






【IJTCS 2020】本科生科研论坛精彩回顾
首届国际理论计算机联合大会(International Joint Conference on Theoretical Computer Science,IJTCS)于2020年8月17日-22日在线上举行,主题为“理论计算机科学领域的最新进展与焦点问题”,由北京大学与中国工业与应用数学学会(CSIAM)、中国计算机学会(CCF)、国际计算机学会中国委员会(ACM China Council)联合主办,北京大学前沿计算研究中心承办。
8月17-21日,大会“本科生科研论坛”如期举行,北京大学陈宏崟主持。小编为大家带来论坛精彩回顾。

Sharp Threshold Results for Computational Complexity
金策,清华大学
讲者首先提到复杂性理论的主要工作在于证明下界。当下人们会证明一些较弱的的下界,例如 De Morgan formula 大小不应远小于 n3;而某些下界很强,人们目前并不会证,例如 。直观上来说,我们想证 De Morgan formula 的 n3.01 下界是比
。直观上来说,我们想证 De Morgan formula 的 n3.01 下界是比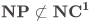 更简单的,因为前一个是多项式的下界,而后一个是超多项式的下界。然而这种直觉可能是错的!近年来的的一系列有关 “Hardness Magnification” 的工作说明很多“弱”下界和“强”下界的证明难度是一样的。而讲者与其合作者的工作即是在这一领域内又给出了更多极端的的“弱”下界难度等同于“强”下界的定理。
更简单的,因为前一个是多项式的下界,而后一个是超多项式的下界。然而这种直觉可能是错的!近年来的的一系列有关 “Hardness Magnification” 的工作说明很多“弱”下界和“强”下界的证明难度是一样的。而讲者与其合作者的工作即是在这一领域内又给出了更多极端的的“弱”下界难度等同于“强”下界的定理。
“Sharp threshold”是指,能首先证明一个形如 nc 的下界,然后证明假如有 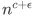 的下界,那么能接着推出一个远远更强的下界。类似的思路也用于了 “Quantified Derandomization” 和 “Explicit Obstruction” 两个不同的问题中。这三个问题的证明的核心工具都为 O(log n) -seed Pseudorandom Restriction。
的下界,那么能接着推出一个远远更强的下界。类似的思路也用于了 “Quantified Derandomization” 和 “Explicit Obstruction” 两个不同的问题中。这三个问题的证明的核心工具都为 O(log n) -seed Pseudorandom Restriction。

Towards Large Scale Multi-agent Reinforcement Learning
周子寒,University of Toronto
许多现实问题均涉及到多智能体的学习。但在将单智能体的训练策略推⼴⾄多智能体时,环境的复杂度可能随智能体的个数指数增⻓,因⽽需要给出⼀种有效的多智能体强化学习策略。朴素的策略是分别训练智能体,将其他智能体的⾏为视为环境的⼀部分,但这时环境变化的概率分布将不再恒定, 会破坏马尔可夫决策过程的假设, 这即 Non-Stationary Agents 问题, 除此之外, 由于计算时将其他智能体的决策视为环境的⼀部分,这样的不稳定因素也会导致训练结果具有较⾼的 variance。后者已经通过 Multi-Agent Deep Deterministic Policy Gradient (MADDPG) 的⽅法解决,但现有⽅法在训练多智能体时时常会因前期训练过程中的混沌(Early Stage Chaos)⽽⽆法完成训练。
