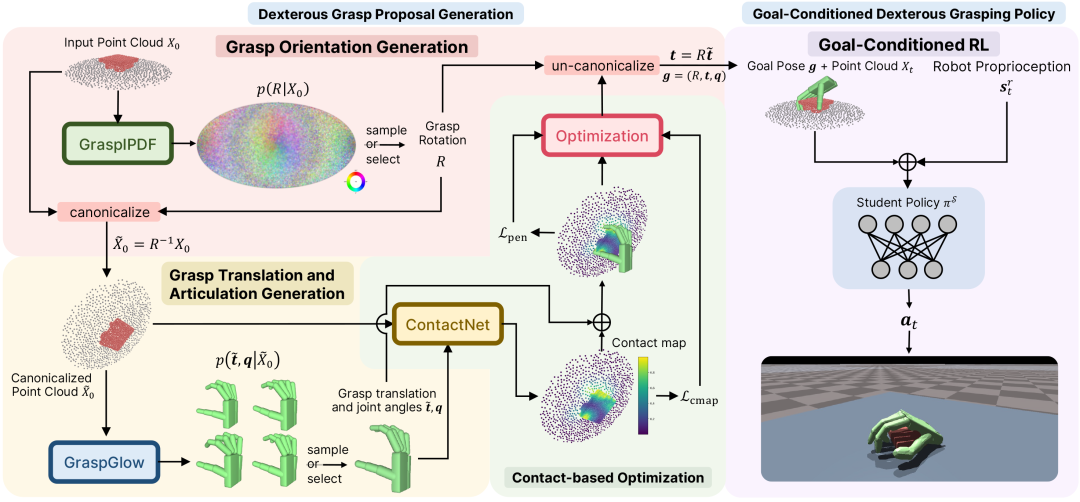
图2. 方法概览。左侧为第一阶段,生成灵巧抓取手势。输入为由深度图像融合而成,处于初始时刻0的目标点云X_{0} ,其中包含物体和桌面的准确分割。旋转R从 GraspIPDF 所隐含的分布中采样,点云将被此旋转规范化至\tilde{x}_{0}。然后,GraspGlow 对平移\tilde{t}和关节角q进行采样。接下来,ContactNet 从生成的手上采样的点云\tilde{x}_{H}来预测物体上的理想接触图c。然后,根据接触图对预测出中手的手势进行优化。通过R变换最终目标姿态,使其与原始视觉观测对齐。右边部分是第二阶段,基于目标手势的灵巧手抓取策略,采用目标g、点云X_{t}和机器人本体感觉 s_{t}^{r}采取相应的行动。
如图2所示,方法的流程分为左右两个阶段:第一阶段针对物体点云输入生成若干抓取手势,从中挑选一个作为目标手势之后,第二阶段使用基于目标手势的强化学习策略来执行抓取。
在生成抓取手势时,由于我们发现将旋转的SO(3)空间与平移和关节角的欧式空间解耦,并且在最后附加基于接触图的优化过程,将会获得更稳定有效的生成流程,因此生成抓取手势总共分为三个子模块。
生成总体旋转的模块 GraspIPDF 受到了 ImplicitPDF [6](缩写为 IPDF)的启发,使用神经网络来隐式表达概率分布p(R|X_{0})使得我们可以从中采样。
在确定了一个旋转之后,我们将整个观察到的点云规范化至\tilde{x}_{0},作为输入进入第二个模块 GraspGlow。Glow[5] 是一种常用的基于标准化流来建模欧式变量的方法,而 GraspGlow 则利用它来建模p(\tilde{t}, q|\tilde{x}_{0})=p(t, q|X_{0}, R)。
由于我们在前两个阶段致力于生成多样性的抓取,因而基于概率采样出的抓取手势在精确度方面不可避免地有所下降。所以我们需要第三个子模块,即通过接触图来优化概率采样得到的抓取手势。ContactNet 的输入是并不完美的抓取手势与物体点云(训练时我们通过扰动完美的抓取手势来实现这一效果),输出是对物体点云中的每一个点的在[0,1]区间内的理想接触热力值,越靠近0表示离理想接触时的手越远,越靠近1表示离理想接触时的手越近。
