






静5青年讲座回顾:吴旋博士介绍针对受限聚类问题的核心集构造算法框架
2023年2月28日,华为理论计算机实验室的吴旋博士受邀访问北京大学前沿计算研究中心,在静园五院做了题为“A Coreset Framework for Constrained k-Clustering”的报告,介绍了针对受限聚类问题的核心集构造算法的最新研究进展。该报告由中心助理教授姜少峰老师主持。
吴旋博士报告现场(报告视频:https://www.bilibili.com/video/BV1JY411k71g/)
1 受限聚类问题
吴旋博士首先介绍了聚类问题的定义与背景。作为机器学习、数据分析领域的核心问题之一,聚类问题旨在对数据集进行分类,使得“相似”的数据点能够被分在同一类别中。
聚类方法在实践中被广泛应用。而在面对不同的实际场景时,我们所需要的聚类经常受到其他限制,例如限制每个类别包含的数据点数。在本次报告中,吴旋博士介绍了多种在实践中较为常见又研究甚少的受限聚类问题(Constrained Clustering),包括带容量限制的聚类问题(Capacitated Clustering)、公平聚类问题(Fairness Clustering)、鲁棒聚类问题(Robust Clustering)以及容错聚类问题(Fault-Tolerant Clustering)。
2 核心集
核心集(Coresets)是一种数据规约方法,在近些年被学者们广泛研究。吴旋博士介绍了一种能够保持分配代价的核心集(Assignment Preserving Coresets),并说明此类核心集可以高效地生成针对带容量限制的聚类问题以及公平聚类问题的核心集。

关于核心集的构造算法,吴旋博士回顾了两种经典做法:基于移动的算法(Movement-based Approach)以及重要性采样算法(Importance Sampling)。
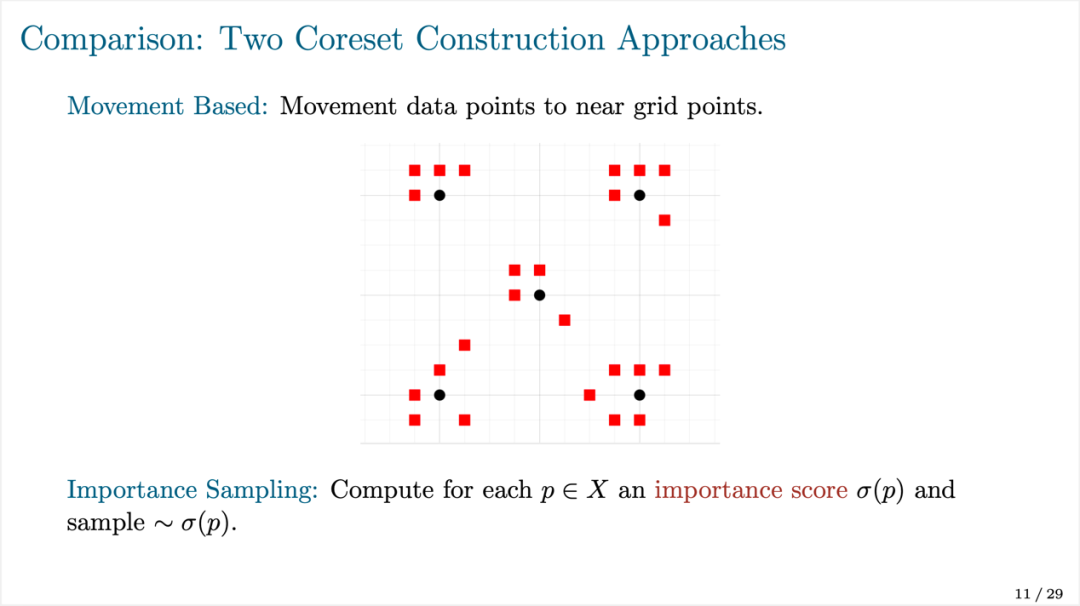
两种算法在精度、分析难度等方面各有千秋,但是都不能直接用于构造针对受限聚类问题的核心集。因此,吴旋博士介绍了另一种将两种算法相结合的框架——Chen's Framework。该框架首先计算一个近似解,将近似解附近的数据点移动到近似解处,剩下的数据点分成大约 O(log n)(n 为数据集大小)个环数据集并利用均匀采样构造核心集。

