






王亦洲课题组 ECCV 2022 入选论文解读:从虚拟数据学习可泛化的三维人体姿态估计模型
本文是对发表于计算机视觉领域顶级会议 ECCV 2022的论文 VirtualPose: Learning Generalizable 3D Human Pose Models from Virtual Data 的解读。该论文由北京大学王亦洲课题组与微软亚洲研究院等单位合作,通过对现有基于深度学习的绝对三维人体姿态估计方法进行泛化性能研究,针对性地提出以抽象几何表示为中间表示的方法,可以通过生成丰富的虚拟数据训练三维人体姿态估计模型。实验证明,该方法显著提升了未见过场景中的泛化性能,并且不需要成对的图像和三维人体姿态真值进行训练。
论文链接:https://arxiv.org/abs/2207.09949
01 背景介绍
在绝对三维人体姿态估计任务中,不仅需要估计人体各关节点相对于根节点(通常为人体骨盆节点)的位置,还需要估计根节点在三维空间中的绝对位置。这是一个具有挑战的问题,因为估计过程存在严重的歧义并且很多因素会影响深度估计的结果,如图1所示。
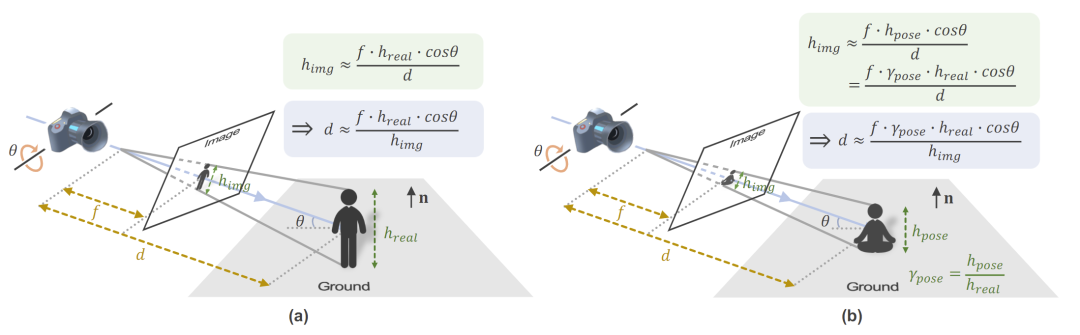
图1. 小孔成像模型中的投影几何。影响深度估计的因素包括相机焦距、相机位姿、人的身高和姿态等。
现有的方法大多直接学习从图像到人体深度的映射关系,尽管它们能在公开数据集上取得比较好的效果,但由于数据集在相机位姿、人体姿态以及图像背景上缺乏多样性,训练出的模型的泛化性能较弱。
为了解决这一问题,本工作提出了以抽象几何表示(Abstract Geometry Representation,简称AGR)为中间表示的方法,将模型拆分为两部分进行训练。其中,可以通过生成大量丰富的成对 <AGR, Pose> 数据来进行训练,从而得到泛化性能强的模型。
02 泛化性能研究
为了研究现有工作的泛化性能,本工作将基于深度学习的方法分为三类,分别是(1)自顶向下基于检测框大小的方法(TBS),(2)自顶向下基于图像特征的方法(TIF)以及(3)自底向上基于回归的方法(BDR),并从中各选取了一个具有代表性的方法进行泛化性能研究。
在实验中发现,现有的方法对图2中展现的包括相机位姿、图像背景以及人体姿态这三个因素都不够鲁棒,特别是当训练数据与测试数据的拍摄视角不相同时,误差会显著增大。

图2. 影响基于深度学习的方法的三个因素,包括 (a) 相机位姿,(b) 图像背景以及 (c) 人体姿态。
03 方法概览
为了解决这一问题,本工作提出了以抽象几何表示(Abstract Geometry Representation,简称 AGR)为中间表示的方法,VirtualPose,如图3所示。AGR 是一个一般性的概念,用来表示一些既可以帮助恢复绝对三维人体姿态,同时也可以很鲁棒地从图像中被估计以及可以根据三维人体姿态生成出来的一种几何表示。在本工作的实现中,AGR 包含了人体检测框图 B 以及二维人体姿态热图 H^2D。
