






程宽课题组 FOCS 2021 入选论文解读:针对Insdel距离的局部可解码编码的下界
近日,北京大学前沿计算研究中心助理教授程宽博士与其合作者的论文“Exponential Lower Bounds for Locally Decodable and Correctable Codes for Insertions and Deletions”发表在理论计算机科学国际顶级会议 FOCS 2021上。这篇文章探讨了编码理论中的一个重要问题,Locally Decodable Code 在 insertion deletion distance 场景下的下界。


编码理论研究的是各种编码的性质及其应用。传统意义上的编码,是指把某个信息空间映射到某个具有特殊性质的度量空间。原空间的每个元素被称之为信息,映射后得到的对象被称之为 codeword。一类最常见的特殊性质是纠错性质,也就是 codewords 之间的距离相对较远,这样的话,当发生在 codeword 上的错误量不超过距离的一半时,就还是可以恢复出正确的 codeword。
Locally Decodable Code (LDC) 是一种特殊的纠错码,它的纠错算法就有局部访问特性,就是在指定任意一个信息比特之后,该算法可以通过仅仅访问“codeword”中的少量比特就能恢复事先指定的任意一个信息比特。
计算下界是理论计算机科学常见的研究目标之一。通俗来讲就是研究给定的计算模型或计算方式解决不了什么样的问题。与之相对的是计算上界,一般的含义就是什么样的问题可以被(有效)解决。具体来说,这篇新工作研究的是什么样参数的 LDC 是不可能存在的。关于这里的参数,之前的研究最关注的一般是冗余度,就是信息长度和编码长度的比例。
该问题针对汉明距离 LDC 的版本已经在过去几十年中被充分研究了,这些研究的主要目标了解想要在大量错误和较少查询的情况下解码,多少冗余度是必要的或足够的。前面给出的冗余度一般是指数级的。这意味着,即使最好的汉明距离 LDC,它的编码长度也必须是信息长度的指数,即冗余度很大。
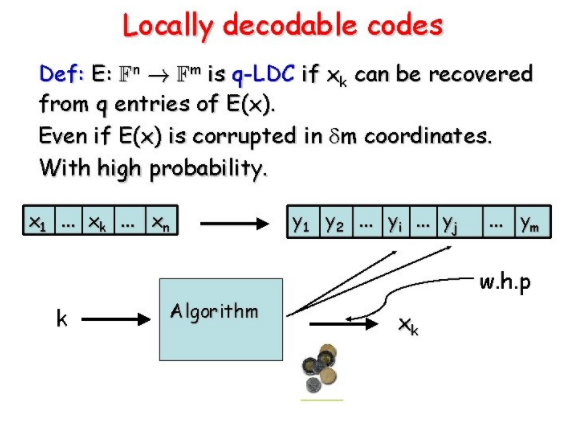
这篇新的工作研究的是针对 insertion deletion (insdel) 的 LDC。Insdel 的含义是指错误类型包括插入字符和删除字符。该研究最初由 Ostrovsky 和 Paskin-Cherniavsky 开始,它们的方法是构建从汉明 LDC 到 Insdel LDC 的归约。而新工作则给出了一个新的证明方法,并且给出了 Insdel LDC 的更强的计算下界。一是 2-query insdel LDC 只能支持常数个信息比特,二是所有 q-query insdel LDC 都有指数级的下界,q 是任意常数。这些下界比针对汉明距离的 LDC 的下界要明显更强。比如 2-query 的情况,新工作的结论意味着,无论如何构造 LDC,不管编码长度设置成多长,哪怕是任何的超越指数这种级别,其信息量也只能是常数个比特。另外简单思考一下不难看出,只含有常数个信息比特的 Insdel LDC 是很容易构造的,大量重复信息比特即可。这也就意味之我们给出的计算下界已经基本匹配了该问题的计算上界,形成了对该问题研究的比较完整的刻画。
新工作在方法上的主要创新是构造了一些精巧的特殊 insdel 分布(如图中所示),并分析了这种分布对 insdel LDC 的影响。

该论文与普渡大学的 Jeremiah Blocki, Elena Grigorescu, Minshen Zhu 以及约翰斯霍普金斯大学的 Xin Li, Yu Zheng 合作完成。该工作得到了北京大学引进人才启动经费和北京大学信息技术高等研究院的经费支持。