为了使概率采样得到的手更接近理想接触时的手,一方面我们通过自监督的损失函数来微调 GraspGlow,这个损失函数包含了:1. 预测的理想接触图与由 GraspGlow 输出的手计算得到的接触图之前的差异;2. 物体点云穿透进手的网格的距离平方值;3. 手上预先选定的点位穿透进平面的深度;4. 自穿透。
另一方面,在测试时,我们也设计了能量函数来直接优化手势,这个能量函数包含的项与自监督的项相同,只是直接优化手势参数,而不是用来微调 GraspGlow。
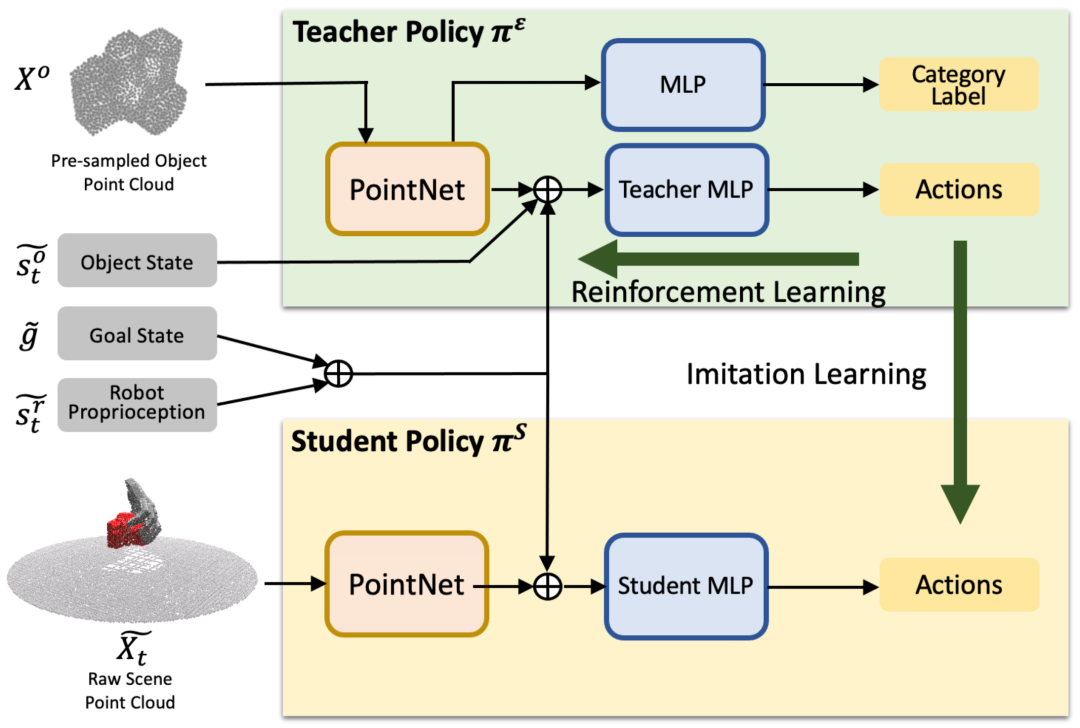
图3. 基于手势目标的策略学习流程图。
在执行目标手势的强化学习时,如果直接基于点云以及描述机器人自身状态的自我感知参数,这两个真实世界能够获取的输入,那么学习的难度极大。所以,我们采用了师生学习框架(Teacher-Student Learning Framework)。即我们首先学习一个可以访问全知状态输入的全知教师模型,然后将其蒸馏为只接受实际输入的学生模型。不过尽管教师策略获得了对全知信息的访问权,但使其成功地抓取与不同抓取手势目标配对的不同物体仍然是艰巨的任务。为了提升模型训练的效率和以及在不同类别物体之间的泛化性能,我们设计了以下3个技巧:1. 状态标准化;2. 对于物体的课程学习;3. 使用分类任务协助训练。
我们使用状态规范化(state canonicalization)来提高具有不同目标输入的强化学习的样本效率。具体而言,我们使用了机器手根部在世界坐标系中绕z轴的初始欧拉角\varphi作为规范化处理的参数。同时,我们将状态从世界坐标系转移到这个参考坐标系下。这样做可以使得模型更加高效地学习到不同目标输入下的抓取策略。