本篇⽂章提出了⼀种从少量智能体开始训练,逐步增加智能体数量(每⼀轮智能体数量翻倍)的进化式的训练⽅法 Evolutionary Population Curricum (EPC) 并在Grassland Game,⼀个涉及狼、⽺与⻝物的场景下验证了算法的有效性。
对于模型的泛化,本⽂采⽤了 attention 机制代替了原先池化的⽅法,⽽新增智能体的参数由前⼀轮的结果经遗传算法产⽣,从⽽优化了训练的稳定性,并得到了优于 MADDPG 的结果。
Cake Cutting on Graphs: A Discrete and Bounded Proportional Protocol
资威,中国科学院大学
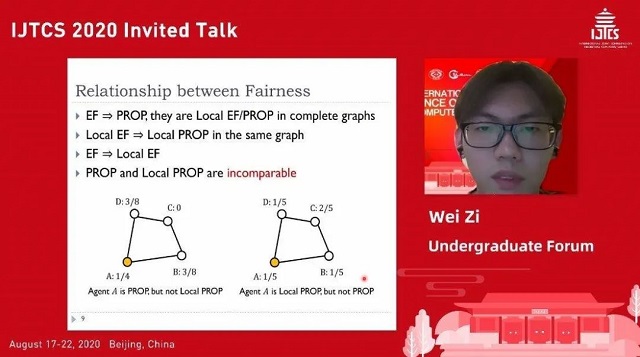
切蛋糕问题是资源分配中的一个重要课题。作者研究了社交图上的切蛋糕问题,该问题可形式化为将 [0,1] 区间划分为不相交的子区间,每个人可分得其中若干区间的情况。问题可要求图上任意相应邻接的人交换所得区间后没有人获得更大收益(local envy-freeness),或者要求每个人分到的收益不少于其与邻接所有人收益的平均值(local proportionality)。现有算法的复杂度特别高,对图亦另有要求,无法满足需要。
作者利用 dominate agent 的概念,在一般图上设计算法,利用之前工作已有的机制,采用两阶段逐步调整法分配资源:首先设法产生第一个 dominate agent,再将其邻接的 agent 变为 dominate,最后每个人均为 dominate agent。提出的算法可求得满足 local proportionality 的分配方案,且算法的复杂性从之前工作的阶乘级别降低到指数级别。
Stability in Committee Selection
姜志豪,清华大学
本篇文章的作者主要研究了委员会选举中的公平性问题。作者首先在经典的委员会选举问题中定义了委员会的稳定性,即如果任何投票者的组合都无法选出一个新的委员会,使得所有人都更偏好于新的委员会,则我们认为原委员会拥有稳定性。该稳定性很好地刻画了选举中公平性的概念。
进一步的,作者将该稳定性定义扩展到委员会概率选举上。委员会概率选举是指允许最终选举出的委员会是多个委员会的概率分布,此时投票者的偏好也将变成期望形式。作者证明了,当投票者的偏好模型为赞成集模型时(即每个投票者的偏好只有对每个委员的赞成或反对),或当偏好是排序模型时,一定存在着拥有稳定性的委员会概率分布。同时,考虑委员会成员拥有权重的情况下,作者进一步提出了近似稳定性的概念,并用概率匹配方法证明当投票者的偏好为单调排序时,一定能选举出常数近似稳定的委员会。

Improved Bounds for the Sunflower Lemma
吴克文,北京大学
太阳花(sunflower)是⼀种常⻅的组合结构,它表⽰若⼲个两两相交均相同的集合。太阳花引理证明了,当我们有⾜够多⼤⼩不超过 w 的集合时,我们必能从中找到太阳花。由于太阳花结构的普遍性,该引理在理论计算机科学的许多领域中均有应⽤。但太阳花引理⾃ 1960 年由 Erdős,Rado 提出以来,尽管经历了诸多改进,对于3-sunflower,太阳花引理中的「⾜够多」⼀直处于 ww 量级。讲者将这⼀下界改进到约 (log w)w,更接近猜想的 O (1)w 。
论文先定义了 robust sunflower 的概念并证明了其与原引理的联系,⽽后通过对坏⼦集的编码和解码过程以及多步约化过程完成了引理的证明。
Private Data Manipulation in Sponsored Search Auctions
林涛,北京大学