AGR 将网络切分成两部分,第一部分负责对输入图像中的人进行检测和二维姿态估计,第二部分则负责根据人体检测框图 B 以及二维人体姿态热图 H^2D 估计出每个人的绝对三维人体姿态。这两个部分是单独训练的,第一部分只涉及2D 任务,可以利用大量的2D 数据集进行训练,以保证模型的鲁棒性。
在第二部分中,输入的 AGR 中已经不包含输入图像中人物外貌和背景的信息,而为了保证模型对相机位姿以及人体姿态有较强的泛化性能,本工作提出了一种训练数据生成策略。在生成训练样本时,会从人体姿态较为丰富的数据集 MuCo-3DHP 中随机挑选一些人体姿态并放置在地面上,再通过随机设置相机的位姿即可生成相应的人体检测框图以及二维人体姿态热图。
为了更好地估计绝对三维人体姿态,本工作还引入了人体根节点估计网络(Root Estimation Network,简称 REN)以及人体姿态估计网络(Pose Estimation Network,简称 PEN)分别负责对人体根节点进行定位以及估计其它关节点的位置,如图3所示。
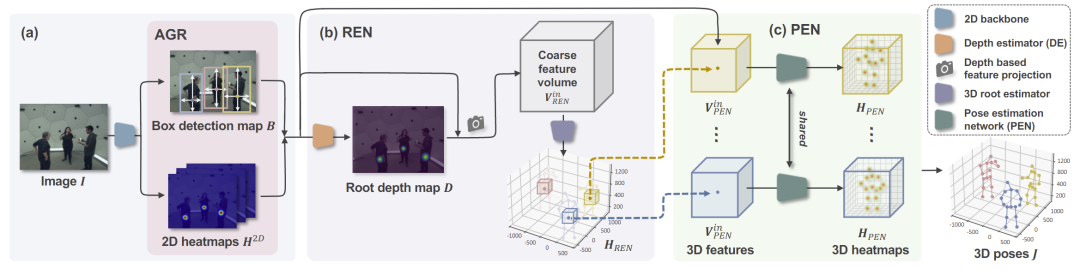
图3. 本工作提出的以抽象几何表示(AGR)为中间表示的三维人体姿态估计方法VirtualPose的流程图。
04 实验结论
本工作在两个基准数据集上评估了本文的方法,VirtualPose 均达到了最佳水平并且具有强大的跨数据集泛化能力。表1展示了在 CMU-Panoptic 上的表现,评价指标是预测姿态与真实姿态的平均关节误差值,单位为毫米。
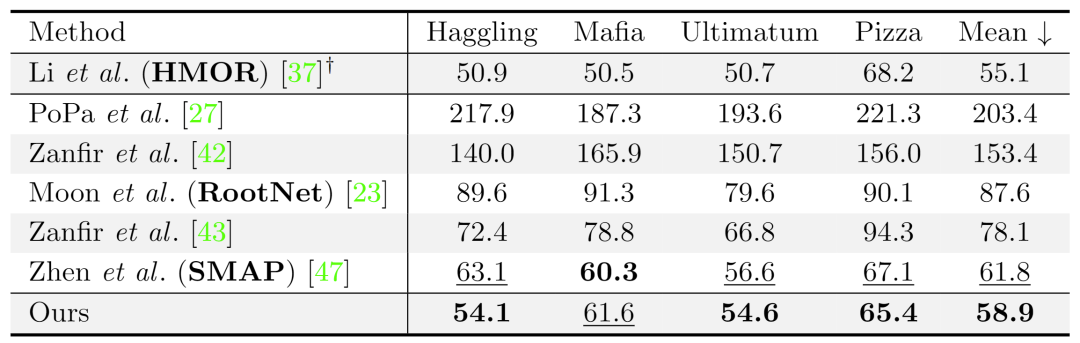
表1. 本工作的方法与现有工作在CMU-Panoptic数据集上的定量误差结果(越小越好)。
表2展示了 MuPoTS-3D 数据集上不同方法的结果,这些方法都只在 MuCo-3DHP 数据集以及 COCO 数据集上训练。本文的方法比其他方法获得了更好的 PCK 准确率,表明 VirtualPose 具有很强的泛化性能,证实了以 AGR 为中间表示并生成大量丰富的 <AGR, Pose>数据进行训练的有效性。
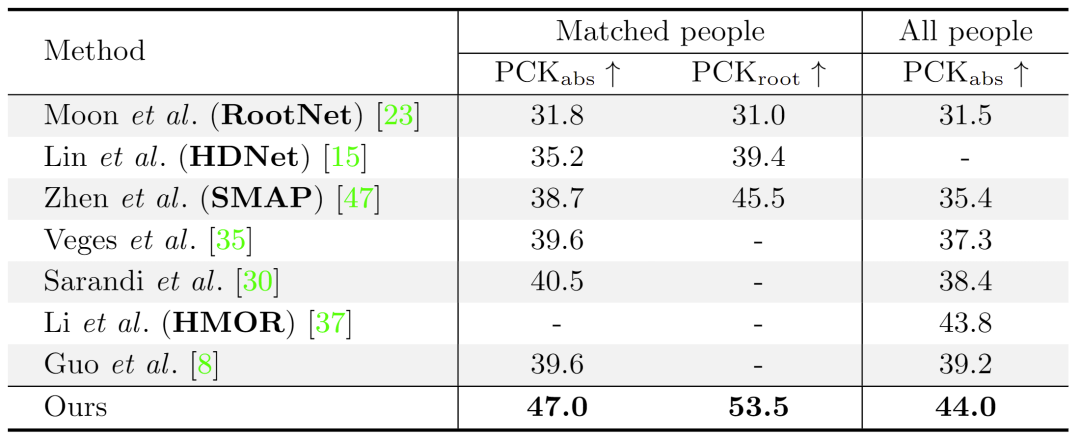
表2. 本工作的方法与现有工作在MuPoTS-3D数据集上的定量结果(越大越好)。
图4为本文的模型在 COCO 和 MuPoTS-3D 数据集上估计的三维姿态,可以看到本工作的方法能准确地估计出每个人的三维姿态以及绝对位置,对图像背景以及人的姿态都十分鲁棒。但在图中的人被遮挡如图4(b),或人体身高与训练数据不一致如图4(c) 的情况下,模型也容易出现错误。