同时,我们提出了物体课程学习(object curriculum learning)的方法,用于训练机器人在不同类别的物体上进行灵巧抓取。该技术可以帮助机器人更好地学习到不同类别物体的抓取策略,从而提高其抓取成功率。具体而言,物体课程学习技术分为三个阶段。在第一个阶段中,我们首先让机器人在单个物体上进行训练。在第二个阶段中,我们让机器人在同一类别的不同物体上进行训练。最后,在第三个阶段中,我们让机器人在所有类别的物体上进行训练。通过这种逐步增加难度的方式,我们可以帮助机器人更好地学习到不同类别物体的抓取策略,并且避免了直接在多个类别物体上进行训练时出现的失败情况。实验结果表明,使用物体课程学习技术可以显著提高机器人的抓取成功率。
我们还采用了分类任务协助训练。具体而言,我们使用物体类别分类任务提前训练视觉编码器模块并在策略学习中使用分类任务进行联合训练。
最后,我们使用知识蒸馏的方法,通过将教师策略的知识转移到学生策略中,从而提高学生策略的性能。具体而言,我们将在全知状态输入下训练的教师策略的知识转移到只接受真实世界输入的学生策略中。
03 实验结果
我们分别针对抓取生成流程、基于状态输入的模型和基于视觉信息输入的模型进行了三类实验比较。

图4. 抓取生成流程的实验结果。
对于抓取生成流程的实验,我们采用了如下的衡量标准:1. Q_{1}值[7],表示了能够成功扰动抓取手势中的物体的最小扰动。2. 物体穿透,表示了从物体点云穿透进手网格的深度。3. \sigma:表示各个指标的标准差,用来衡量我们生成的抓取的多样性。我们的比较基准则包含了使用了GraspTTA[3],DDG[8],以及 ReLie[4],ProHMR[9] 分别根据推测任务做出调整后再加上了测试时自适应(Test-Time Adaptation)的版本。可以看到,我们提出的方法兼具抓取的高质量和多样性,是其他方法无法做到的。
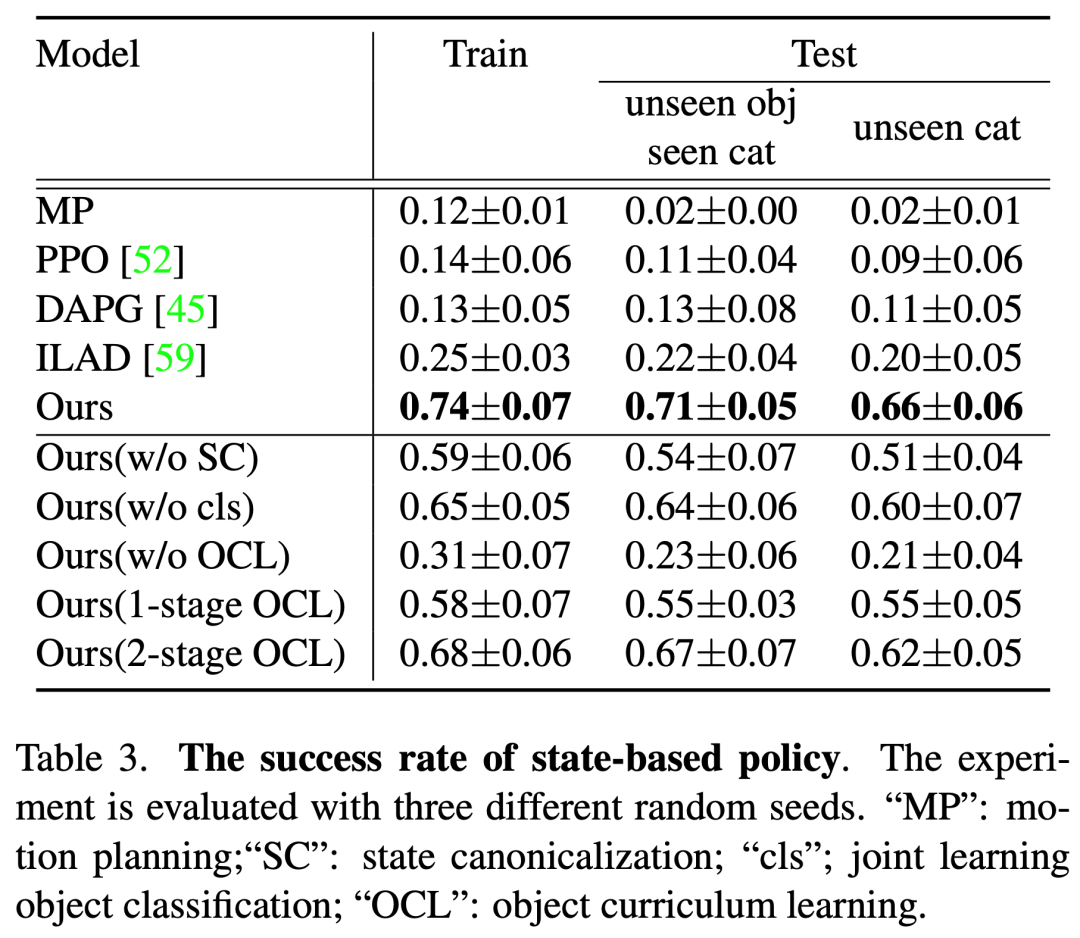
图5. 关于基于状态的模型实验的成功率。
对于抓取执行实验,提供了 UniDexGrasp 在大规模合成数据集上的实验结果。实验结果表明,UniDexGrasp 可以在不同类别的物体上实现高质量、多样化的灵巧抓取。具体而言,我们将 UniDexGrasp 与四种基线方法进行了比较,表格3中列出了这些方法在训练集和测试集上的平均成功率。结果显示,UniDexGrasp 在训练集和测试集上分别达到74%和69%的平均成功率,显著优于其他方法。于此同时,我们还做了一系列消融实验以证明了每个关键技术对最终结果的重要性。
