






SIGGRAPH 2022 入选论文解读:用于图像编辑的自条件生成对抗网络
本文是 SIGGRAPH 2022入选论文《Self-Conditioned Generative Adversarial Networks for Image Editing》的解读。该论文由北京大学陈宝权课题组和特拉维夫大学合作,第一作者刘云蛰为北京大学图灵班2018级本科生。文章提出了一种提高生成对抗网络(GANs)在数据分布边缘的生成效果的方法。在此基础上,相关的编辑算法的效果也得到了改进。实验证明,我们的方法成功提高了 StyleGAN 这一广泛认可的人脸生成模型在边缘侧的生成、编辑效果。

论文链接:https://arxiv.org/abs/2202.04040
01 引 言
生成对抗网络(GANs)已经在很多生成相关的任务中取得了卓越的成果。近年来,许多研究人员深入挖掘 GAN 的隐空间性质,由此提出了大量的语义图像编辑方法。然而,在传统的方法中,为了提高对数据分布主体部分的拟合效果,在数据集的分布边缘,GAN 的生成效果会显著下降。因此,以这样的 GAN 的隐空间为基础的编辑方法,在数据边缘的编辑效果较差。例如,许多编辑算法都可以对 StyleGAN 生成的人脸的位姿进行一定程度的编辑,但当我们希望将原图片编辑到边缘位姿时,这些算法的表现就不够理想了。
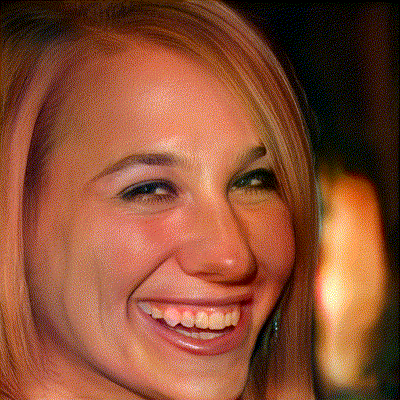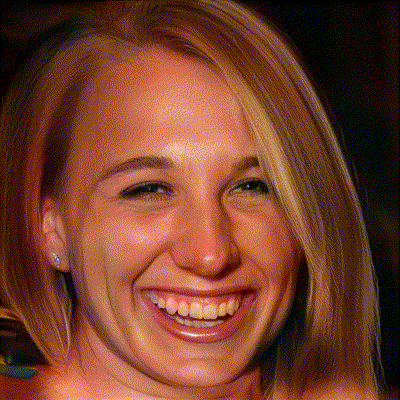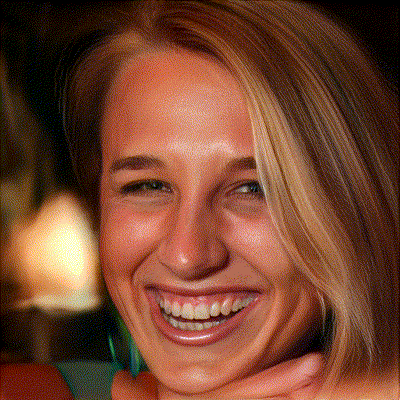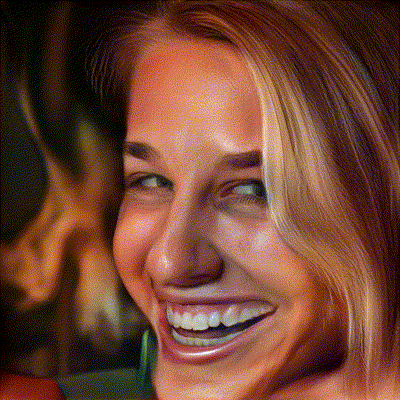

图1. 人脸位姿编辑结果
左:InterFaceGAN,右:Ours
基于此问题,我们提出一种将预训练的 GAN 模型转换为自条件模型(self-conditioned model)的方法,其中条件标签来自于初始 GAN 的隐空间自身。通过基于条件标签的重采样和对条件的显式监督训练,我们提高了边缘数据在原始数据集分布中的权重,迫使网络更加关注边缘数据,从而改进效果。
