






静5青年讲座回顾:吴尚哲博士谈如何利用图像或视频学习野外动态3D物体
2022年12月16日,牛津大学的吴尚哲博士带来了题为“Learning Dynamic 3D Objects in the Wild”的报告。报告内容基于其博士论文,包含了一系列相关工作。报告由中心助理教授董豪主持,相关内容通过蔻享学术、Bilibili 同步直播,线上线下数百人观看。
吴博士首先介绍了其研究的背景。人类可以通过观察世界来认识世界,人类是如何学会认识 3D 世界的?如何从一张图片就对他背后的 3D 世界进行理解呢?过去几年,随着深度学习的发展,我们可以完成各种计算机视觉的任务,大部分都是通过人工标注并利用神经网络来进行学习。而 3D 世界的物体包含的信息非常丰富(比如形状,材质,光照,物理参数等等),标注或者捕捉信息的代价极大。

因此,如何利用“In-the-Wild Data”来学习 3D 信息就变得非常重要。
本次讲座,吴博士主要围绕无监督学习(Unsupervised Learning)来学习 3D 物体展开。

吴博士首先介绍了整体方案的架构:即先收集网络上的数据(In-the-Wild Data),并训练 De-render 网络使得将输入的图片“逆渲染”成其对应的 3D 信息,包括几何形状(Shape)、材质(Material)、动作(Motion)、光照(Light)、相机参数(Camera)等。
如何训练 De-render 网络呢?吴博士介绍了 Photo-Geometric Autoencoding 框架:
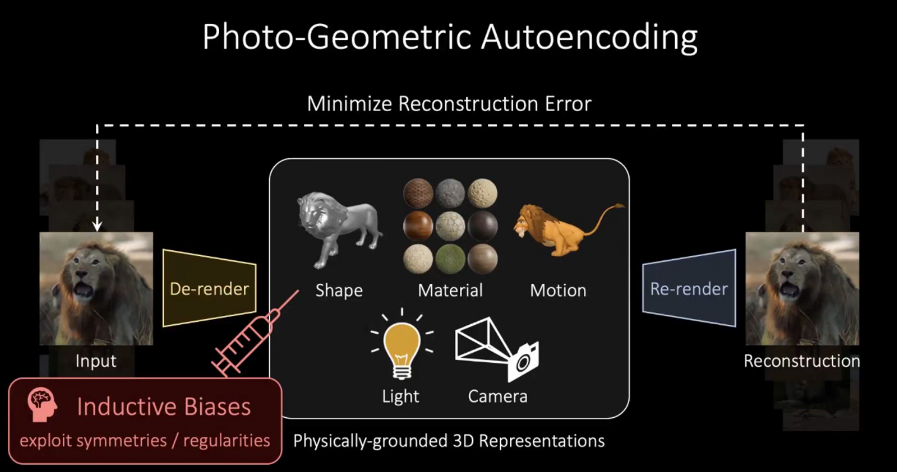
即先利用 Inductive Biases,利用对称性或者一些规律,来限制分解任务,同时借助可微分的渲染器来帮助恢复 De-render 的结果。最后进行重渲染(Re-render),对比前后的渲染结果来计算重建偏差(Reconstruction Error),以最小化该偏差来训练网络。
Unsupervised Learning of Prabably Symmetric Deformable 3D Objects from Images in the Wild

最核心的思想是利用对称性:网络要首先恢复出一个对称的视角,由于物体并不一定是完全对称的,因此网络会输出一个 confidence 来表达非对称的部位并直接作用于 Reconstruction Loss 来减少非对称部位对 loss 的影响。
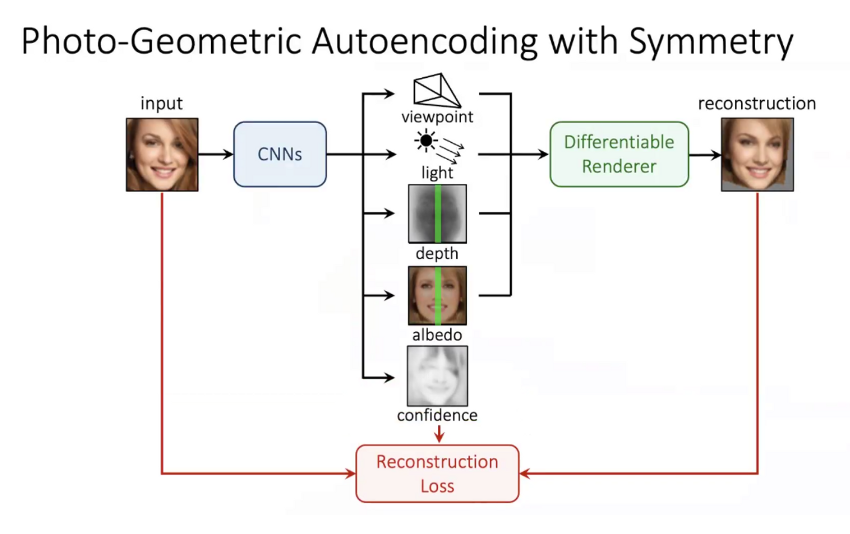
然而之前假设材质是 Lambertian surface,光照是 Ambient+directional light。如何恢复出更复杂的材质和光照非常具有挑战性。