3 针对受限聚类问题的核心集
受启发于 Chen's Framework,吴旋博士与合作者们针对受限聚类问题展开了一系列研究并均取得了突破性的成果。
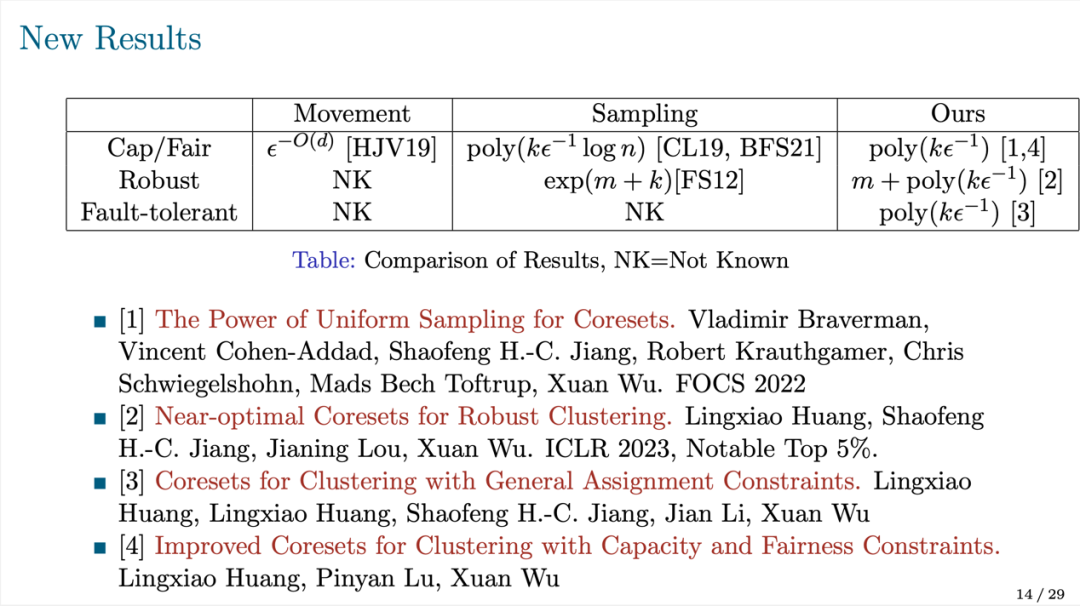
他们的新框架对 Chen's Framework 进行优化。具体来说,他们只在聚类代价较大的“重环”上采用均匀采样;而对于聚类代价小的轻环,他们将其合并成若干群组,并证明只需要用一个简单的“两点核心集”(Two-point Coreset)即可满足精度要求。

关于两点核心集的分析是主要难点以及创新点之一。吴旋博士讲解了关于两点核心集的精度的分析思路。简单来说,他们希望证明两点核心集对于任意聚类中心都能有精度保证,因此吴旋博士进行了分类讨论:若一个聚类中心离一个群组较“远”,则该群组的两点数据集可以保证一个优秀的相对误差;而当聚类中心离一个群组较“近”时,只能保证绝对误差,幸运的是,他们证明了聚类中心只会与有限个群组较“近”,从而保证了总体误差可控。

之后,吴旋博士将他们的框架应用到不同的问题上,如鲁棒聚类问题,以及带有结构限制的聚类问题(Structural Constrained Clustering)等,同样取得了突破性的成果。

除此之外,吴旋博士分享了他们的最新进展:他们通过对该算法框架进行更细致的分析,降低了构造出的核心集大小。
最后,吴旋博士提出了若干开放问题,并与听众进行了讨论。