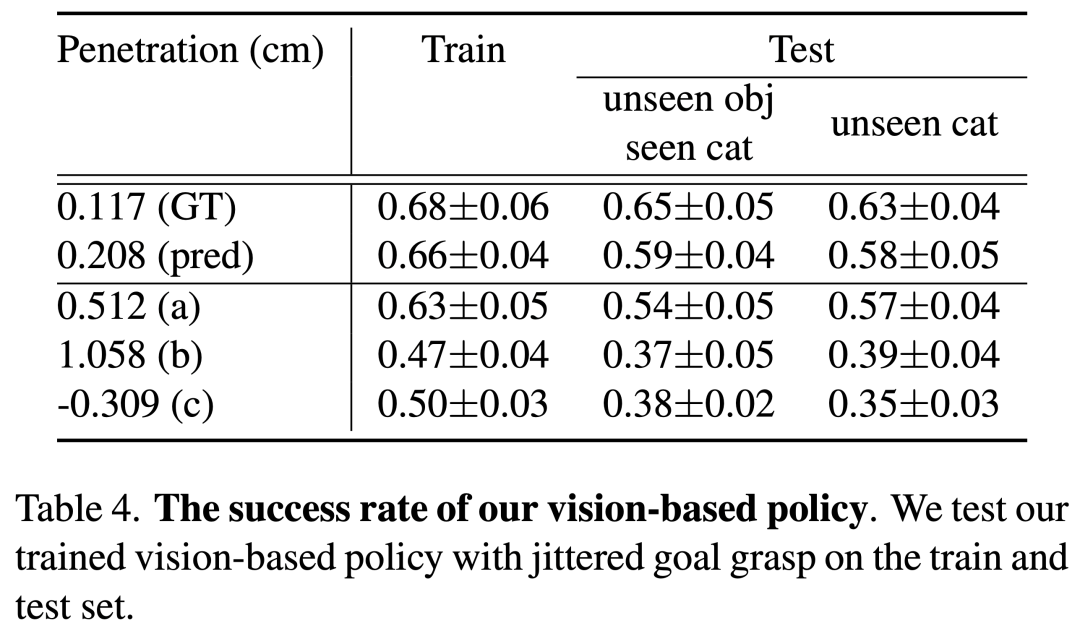
图6. 关于基于视觉信息输入的模型实验成功率。
表格4展示了基于视觉输入的学生策略的成功率。我们对比了使用训练抓取数据和使用我们视觉模块方法预测的抓取位姿进行测试的结果。同时,我们通过扰动我们预测的抓取姿势以导致小穿透 (a)、较大穿透 (b) 和无接触 (c) 来对我们基于视觉的策略进行稳健性测试,并观察到我们的抓取执行策略对此类错误具有一定的鲁棒性。
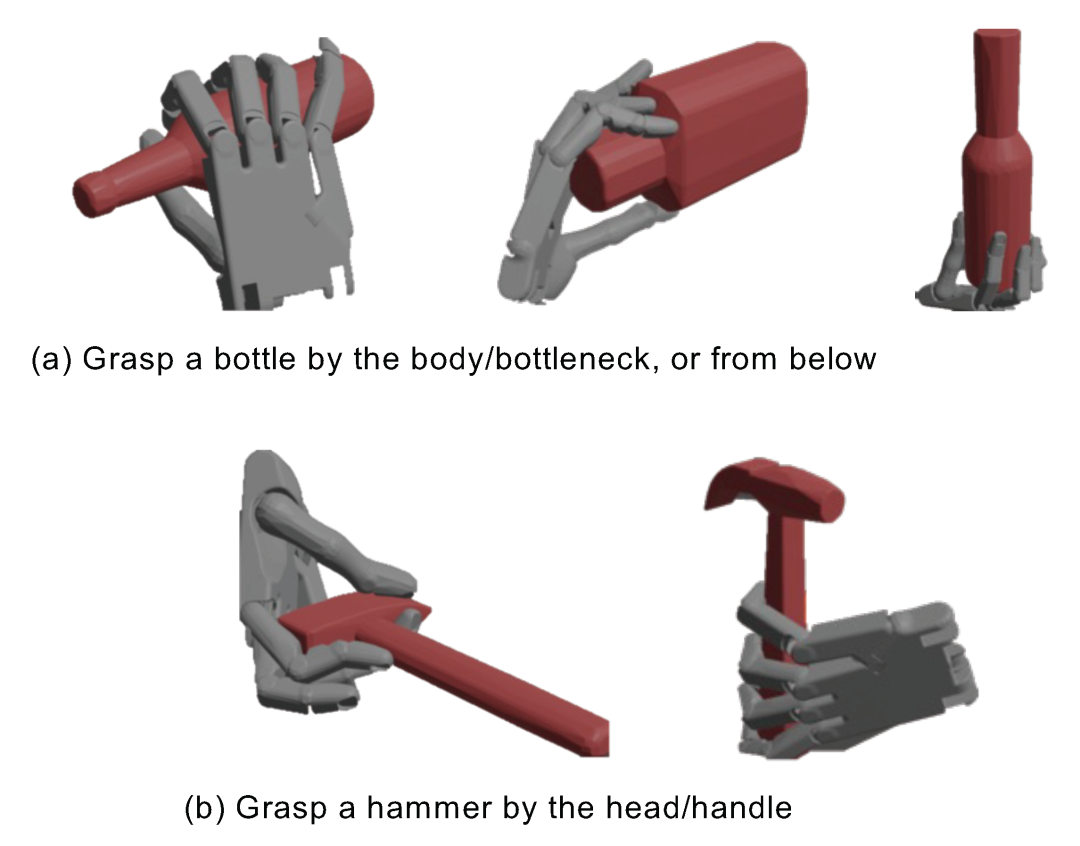
图7. 使用图像语言模型 CLIP[10] 来选择特定方式的抓取手势。
我们方法一个非常自然的应用就是加入一个语言处理模块使得机器手按照特定方式来抓取物体。给定一段文本描述,我们将生成的抓取手势渲染成图片,随后通过 CLIP 模型选择图片文本相似度最高的抓取。在我们的初步尝试中,只用了10分钟的微调,CLIP 就能在手和锤子这一组合上达到90%的准确度,这也证明了进一步应用的可行性。
参考文献
[1] ShadowRobot. URL https://www.shadowrobot.com/dexterous-hand-series/, 2005.
[2] Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation. arXiv preprint arXiv:2210.02697, 2022.
[3] Hanwen Jiang, Shaowei Liu, Jiashun Wang, and Xiaolong Wang. Hand-object contact consistency reasoning for human grasps generation. ICCV, 2021.
[4] Luca Falorsi, Pim de Haan, Tim R Davidson, and Patrick Forre ́. Reparameterizing distributions on lie groups. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 3244–3253. PMLR, 2019.
[5] Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31, 2018.
[6] Kieran A Murphy, Carlos Esteves, Varun Jampani, Srikumar Ramalingam, and Ameesh Makadia. Implicit-pdf: Non-parametric representation of probability distributions on the rotation manifold. ICML, pages 7882–7893, 2021.
[7] Carlo Ferrari and John F Canny. Planning optimal grasps. In ICRA, volume 3, page 6, 1992.
[8] Min Liu, Zherong Pan, Kai Xu, Kanishka Ganguly, and Dinesh Manocha. Deep differentiable grasp planner for high-dof grippers. arXiv preprint arXiv:2002.01530, 2020.
[9] Nikos Kolotouros, Georgios Pavlakos, Dinesh Jayaraman, and Kostas Daniilidis. Probabilistic modeling for human mesh recovery. ICCV, pages 11605–11614, 2021.
[10] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. ICML, pages 8748–8763. 2021.