图4. 本工作的方法在COCO以及MuPoTS-3D数据集上的可视化结果。其中 (b) (c) 展示了失败的例子。
05 总 结
本工作进行了对现有基于深度学习的绝对三维人体姿态方法的泛化性能研究,希望此研究能启发之后的工作多探究如何提升人体姿态估计方法的泛化性能。其次,本工作提出了以抽象几何表示为中间表示的方法,通过生成大量丰富的成对 <AGR, Pose> 数据来训练三维人体姿态估计模型。本方法拥有超过现有方法的性能,特别是训练数据和测试数据的场景差别很大的时候,这进一步展现了本方法在自然场景中的泛化性能以及实用性。
参考文献
[1] Tu, Hanyue, Chunyu Wang, and Wenjun Zeng. "Voxelpose: Towards multi-camera 3d human pose estimation in wild environment." European Conference on Computer Vision. Springer, Cham, 2020.
[2] Ma, Xiaoxuan, et al. "Context modeling in 3d human pose estimation: A unified perspective." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[3] Moon, Gyeongsik, Ju Yong Chang, and Kyoung Mu Lee. "Camera distance-aware top-down approach for 3d multi-person pose estimation from a single rgb image." Proceedings of the IEEE/CVF international conference on computer vision. 2019.
[4] Lin, Jiahao, and Gim Hee Lee. "Hdnet: Human depth estimation for multi-person camera-space localization." European Conference on Computer Vision. Springer, Cham, 2020.
[5] Zhen, Jianan, et al. "Smap: Single-shot multi-person absolute 3d pose estimation." European Conference on Computer Vision. Springer, Cham, 2020.