讲者首先介绍了搜索广告拍卖(sponsored search auction)场景:搜索引擎作为卖家向买家们拍卖广告位。传统的经济学假设搜索广告拍卖中买家对广告位的估值服从某个分布,这个分布是公开的。
然而在现实中,估值分布是买家的私有信息,不为卖家所知。另一方面,卖家在重复进行的拍卖中可以收集买家的历史出价来学习他们的估值分布。卖家通过历史出价学习分布的做法可能会让买家有动机谎报估值。该工作试图理解买家的谎报会如何影响搜索广告拍卖。
讲者介绍了一个名为“Private Data Manipulation”的模型:卖家在买家的报价分布上运行传统经济学中的最优收益拍卖机制 Myerson's auction,买家策略性地报价以最大化自身效用。讲者等人证明了,在该模型下,Myerson's auction与广义首价拍卖(generalized first-price auction)是等价的。这意味着传统的最优拍卖机制被应用于实际场景时并不能为卖家带来最优的收益,因为其分配和定价方式依赖于估值分布从而会受到买家策略性行为的影响。
该工作还在一定程度上解释了为何 Google Ad Exchange 去年从广义二价拍卖转向了广义首价拍卖。
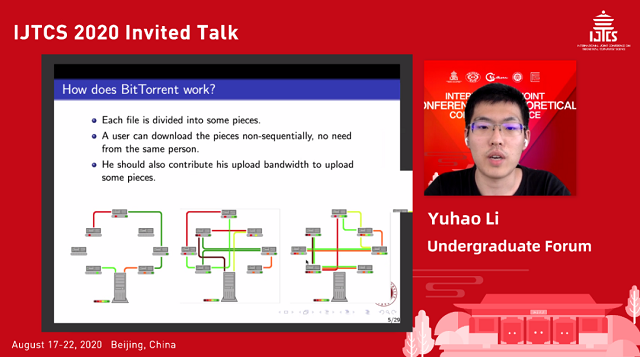
Recent Development for the Incentive Ratio in BitTorrent Resource Sharing Networks
李毓浩,北京大学
p2p 网络为一个用户相互平等的、可以直接交流的网络。在 p2p 网络中,资源在不同的互相连接的用户之间分享。每个用户既是消费者(consumer),也是提供者(supplier)。以协议 BitTorrent 为例,资源就是带宽,存储容量等,节点效用就是其接收到的总资源数,p2p 网络的思想是效用最大化。
通常,带宽资源的模型是一个无向图。在这个图里,每一个顶点 v 代表一个用户,每一个顶点 v 有一个参数 wv ,表示用户拥有的上传带宽的数值;函数  ,表示 v 的邻居节点,以及
,表示 v 的邻居节点,以及 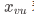 表示 v 节点上传给邻居 u 的资源总数。带宽资源的模型可以被看成一个典型的纯交换经济模型。资源分享最重要的问题是如何公平且有效的分配资源。为了保证公平,节点更倾向于将资源按比例送给那些给自己传输资源的邻居节点,这样的交换是比较公平的,并且可以达到市场均衡。
表示 v 节点上传给邻居 u 的资源总数。带宽资源的模型可以被看成一个典型的纯交换经济模型。资源分享最重要的问题是如何公平且有效的分配资源。为了保证公平,节点更倾向于将资源按比例送给那些给自己传输资源的邻居节点,这样的交换是比较公平的,并且可以达到市场均衡。
当然,在网络中也有欺骗(cheating)的行为与方法。本次报告主要围绕女巫攻击(Sybil attack)这一欺骗手段。在资源分发过程中,一个发动女巫攻击的恶意节点会创造多个节点,成为某个节点的邻居们。而原来传送到多个邻居节点的资源,被传送到了同一个恶意节点。
讲者及其合作者在一个资源共享博弈中,通过令虚拟节点 v 分解为 dv 个虚拟节点,来研究节点 v 发动女巫攻击的激励率(incentive ratio)。这里限制 v 的每个邻居都只连接到一个节点上以简化讨论,使策略 dv 只关注节点之间的权重分配,以获得最优值。
接下来,讲者通过实例以及数学方法,证明了在 bottleneck decomposition 机制下,对女巫攻击的激励率不大于3,以及在环的条件下,针对女巫攻击的激励率恰好为2。

Towards Understanding Optimization of Deep Learning
蔡天乐,北京大学
报告人讲述了他们在神经网络优化领域所做的两个工作。