Formulation 仍是类似,只不过这次要恢复出更复杂的材质和光照信息。
训练 pipeline 如下:注意其中使用了一些 trick,比如先找出一个平均颜色的图片(single-color mean albedo)来帮助训练。
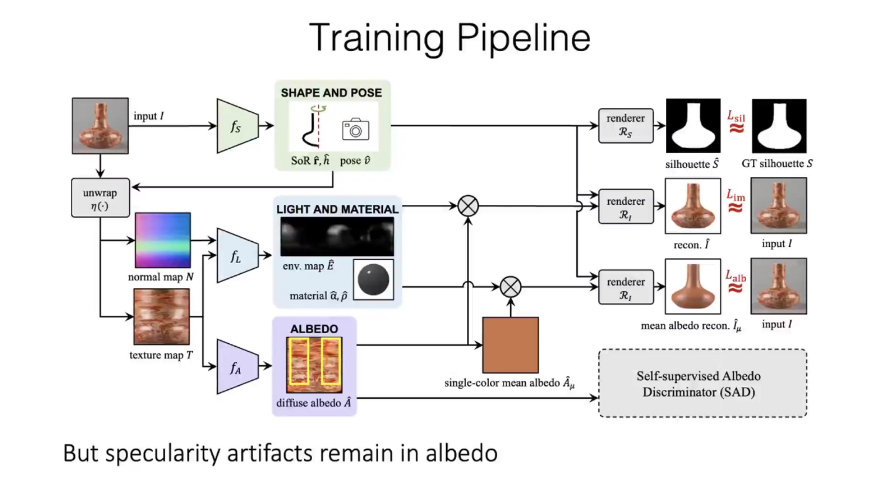
同时,镜面反射会导致一些部位没法通过 2D 来找到原本的颜色,这就直接导致网络恢复出的颜色会和实际不符。因此引入了 SAD(Self-supervised Albedo Discriminator)使得网络可以区分某一个部位是否受到了镜面反射的干扰。
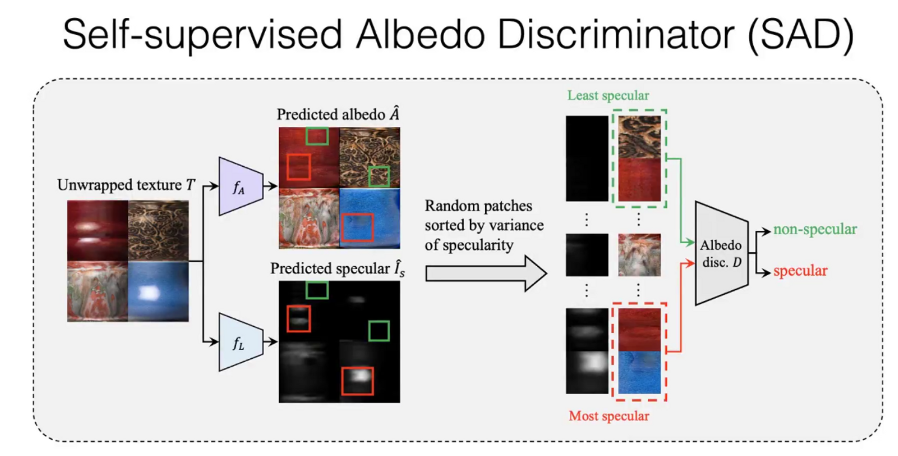
如果最终网络没法区分,那说明恢复出来的图片已经完美地克服了镜面反射带来的影响。
MagicPony:Leaning Articulated 3D Animals in the Wild

这篇工作则是通过图片恢复动态物体的 3D 形状,并通过骨架模型生成动画。

Seeing a Rose in Five Thousand Ways

这篇工作主要是输入一张图片,以玫瑰花束为例,图中包含了很多的玫瑰花(instance),每个玫瑰花包含了不同的几何、颜色、光照等等信息,但是背后共同拥有一个 representation。如何通过一张图片找到这个 representation 并将他们的 3D 信息恢复出来呢?
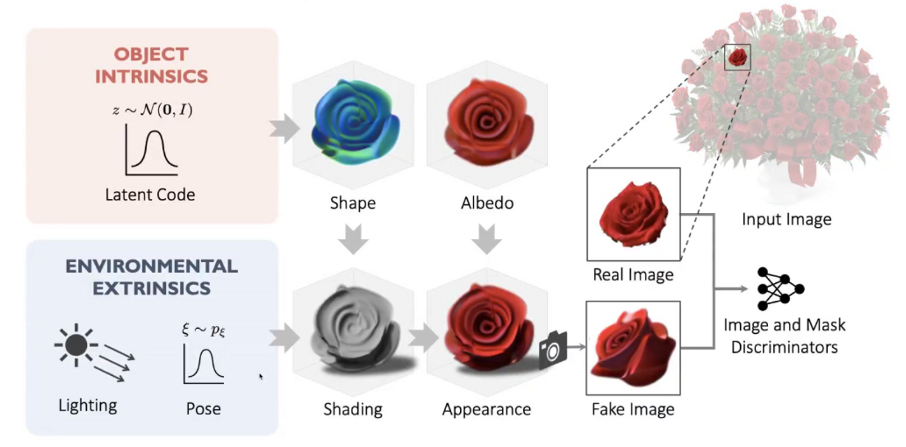
通过从随机 noise 分布中采样,生成 Fake Image 并利用 Discriminator 来学习。