02 方 法
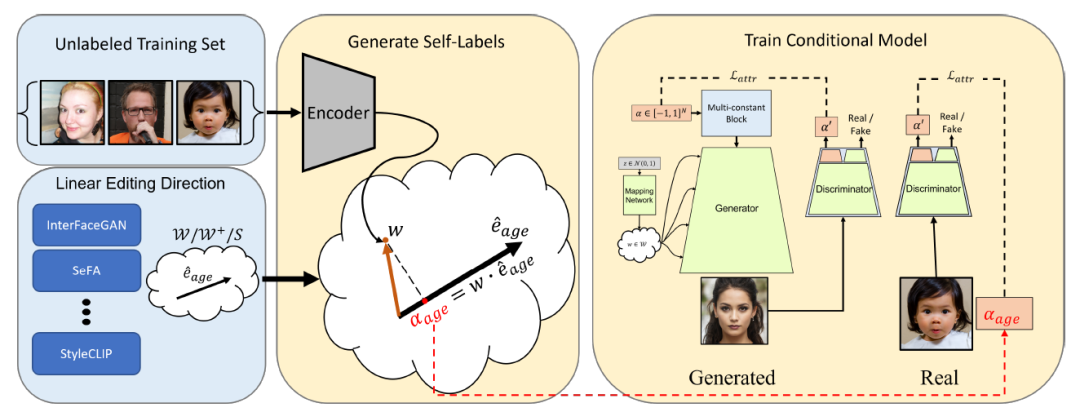
图2. 训练流程图
我们的方法主要分为4步(以年龄编辑为例):
1. 找到预训练的 StyleGAN 的隐空间中,表示年龄的隐向量方向。相关算法种类很多,包括弱监督的 [1]、zero-shot 的 [2] 等等。针对不同的语义编辑,我们采用了不同算法来得到这一隐向量。
2. 将数据集中的所有图像逆映射回隐空间 [3],再将其投影到第1步中得到的隐向量方向上。根据投影长度得到每张图像的属性标签。
3. 在原始 GAN 的结构中加上条件输入,其值代表了年龄属性(数据标签来自第2步),从而这个新的网络结构可以显式控制生成图像的年龄值。
4. 根据第2步得到的标签值进行均匀采样得到新的数据集,从而提升了边缘数据的权重。例如,相比采样前,新数据集中将包含更大比重的老年人。然后开始训练。
在第1、2步中,[4] 提出,图像隐向量在特定隐方向的投影长度和标签真实值有着线性关系,且这一隐方向不拘泥于特定的隐空间。这意味着,我们不需要使用真实标签,只需利用预训练的 StyleGAN 即可近似得到与图像真实属性接近的属性标签。同时,针对不同的属性,我们可以挑选最适合的隐方向提取算法,集众多编辑算法之长。例如,针对位姿这一全局属性,我们采用了方法 [1] 在 W 空间的隐方向;针对戴眼镜这一局部属性,我们采用了 [2] 方法提取的精细程度更高的 S 空间的隐方向。
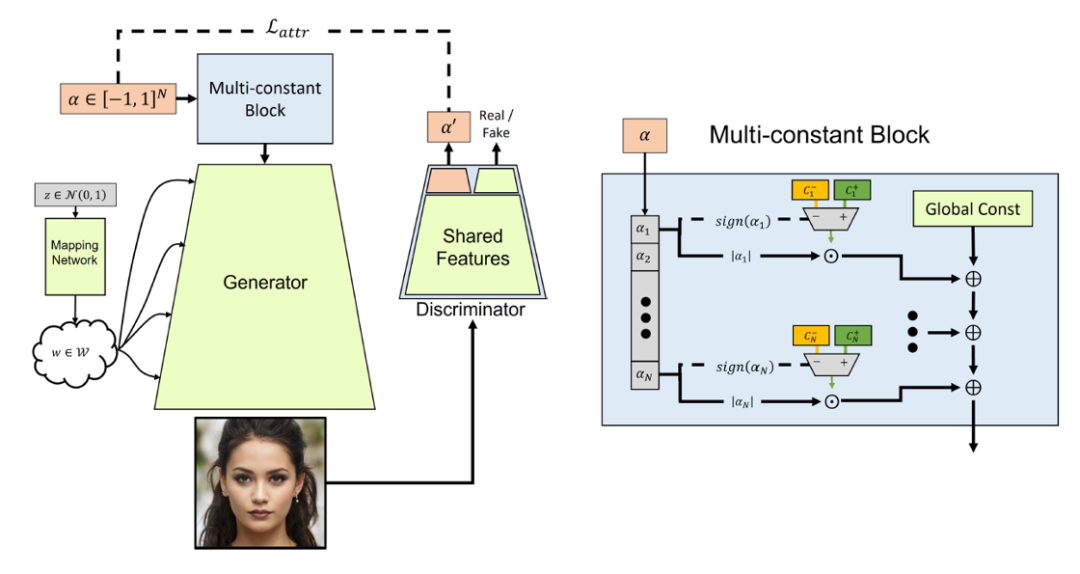
图3. 增加条件输入后的网络结构
在第3步中,我们对网络结构的修改如上图所示,基本结构在 [5] 提出的多常量模型的基础上做了一定的修改。首先,相比于每次从多个常量中选择一个的多选器 MUX 结构,我们转而使用加性的软标签。这赋予我们操纵属性值更大的自由度,避免了在多属性情况下指数级的属性值组合。其次,我们注意到许多属性的两个方向不具有对称性(如年龄)。因此,对于每种属性,我们在两个方向采用不同的常量,而不是仅用一个常量,通过其权值的正负号来表示两个相反的方向。