第一个工作分析了过参数化(overparameterized)神经网络在对抗训练中的收敛性。现有的工作通过考虑初始参数邻域内的优化问题,证明了在监督学习中过参数化神经网络可以通过梯度下降收敛到全局最优解。作者考虑在对抗训练中过参数化神经网络初始参数邻域内的优化问题,分析得出该优化问题可以用一个凸优化问题近似,并且在该邻域内存在一个损失函数接近零的最优点。
在第二个工作中,作者在过参数神经网络的回归问题上,设计了一个二阶优化算法 Gram-Gauss-Newton 方法。相比随机梯度下降,该方法只增加了很小的计算开销,且大大加快了收敛速度。作者通过理论分析证明了该方法在过参数化神经网络的训练上可以达到平方收敛(梯度下降法是线性收敛),并通过实验展示了该方法比随机梯度下降收敛速度更快、模型表现更好。

CycLedger: A Scalable and Secure Parallel Protocol for Distributed Ledger via Sharding
陈炤桦,北京大学
已有的基于分片技术的区块链协议都面临以下的问题:首先,这些协议鲁棒性较差,在某个小组的组长不诚实时,这些协议的效率都会面临巨大的损失;其次,这些协议并不能给出显式的对网络中节点的激励,即,网络中节点没有充足的动机来执行这些协议。本次报告介绍的 CycLedger 机制在保证了已有的最强安全性的前提下解决了第一个问题,并对第二个问题提出了一个已经成型的思路。
CycLedger 引入了组长重选机制。具体而言,在协议的任何时刻,当一个诚实的监察员意识到本组的组长作恶时,他可以将自己的证据在组内进行广播。若这一证据被组内多数人所认可,其就可以将所有同意者的签名上交给中心裁判委员会进行审核。如果通过审核,则当前的组长会被换下,一个新的组长会被选出。
同时,CycLedger 中采用了声誉(reputation)机制,这一机制用来评价网络中每个节点的算力大小以及诚实程度,在分布各个节点的收入时起到重要作用。简单来说,一个节点算力越高,其声誉越高,其获得奖励也就越多。而一个被确定邪恶的节点(被成功检举的组长)的声誉会大幅下降,进而导致其收益降低。
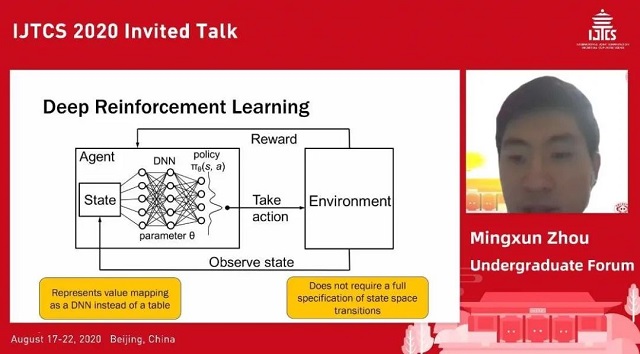
Attack Discovery on Blockchain Incentive Mechanisms with Reinforcement Learning
周铭洵,北京大学
激励机制已经成为区块链系统中重要的基础组成部分之一。激励机制作为对区块链市场规则的一种描述,其目标是使得尽可能多的区块链参与者遵循规则并且保护整个区块链网络。遗憾的是,设计一个良好的激励机制,尤其是在复杂的区块链系统中,是广泛的被认为困难的事情。作者提出了使用深度强化学习来进行区块链激励机制分析的 SquirRL 框架。SquirRL 框架首先将具体的区块链共识机制和激励机制抽象为状态空间、状态转移、奖励机制等要素,将其转换为可供强化学习算法使用的可交互式环境。再利用已有的成熟的深度强化学习算法训练,得到能够最大化收益的行为策略(诚实策略或是攻击策略),使得激励机制设计者能够在大规模部署前得到对机制的一次检验结果。
讲者在本次报告中介绍了几个成果:1)基于中本聪协议,在算力浮动的动态环境中,SquirRL 通过训练得到了最好的攻击策略;2)作者发现了 Rushing Adversary 模型在非完美信息多智能体模型下的不完备性;3)作者通过 SquirRL 框架得到了在多智能体模型下,前人提出的“理论最优自私挖矿(Optimal selfish mining)”策略并不构成纳什均衡;4)作者通过 SquirRL 框架,对以太坊的 Casper FFG 混合激励机制进行了研究,并且得到了一个新的攻击策略,最多使得攻击者能够放大自身收益多达30%。
讲者在报告最后提到,这项研究为之后的区块链共识机制、激励机制设计提供了新的研究方向和研究范式。同时也启发了研究者可以使用强化学习来对计算机安全领域的复杂智能体问题进行研究。