03 实 验
我们在 FFHQ(人脸)和 AFHQ Cat 两个数据集上的实验结果如下:
定性分析中,我们的算法在边缘数据的编辑结果具有显著的提升。尤其在 AFHQ Cat 数据集的位姿属性编辑中,沿着之前的工作所得到的编辑方向和许多其他属性产生了较明显的耦合。而我们的方法很大程度上保持了猫脸的一致性。

图4. 其他编辑结果
此外,我们提出了一个定量分析编辑结果优劣程度的方法(以年龄为例)。首先,使用 GAN 随机生成大量的结果。接着,使用不同的方法,采用一定范围内的随机步长对这些结果进行编辑。然后,使用预训练的年龄检测模型计算出每个编辑实例的真实编辑程度(如10年、20年)。最后,计算不同编辑程度下人脸 identity 的相似程度,其结果如下图所示:
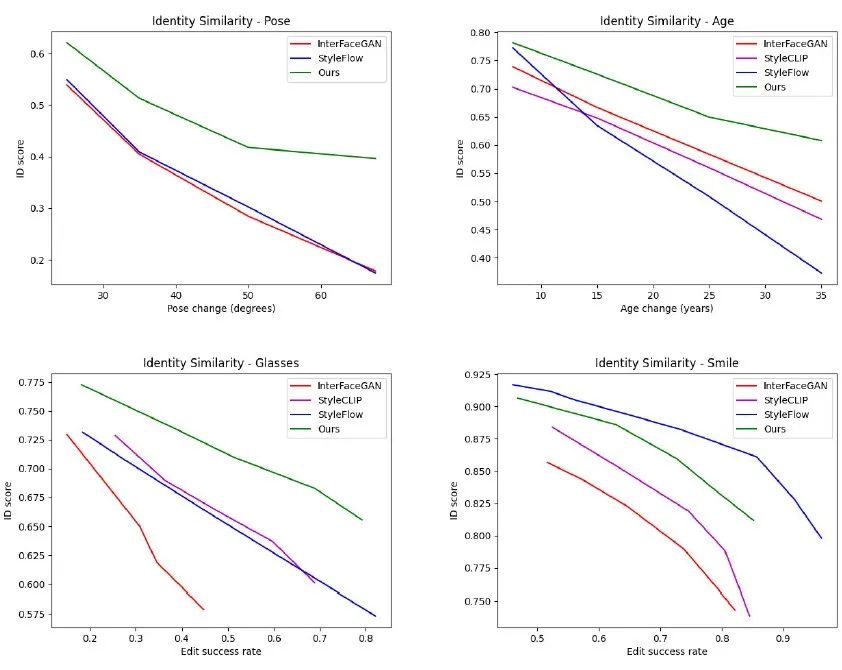
图5. 相似度分析
这说明,我们的算法在大幅度的编辑时,仍能保持较好的效果。
参考文献
[1] Shen, Yujun, et al. "Interpreting the latent space of gans for semantic face editing." CVPR 2020.
[2] Patashnik, Or, et al. "Styleclip: Text-driven manipulation of stylegan imagery." ICCV 2021.
[3] Tov, Omer, et al. "Designing an encoder for stylegan image manipulation." TOG 2021.
[4] Nitzan, Yotam, et al. "LARGE: Latent-Based Regression through GAN Semantics."
[5] Sendik, Omry, Dani Lischinski, and Daniel Cohen-Or. "Unsupervised k-modal styled content generation." TOG 2020.